一、论文简述
1. 第一作者:Shangkun Sun
2. 发表年份:2022
3. 发表期刊:NeurIPS
4. 关键词:光流、代价体、遮挡区域、大核卷积、跳跃连接
5. 探索动机:遮挡问题是光流最大的挑战之一。
现有的解决方案:One of the potential solutions is to utilize the neighbouring pixels to recover motions of the occluded regions, such as learning the neighbouring relationship by CNNs, or interpolating the hidden motions via smoothness terms in Markov Random Fields. However, both convolution and interpolation are restricted to the local information within the small operation window, which only focus on learning the local evidence. As occlusions get worse, those local evidence would be insufficient to recover the hidden motion and thus severely degrade the performance. Recent works propose to model long-range dependencies between local descriptors via non-local methods to make up the missing local evidence. These methods alleviate the issue to some extent, but still tend to fail since the representative capabilities of local descriptors have been largely weakened when facing severe occlusions.
6. 工作目标:应用大核卷积来估计被遮挡的运动。
Motivated by that larger kernels present an effective way compared to deeper layers for larger receptive fields, using large kernels in optical flow estimation network is arguably a possible solution to handle the occlusion problem.
7. 核心思想:we propose Super Kernel Flow Network (SKFlow), where we introduce a new architecture design that efficiently utilizes the conical connections and hybrid depth-wise convolutions, and accordingly develop an effective optical flow network to handle the occlusions.
- We introduce the super kernel schemes to opticalflow task for the first time.
- We explore three new architecture designs for super kernel designs in the optical flow network and proposed a new network which we named SKFlow.
8. 实验结果:SOTA
SKFlow is better at resolving the ambiguity caused by severe occlusions and obtains compelling performance on standard benchmarks. Besides, SKFlow attains a good trade-off between accuracy and computation cost. On the challenging Sintel final pass test set, SKFlow ranks 1st among all published methods, improving the GMA by 9.72%, and the increase in MACs is less than 8.42%.
扫描二维码关注公众号,回复: 14761107 查看本文章

不同方法的帧间遮挡和光流误差图。从(a)到(b),刀片的大部分移动到帧外(如像素B1移动到像素B2)。但由于感受野较大,遮挡的B1的运动仍可通过A1的非遮挡运动进行远距离恢复。(c)和(d)分别表示来自正常卷积(例如GMA)和SKFlow方法的预测光流和GT之间的误差。颜色越深,误差越大。SKFlow实现了更低的端点误差(EPE),并且在遮挡状态下表现更好。
9.论文&代码下载:
https://arxiv.org/pdf/2205.14623v2.pdf
https://github.com/littlespray/SKFlow
