在第三章里面,并不是一开始就讲的查找,第一节中首先介绍的是 符号表 。
3.1 符号表
符号表,其实就是存储了键值对的一种数据结构,键值对用于将一个键和一个值联系起来。符号表支持两种操作: 插入(put),即将一组新的键值对存入表中;查找(get),即根据给定的键得到对应的值。
下面看一下书中关于符号表的应用以及API
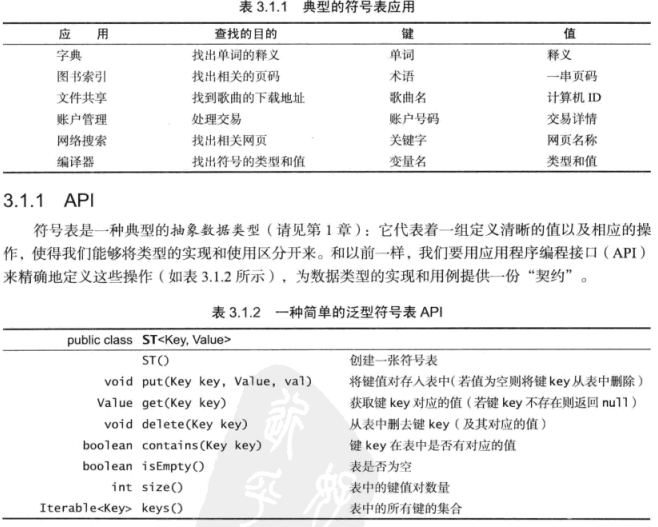
书中对于符号表的要求就不贴了,基本上就是set集合对于元素的要求。
无序链表中的顺序查找
符号表中使用的数据结构的一个简单选择是链表,每个节结点存储一个键值对。get()的实现即为遍历链表,用equals()方法比较需要被查找的键和每个结点中的键,匹配成功就返回相应的值,否则返回null。
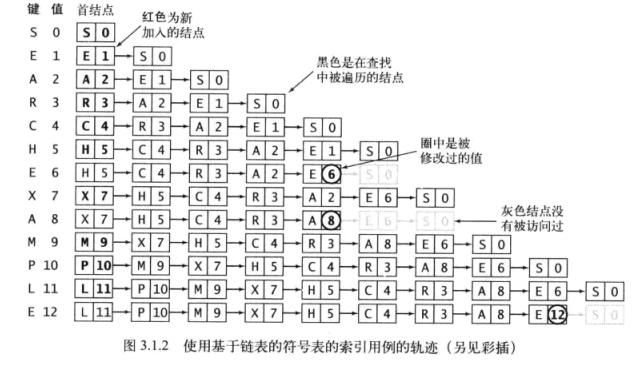
算法3.1 (基于无序链表)
public class SequentialSearchST<Key, Value>
{
private Node first;
private class Node
{
Key key;
Value val;
Node next;
public Node(Key key, Value val, Node next)
{
this.key = key;
this.val = val;
this.next = next;
}
}
public Value get(Key key) {
for(Node x = first; x != null; x = x.next)
if(key.equals(x.key))
return x.val;
return null;
}
public void put(Key key, Value val) {
for(Node x = first; x != null; x = x.next)
if(key.equals(x.key))
{ x.val = val; return; } //命中,更新
first = new Node(key, val, first); //未命中,新建结点
}
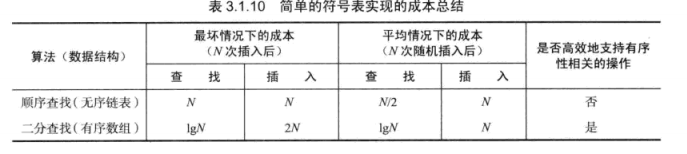
}在上面的符号表中,未命中的查找和插入操作都需要N次比较。命中的查找最坏需要N此比较,向一个空表中插入N个不同的键需要 N^2^/2(另外一种写法N /2)次比较。
有序数组中的二分查找
算法3.2(BinarySearchST)可以保证数组中Comparable类型的键有序,然后使用数组的索引来高效地实现get()和其他操作。
这份实现的核心是rank()方法,它返回表中小于给定键的键的数量。对于get()方法只要给定的键存在于表中,rank()方法就能够精确地告诉我们在哪里能够找到它。
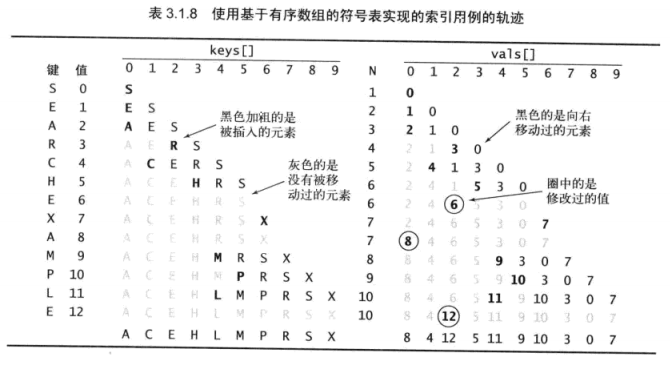
算法3.2 二分查找(基于有序数组)
public class BinarySearchST<Key extends Comparable<Key>, Value>{
private Key[] keys;
private Value[] vals;
private int N;
public BinarySearchST(int capacity) {
keys = (Key[])new Comparable[capacity];
vals = (Value[]) new Object[capacity];
}
public int size() { return N; }
public Value get(Key key) {
if(isEmpty()) return null;
int i = rank(key);
if(i < N && keys[i].compareTo(key) == 0) return vals[i];
else return null;
}
public int rank(Key key) {
int lo = 0, hi = N - 1;
while(lo <= hi) {
int mid = lo + (hi - lo) / 2;
int cmp = key.compareTo(keys[mid]);
if (cmp < 0) hi = mid - 1;
else if (cmp > 0) lo = mid + 1;
else return mid;
}
return lo;
}
public void put(Key key, Value val) {
int i = rank(key);
if(i < N && keys[i].compareTo(key) == 0)
{ vals[i] = val; return; }
for(int j = N; j > i; j--)
{ keys[j] = keys[j - 1]; vals[j] = vals[j - 1]; }
keys[i] = key; vals[i] = val;
N++;
}
public void delete(Key key) {}//删除操作
}这个二分查找的rank方法使用的不是递归,而是迭代,需要仔细地思考一下。
3.2 二叉查找树
从上面可以知道,二分查找的符号表的插入和查找操作时间复杂度级别相差很大,而二叉查找树可以保证查找和插入操作都是对数级别的。
算法3.3 二叉查找树的查找和排序方法的实现
public class BST<Key extends Comparable<Key>, Value>{
private Node root; //二叉查找树的根结点
private class Node{
private Key key;
private Value val;
private Node left, right; //指向子树的链接
private int N; //以该结点为根的子树中的结点总数
public Node(Key key, Value val, int N)
{ this.key = key; this.val = val; this.N = N; }
}
public int size()
{ return size(root); }
public int size(Node x) {
if (x == null) return 0;
else return x.N;
}
public Value get(Key key)
{ return get(root, key); }
private Value get(Node x, Key key) {
//在以x为根结点的子树中查找并返回key所对应的值
if(x == null) return null;
int cmp = key.compareTo(x.key);
if (cmp < 0) return get(x.left, key);
