(6)纵横字谜的答案
题目描述:输入一个r行c列(1< r <10 ,1 < c < 10)的网格,黑格用“*”表示,每个白格都填有一个字母。如果一个白格的左边相邻位置或者上边相邻位置没有白格(可能是黑格,也有可能是越出网格边界),则称这个白格是一个起始格。首先把所有起始格按照从上到下,从左到右的顺序编号为1,2,3……
接下来找出所有横向单词(Across)。这些单词必须从一个起始格开始,向右延伸到一个黑格左边或者网格的最右列。再找出所有纵向单词(Down)。这些单词必须从一个起始格开始,向下延伸到一个黑格的上边或者整个网格的最下行。
输入:第一行是行和列,接下来的几行是网格内容,有多轮输入,以数字0结束
输出:首行是字谜的轮数(puzzle #1:, puzzle #2:等),字符”Across”后一行为横向输出的单词,字符“down”后一行为纵向输出的单词,输出单词前需要输出该单词第一个字母的编号,且字母标号从小到大排序
Sample Input
2 2
AT
*O
6 7
AIM*DEN
*ME*ONE
UPON*TO
SO*ERIN
*SA*OR*
IES*DEA
0
Sample Output
puzzle #1:
Across
1.AT
3.O
Down
1.A
2.TO
puzzle #2:
Across
1.AIM
4.DEN
7.ME
8.ONE
9.UPON
11.TO
12.SO
13.ERIN
15.SA
17.OR
18.IES
19.DEA
Down
1.A
2.IMPOSE
3.MEO
4.DO
5.ENTIRE
6.NEON
9.US
10.NE
14.ROD
16.AS
18.I
20.A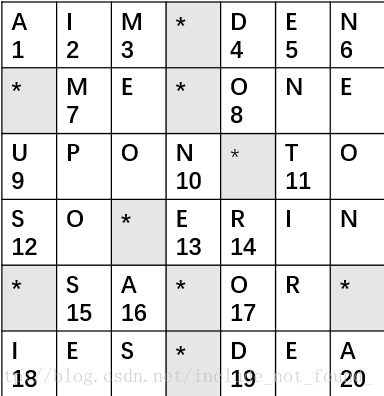
以给定的第二个输入输出为样例,如图,每一个小方格上方的字母代表网格的内容,*所在的代表黑格,起始格按照从左到右,从上到下的顺序编号
整体思路:声明两个二维数组,一个用来储存输入的字符,一个用来储存编号。
除了起始格其他的编号都设为0,方便后面的判断。
横向输出较为简单,对于每一行,从第一个开始向右输出字符,碰到*或者行尾便换行输出,直到行尾为止,由于横向输出编号本身就是从小到大,所以不用担心编号问题

我一开始把纵向输出想的十分复杂,因为纵向输出要求编号从小到大,这个问题困扰了我将近1个多h,中途用了各种办法都失败,但再仔细一读题,由于编号是本身就是从左到右,从上到下排序的,对于每一列只要从第一个开始向下输出,碰到*或者列尾便换行,换到下一列行首开始输出,这样就自然是按照编号从小到大输出的了,具体的实现方法见代码
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
char Puz[11][11];
int num[11][11]; //num用来记录对应位置的编号
int main(){
int a,b,turn=0; //a:行数,b列数,turn游戏轮数
while(cin>>a&&a){
int number=0; //number代表编号
memset(num,0,sizeof(num));
cin>>b;
for(int i=0;i<a;i++)
for(int j=0;j<b;j++){
cin>>Puz[i][j];
if((!i||!j||Puz[i][j-1]=='*'||Puz[i-1][j]=='*')&&Puz[i][j]!='*') //只有当左边或者上边是边界或*时才有编号
num[i][j]=++number;
}
if(turn>0)printf("\n");
printf("puzzle #%d:\nAcross\n",++turn);
for(int i=0;i<a;i++){ //开始横向输出
for(int j=0;j<b;j++){
if(num[i][j]){
printf("%3d.",num[i][j]);
while(j<b&&Puz[i][j]!='*')
printf("%c",Puz[i][j++]);
printf("\n"); //到行尾或者遇到*需换行输出
}
}
}
printf("Down\n"); //开始纵向输出
for(int i=0;i<a;++i)
for(int j=0;j<b;++j){
//num=0判断是否已输出过
if(num[i][j] == 0 || Puz[i][j]=='*') continue;