二、实现过程
1. 超级内核块设计
考虑到以下因素:1. 深层导致优化问题。虽然ResNet在一定程度上解决了深层网络的优化问题,但最近的研究仍然认为它可能表现得像浅层网络,用更深的层获得有限的感受野;2. 有效感受野(ERF)随层数呈亚线性增长,随核大小呈线性增长。因此扩大核尺寸而不是加深层以获得一个大的感受野。
超级核块组件。为了减少由于核尺寸过大而导致的大量计算成本,提出了超级核块,包含三个组成部分:(1)混合深度卷积核,受可分离卷积的启发,首先将一个卷积分割成两个深度卷积。即一个大小为L×L的大深度核和一个大小为S×S的辅助小深度核。在输入形状为N×Cin×H×W的情况下,该混合深度卷积的计算代价为N×Cin×H×W ×(L2+S2)×1。辅助核的设计目的是帮助捕获帧中的小规模模式;(2)残差连接,残差用于(a)合并大核和辅助核;(b)连接深度卷积和点卷积;(3)逐点卷积,在混合深度卷积之后,应用1×1的点卷积,以帮助信息在通道间流动。逐点卷积不改变输入维数,计算代价为:N×Cin×H×W×Cin,输入形状为N×Cin×H×W。
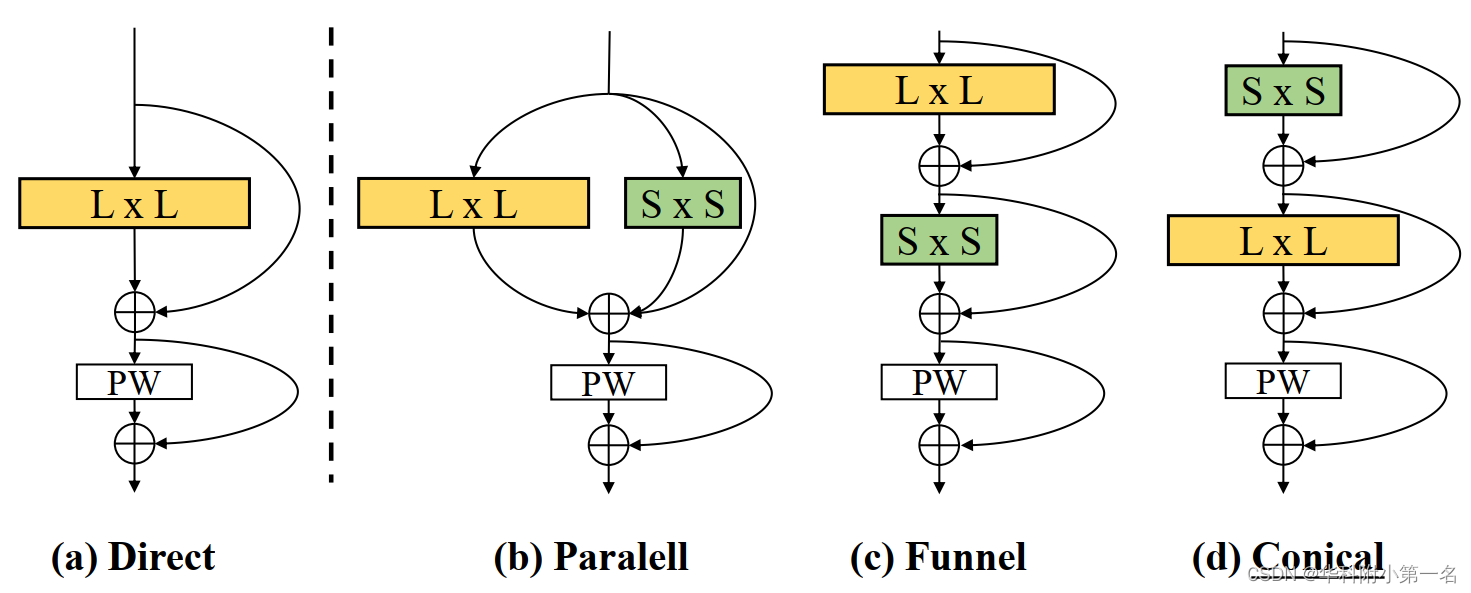
超级核块结构。超级核块共有三种结构设计。如图所示,b, c, d列的设计来自于a列的直接设计,L和S分别表示大的和辅助深度卷积的核大小。PW是逐点卷积。SKFlow模型中使用了划线的设计。其中(1):Parallel(图(b))是在大深度卷积层中采用并行小核的层块。逐点卷积之后是并行运算VGG式与跳跃连接相结合的卷积。(2):Funnel(图2 (c)),是一个ResNet风格的块层,其中核大小从大核L减小到辅助核s。(3):Conical(图2 (c)),类似于漏斗设计,但以相反的顺序应用混合卷积。实验结果表明,这三种大核设计都优于普通小核卷积层,计算量的增加非常有限,其中圆锥块的性能最好,最终的设计采用了锥形块,可以表述为:

其中x和o分别表示输入和输出特征图。ConvdwS×S、ConvdwL×L分别是大核和小核的深度卷积。Convpw1×1是逐点卷积,σ是激活函数。对于每个块,都有一组1×1的卷积层来匹配维度,并增加更多的非线性变换。计算代价为(N×H×W)[D×αCin×(Cin+Cout)],其中D为卷积层深度,α为信道缩放因子。超级核块的总计算代价为N×H×W×Cin×[Cin+L2+S2+αD(Cin+Cout)]。超级核块与普通卷积的计算成本之比为:
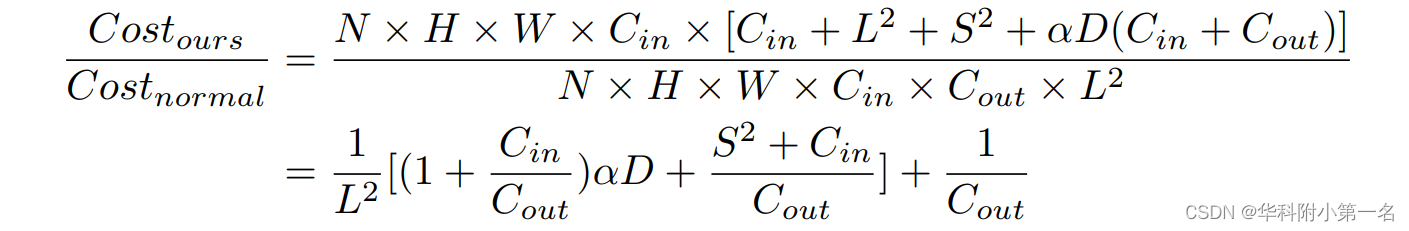
其中α,D,S,Cin和Cout是常数。与普通的大核相比,超级核的计算成本降低到O(1/L2),也实现了令人信服的性能。
2. 超级核光流网络(SKFlow)
除了由超级核块组成的超级核模块,其他与GMA框架相似。