else if (cmp > 0) return get(x.right, key);
else return x.val;
}
public void put(Key key, Value val)
{ root = put(root, key, val); }
private Node put(Node x, Key key, Value val) {
if (x == null) return new Node(key, val, 1);
int cmp = key.compareTo(x.key);
if (cmp < 0) x.left = put(x.left, key, val);
else if (cmp > 0) x.right = put(x.right, key, val);
else x.val = val;
x.N = size(x.left) + size(x.right) + 1;
return x;
}
算法 3.3 (续) 二叉查找树中max()、min()、floor()、ceiling()方法的实现
public Key min(){
return min(root).key;
}
private Node min(Node x){
if(x.left == null) return x;
return min(x.left);
}
//向下取整
public Key floor(Key key){
Node x = floor(root, key);
if(x == null) return null;
return x.key;
}
private Node floor(Node x, Key key){
if(x == null) return null;
int cmp = key.comparaTo(x.key);
if(cmp == 0) return x;
if(cmp < 0) return floor(x.left, key);
Node t = floor(x.right, key);
if(t != null) return t;
else return x;
}
}
上面方法中每个公有方法都有一个私有方法,它接收一个额外的链接作为参数指向某个节点,通过正文中描述的递归方法查找返回null或者含有指定key的节点Node。max()和ceiling的实现分别与min()和floor()方法基本相同,知识将代码中的left和right(以及>和<)调换了而已
算法 3.3(续) 二叉查找树中select()和rank()方法的实现
rank()是select()的逆方法,它会返回给定键的排名。它的实现和select()类似;
public Key select(int k){
return select(root, k).key;
}
private Node select(Node x, int k) {
//返回排名为k的结点
if (x == null) return null;
int t = size(x.left);
if (t > k) return select(x.left, k);
else if (t < k) return select(x.right, k-t-1);
else return x;
}
public int rank(Key key){
return rank(key, root);
}
private int rank(Key key, Node x) {
//返回以x为根结点的子树中小鱼x.key的键的数量
if (x == null) return 0;
int cmp = key.compareTo(x.key);
if (cmp < 0) return rank(key, x.left);
else if (cmp > 0) return 1 + size(x.left) + rank(key, x.right);
else return size(x.left);
} 算法 3.3(续) 二叉查找树的delete()方法的实现
二叉查找树中最难实现的就是delete()算法,即从符号表中删除一个键值对。
书中是这样去实现delete()算法的

public void deleteMin() {
root = deleteMin(root);
}
private Node deleteMin(Node x) {
if (x.left == null) return x.right;
x.left = deleteMin(x.left);
x.size = size(x.left) + size(x.right) + 1;
return x;
}
public void delete(Key key) {
root = delete(root, key);
}
private Node delete(Node x, Key key) {
if (x == null) return null;
int cmp = key.compareTo(x.key);
if (cmp < 0) x.left = delete(x.left, key);
else if (cmp > 0) x.right = delete(x.right, key);
else {
if (x.right == null) return x.left;
if (x.left == null) return x.right;
Node t = x;
x = min(t.right);
x.right = deleteMin(t.right);
x.left = t.left;
}
x.size = size(x.left) + size(x.right) + 1;
return x;
} 算法 3.3(续) 二叉查找树的范围查找操作
public Iterable<Key> keys() {
return keys(min(), max());
}
public Iterable<Key> keys(Key lo, Key hi) {
Queue<Key> queue = new Queue<Key>();
keys(root, queue, lo, hi);
return queue;
}
private void keys(Node x, Queue<Key> queue, Key lo, Key hi) {
if (x == null) return;
int cmplo = lo.compareTo(x.key);
int cmphi = hi.compareTo(x.key);
if (cmplo < 0) keys(x.left, queue, lo, hi);
if (cmplo <= 0 && cmphi >= 0) queue.enqueue(x.key);
if (cmphi > 0) keys(x.right, queue, lo, hi);
}
上面这些算法一下子看完的话头还是挺晕的。。。