一、论文简述
1. 第一作者:Haofei Xu
2. 发表年份:2022
3. 发表期刊:CVPR oral
4. 关键词:光流、代价体、Transformers、全局匹配、注意力机制
5. 探索动机:过去几年中具有代表性的光流学习框架的核心估计方式没有太大本质区别,即利用卷积从局部相关性中回归光流。这种方式由于其内在的局部性,难以处理光流领域中长期存在的一个挑战:大运动的估计。为了缓解这一问题,当前的代表性框架 RAFT 利用大量的迭代改价来逐步提升光流的预测效果,但这种序列化的处理方式带来了线性的推理时间增长。
6. 工作目标:本文主要要验证这样一个假设:无需大量迭代,同样可以取得很好的光流估计效果,同时速度更快。
7. 核心思想:在本文中,将光流重新定义为一个全局匹配问题,即通过直接比较所有特征之间的相似度来得到稠密对应关系。这种问题定义依赖于较强的特征,为此利用了Transformer来实现。
重新审视了已有的光流估计方法。尽管很多不同的网络结构被提出,但它们没有太大本质区别,即利用卷积从局部相关性中回归光流,并指出了这种方式的局限性;
将光流重新定义为一个全局匹配的问题,彻底改造了主流光流回归管道,能够更好的处理大运动这一挑战。整体框架简洁有效,易于实现;
提出了一个GMFlow框架来实现全局匹配公式,该框架由三个主要部分组成:用于特征增强的Transformer层、用于全局特征匹配的correlation和softmax层以及用于光流传播的self attention层;
进一步提出了一个改进步骤来利用更高分辨率的特性,通过重用相同的GMFlow框架来处残差光流估计;
代码及模型已全部开源,方便复现及做进一步的拓展。
8. 实验结果:一般
GMFlow outperforms 31-refinements RAFT on the challenging Sintel benchmark, while using only one refinement and running faster, suggesting a new paradigm for accurate and efficient flow estimation.
9.论文&代码下载:
https://github.com/haofeixu/gmflow
二、实现过程
1. 背景
近年来,深度学习在许多领域展现出了巨大的潜力,它的快速发展也使得直接从数据中学习光流成为可能。基于深度学习估计光流的开创性工作 FlowNet,设计了一个卷积神经网络架构可以直接将两张视频帧作为输入,并输出稠密的光流。基于学习方法的进一步发展使得光流估计的效果在稳固提升,同时很多不同的光流网络结构被提出。然而,如果我们仔细考量下各种不同的光流网络,可以发现,基本的光流估计方式与最早的 FlowNet 无太大本质区别,即利用卷积从局部相关性中回归光流。

这种方式由于其内在的局部性,难以处理光流领域中长期存在的一个挑战:大运动的估计。为了缓解这一问题,当前的代表性框架 RAFT 利用大量的迭代精细化来逐步提升光流的预测效果。可以用下图来抽象地表达 RAFT 框架:
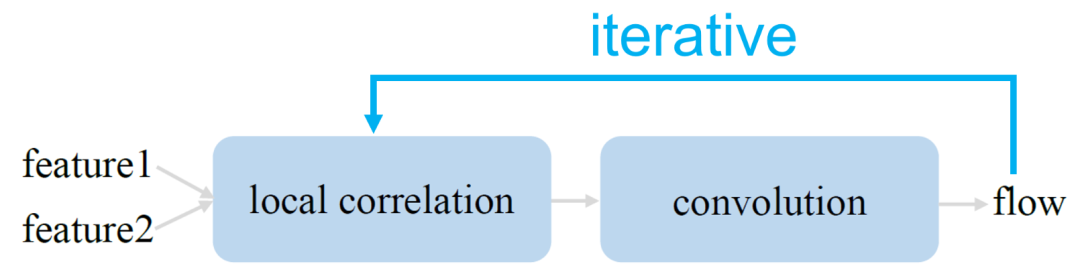
相较之前的算法,RAFT 取得了巨大的性能提升,也由此获得了 ECCV 2020 的最佳论文奖。RAFT 也产生了广泛的影响力,在最近一两年中各种 RAFT 变体层出不穷。然而,尽管这种迭代框架的取得了出色的性能,但由于本质上是一种序列化的处理方式,它也带来了线性的推理时间增长,使其难以做速度上的优化。在本文研究一个问题:RAFT框架是否不可替代?是否有可能高效高精度地估计光流但不依赖于这种大量的迭代精细化?
首先参考下我们人类是如何完成找对应点这一任务的。如下图所示:

假设我们要在第二张图中找第一张图蓝色点的对应点,一般地,我们通常会浏览第二张图中的所有像素点,并比较这些点与蓝色点的相似度,最终将相似度最高的点作为对应点,即黄色点。这一观察启发我们重新审视光流这一任务的本质:光流究竟是一个回归问题还是匹配问题?
光流直观上是一个匹配问题,目的是寻找对应的像素。为了实现这一点,可以比较每个像素的特征相似性,并确定具有最高相似性的对应像素。这样的过程要求特征具有足够的辨别性。将图像本身的空间上下文和来自另一张图像的信息聚合在一起,可以直观地缓解歧义,提高其辨别性。这样的设计理念使得稀疏特征匹配框架取得了巨大的成就。我们还从另外一个相关任务中得到一些启发,即两张图像 (未必是视频帧) 之间的稀疏对应关系,往往用于运动恢复结构和相机位姿估计等应用。这个任务的特点是通常两张图片之间的视角差异较大。我们注意到在主流的稀疏框架中,对应点往往是通过匹配得到的。基于这些观察,我们提出将光流重新定义为一个全局匹配问题,以期能更好地解决大运动这一难题。
2. 方法
给定两个连续的视频帧I1和I2,首先采用权重共享卷积网络提取稠密特征F1,F2∈H×W×D。然后通过全局相关性计算所有点与点之间的相关性,通过矩阵乘法现:

其中相关矩阵C中的每个元素表示F1中p1 = (i,j)和F2中p2=(k,l)的相关值,1/D为归一化因子,避免点积运算后值较大。
要确定对应关系,一种可行的方法是直接取相关性最高的位置。然而,这个操作是不可微的,阻碍了端到端训练。为了解决这个问题,我们使用了一个可微匹配层。具体来说,我们用softmax操作归一化C的最后两个维度,这给了我们一个匹配的概率分布:
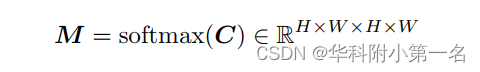
F1中的每个位置相对于F2中的所有位置。然后,将像素网格G的二维坐标加权平均,得到对应的G∈H×W×2与匹配的分布M:

最后,通过计算对应像素坐标的差值就可以得到光流V:
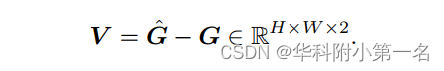
这种基于softmax的方法不仅可以实现端到端训练,而且还可以提供亚像素精度。

3. 特征增强
公式的关键在于获得高质量的判别特征进行匹配。特征F1和F2是从权重共享卷积网络中独立提取的。为了进一步考虑它们的相互依赖性,一个自然的选择是Transformer,特别适合用注意力机制对两个集合之间的相互关系进行建模,如稀疏匹配方法。由于F1和F2只是两组特征,它们没有空间位置的概念,首先将固定的二维正弦和余弦位置编码添加到特征中。加入位置信息后,匹配过程不仅考虑特征的相似性,还考虑特征之间的空间距离,有助于消除模糊,提高性能。
在添加位置信息后,进行了六种叠加的自网络、交叉注意力网络和前馈网络(FFN)来提高初始特征的质量。具体来说,对于自注意力,注意力机制中的查询、键和值是相同的特征。对于交叉注意力,键和值相同但与查询不同,以引入它们的相互依赖关系。这个过程对F1和F2都是对称的,即:

其中T是Transformer,P是位置编码,T的第一个输入是查询,第二个输入是键和值。标准Transformer结构中的一个问题是由于成对注意力操作造成的二次计算复杂度。为了提高效率,采用了Swin Transformer的局部窗口注意力转移策略。然而,与Swin使用固定窗口大小不同的是,将特征分割为固定数量的局部窗口,以使窗口大小与特征大小相适应。具体来说,将大小为H × W的输入特征分割为K × K个窗口(每个窗口大小为H/K×K/W),并在每个局部窗口内分别进行自注意力和交叉注意力。对于每两个连续的局部窗口,我们将窗口分区移动(H/2K,W/2K)来引入跨窗口连接。在框架中,分成2×2个窗口(每个窗口的大小为H/2×W/2),实现了速度和精度权衡。
4. 光流传播
我们所提出的光流估计方式隐式地假设了对应点在两张图片中都可见,因此它们可以通过比较相似性进行匹配。但是,这个假设对于遮挡的和边界外的像素点是无效的。为缓解这一问题,观察到光流和图像本身有一定的结构相似性,进而提出通过特征的自相似性将匹配区域的高质量光流估计结果传播到未匹配区域。这个操作可以通过一个简单的自注意力层实现:

其中

为softmax层的光流预测,是将增强的特征代入softmax匹配层得到的。下图为GMFlow概述。

首先用权重共享卷积网络从两个输入视频帧中提取8×下采样的密集特征。然后将特征输入到Transformer中进行特征增强。接下来,我们通过计算所有对的特征来比较特征相似性,并使用softmax匹配层获得光流。考虑特征自相似性,引入一个额外的自注意力层,将匹配像素的高质量光流预测传播到未匹配像素。
5. 改进
到目前为止提出的框架(基于1/8特征)已经可以实现具有竞争力的性能。通过引入额外的更高分辨率(1/4)特征可以进一步改进。具体来说,首先将之前的1/8光流预测上采样到1/4分辨率,并用当前光流预测形变第二个特征。然后,改进任务被简化为残差光流学习,可以使用上图所示的相同GMFlow框架,但在局部范围内。具体来说,我们在Transformer中分割为8×8个局部窗口(每个窗口的分辨率为原始图像的1/32),并为每个像素执行9×9个局部窗口匹配。在获得softmax层的光流预测后,我们进行3×3局部窗口自注意力操作用于光流传播。
在改进步骤中与全局匹配阶段共享Transformer和自注意力权重,这不仅减少了参数,而且提高了泛化性。生成1/4和1/8的特征,也共享主干特征。具体来说,采用与TridentNet类似的方法,但分别使用步长为1和步长为2的权重共享卷积。这种权重共享设计也比特征金字塔网络具有更好的性能。
6. 训练损失
使用L1损失监督所有光流预测:

其中N是光流预测的数量,包括中间和最终的预测,γ(设置为0.9)是指数级增加的权重。
7. 训练损失
7.1. 数据集
FlyingThings、Sintel、KITTI-2015、HD1K
7.2. 实现
通过PyTorch实现。训练策略延续RAFT。对于GMA,选择通道尺寸Din = Dc = Dm = 128。
7.3. 方法论比较
本文首先将所提出的基于 Transformer 和全局匹配的光流估计方法与之前的基于局部相关性和卷积的方法进行比较。我们堆叠不同数量的卷积残差块或者 Transformer 块来观察性能的变化,结果如下表:

相较之前的方法,本文所提出的框架取得了明显的性能提升,尤其是在大运动 (s40+),验证了方法的有效性。此外,该方法还简化了反向光流的计算:通过直接转置全局相关性矩阵即可,而无需过两次网络。双向光流可以通过前后一致性检验用来检测遮挡。

7.4. 消融实验
为了探究方法有效的原因,对框架中的不同模块进行了对比实验。首先是 Transformer 的各个组件,可以看出,cross-attention 帮助最大,这是因为从 CNN 提取的初始特征中缺乏特征间相互依赖关系的建模,cross-attention 机制可以很好地弥补这一点。Transformer 的其他组件对性能也有帮助。

进一步比较了全局匹配与局部匹配的差异。对大运动 (s40+) 而言,全局匹配比局部匹配具有相当明显的优势,同时可以利用一个简单的矩阵乘法快速计算得到。

7.5. 和RAFT比较
RAFT 进行一个系统级别的比较。GMFlow框架只需一次改进,即可超过RAFT 31次精细化的结果,同时速度更快。

具体数值结果如下表:

还比较了在V100和A100(括号中的数字)上的推理时间。在高端A100 GPU上,由于不需要大量的迭代改进,GMFlow 有更多的速度增益 (2.29x vs.1.87x RAFT),这也说明了GMFlow更加受益于硬件性能的提升,同时未来具有进一步速度优化的潜力。
在Sintel测试集上和之前工作也做了比较,GMFlow同样展现出优异的性能:

参考
https://zhuanlan.zhihu.com/p/532681825![]() https://zhuanlan.zhihu.com/p/532681825
https://zhuanlan.zhihu.com/p/532681825