全对相关代价体。全对相关体用于建模所有可能位移的相关性。来自两帧的特征进行点积,然后可以建立不同层级的匹配相关性c,即:
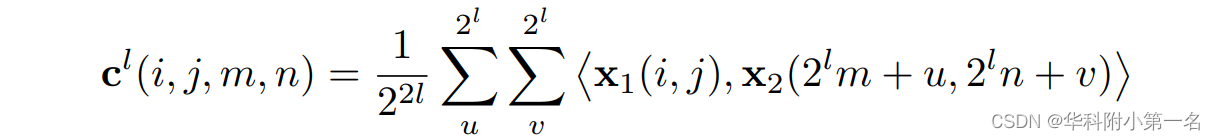
其中x1和x2为从输入帧中提取的特征图,l为相关层级。
全局运动聚合(GMA)模块。GMA模块采用自注意机制对局部描述符之间的远程连接进行建模。延续GMA之后,将该模块应用到光流解码器中。给定高H宽W的输入运动特征x,则输出o定义为:
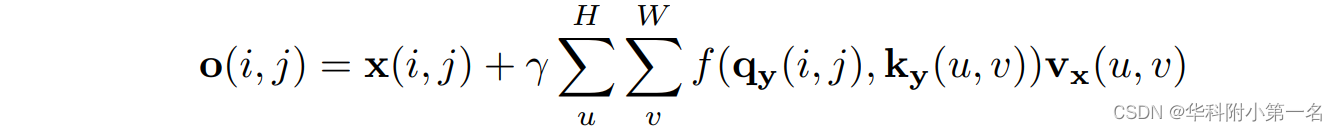
其中qy和ky表示来自上下文特征图的查询和关键向量。Vm是由x导出的值向量,f是点积注意力函数,γ是可学习系数。
超级核模块。超级核模块包括(1)超级核运动编码器,它与GMA具有相似的结构,但应用了超级核块。由代价体向量c和预测光流f得到运动特征,即:

其中SKBlock表示超级核块,Concat是连接操作。(2)超级核更新器。与RAFT和GMA中使用的ConvGRU不同,直接采用超级核块作为更新器,对预测的残差光流∆f进行改进,可表示为:
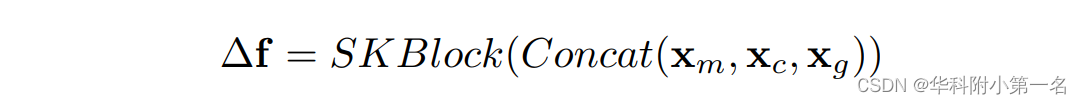
其中xm, xc表示运动特征和上下文特征。xg为GMA模块的全局运动特征。
SKFlow的整个结构如下图所示。值得注意的是,在解码器中应用超级核块只是出于以下考虑:由于其相对较小,应用在解码器中效率更高。考虑到对于大多数库中的大型深度核,像3×3核,缺乏正常的有效执行,使用这两个大的编码器中的超级内核会在推理和训练中花费大量额外的时间。虽然这个问题可能会在未来更快的实现中得到解决,但目前在较小的解码器部分应用超级核会带来适度的时间增加,并实现显著的性能改进。
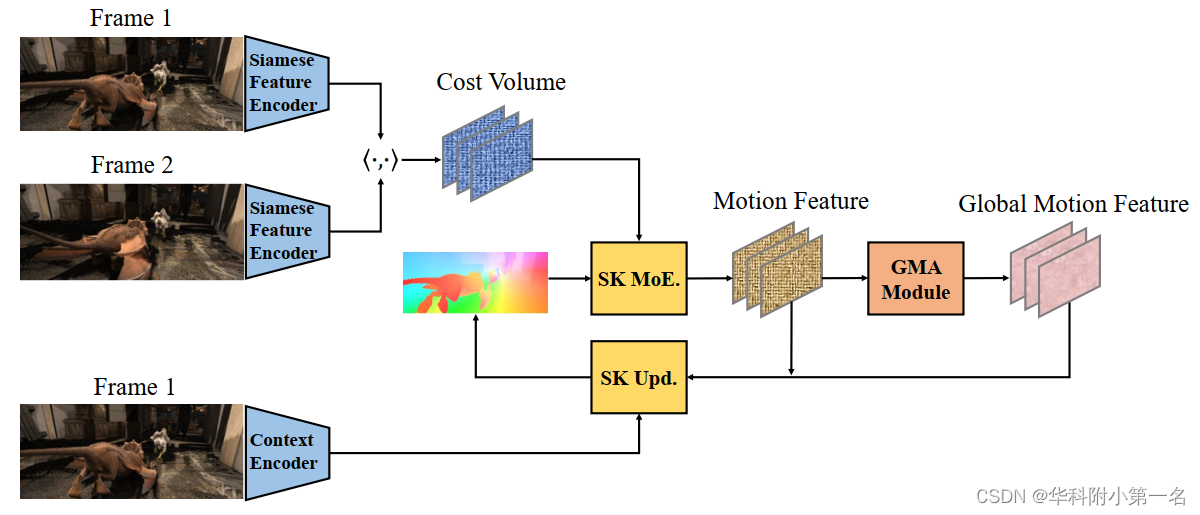
SK MoE.和SK Upd.分别表示超核运动编码器和更新器,GMA是非局部方法。
3. 监督
采用以下损失函数来监督参数更新,对每次改进后预测光流的l1损失进行指数递增系数加权:
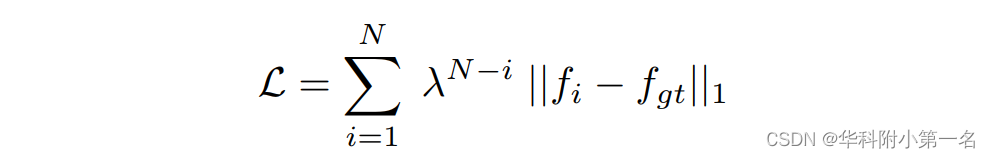
λ表示不同预测光流的权重,在我们的实验中设置为0.8。
4. 实验
4.1. 数据集
FlyingThings、Sintel、KITTI-2015、HD1K
4.2. 实现
通过PyTorch实现,2张Tesla V100 GPUs。
4.3. 基准结果:SOTA
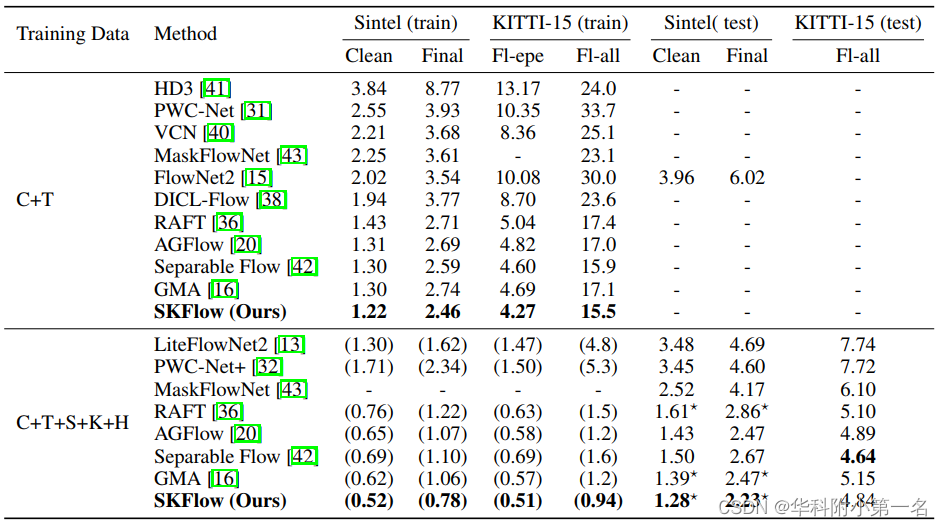
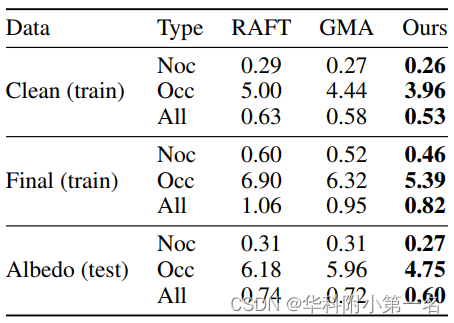
4.4. 遮挡分析
结果如表2所示,其中“Noc”表示未遮挡像素,“Occ”表示被遮挡像素,“All”表示整体像素。大核卷积确实大幅改善了遮挡区域的光流估计。