printf("%3d.%c",num[i][j],Puz[i][j]);
num[i][j]=0; //输出过的编号重置为0
int k=i+1; //遇到*或列尾换下一列输出
while(k<a&&Puz[k][j]!='*'){
printf("%c",Puz[k][j]);
num[k][j]=0;
k++;
}
printf("\n");
}
}
return 0;
}此题着实有些烧脑,将近写了4个多h才解决,自己真的是才疏学浅呐。
(7)DNA序列
题目描述:输入T组数据,每一组为m(4<=m<=50,4<=n<=1000)个长度为n的DNA序列(只有A,G,C,T四种字符),对于每一组数据,输出每一列出现次数最多的字符以及每一列其他字符数量的总和,若有出现次数相等的,则取字典序小的那个(字典序:按A,B,C,D……排序)
Sample Input
3
5 8
TATGATAC
TAAGCTAC
AAAGATCC
TGAGATAC
TAAGATGT
4 10
ACGTACGTAC
CCGTACGTAG
GCGTACGTAT
TCGTACGTAA
6 10
ATGTTACCAT
AAGTTACGAT
AACAAAGCAA
AAGTTACCTT
AAGTTACCAA
TACTTACCAA
Sample Output
TAAGATAC
7
ACGTACGTAA
6
AAGTTACCAA
12
比较简单的一道题,分别声明一个二维数组和一个一维数组,一个用来输入,一个用来输出结果,对于每一列, 只要统计每一个字符出现的次数,再进行大小对比即可,(进行大小对比时,应该按照A,C,G,T的顺序进行比较,这样次数相等的情况下就不用额外去判断字典序大小了),将出现次数最多的字符存入一维数组对应位置,而其他字符数量自然就是列数减去最多次数
思路
#include<iostream>
#include<cstring>
using namespace std;
char map[55][1005];
char ans[1005]; //输出结果串
int main(){
int T,row,column;
cin>>T;
while(T--){
cin>>row>>column;
int sum=0;
for(int i=0;i<row;i++)
for(int j=0;j<column;j++)
cin>>map[i][j];
for(int i=0;i<column;i++){
int a=0,t=0,g=0,c=0;
for(int j=0;j<row;j++){
if(map[j][i]=='A')a++;
if(map[j][i]=='T')t++;
if(map[j][i]=='G')g++;
if(map[j][i]=='C')c++;
}
int max=a;ans[i]='A'; //按ACGT的顺序比较
if(c>max){max=c;ans[i]='C';}
if(g>max){max=g;ans[i]='G';}
if(t>max){max=t;ans[i]='T';}
sum+=row-max;
}
for(int i=0;i<column;i++)
printf(i==column-1?"%c\n":"%c",ans[i]);
printf("%d\n",sum);
}
} (8)循环小数
题目描述:输入整数a,b(0<=a<=3000,1<=b<=3000),输出a/b的循环小数表示以及循环节的长度,循环部分用 ( )加以标识 ,若循环节长度大于50,则右括号前添加…50位后面的忽略
Sample Input
76 25
5 43
1 397
Sample Output
76/25 = 3.04(0)
1 = number of digits in repeating cycle
5/43 = 0.(116279069767441860465)
21 = number of digits in repeating cycle
1/397 = 0.(00251889168765743073047858942065491183879093198992…)
99 = number of digits in repeating cycle
首先我们要知道两个常识:
1.能写成分数的小数一定是有限小数或者无限循环小数,按照题目的要求,有限小数的循环节是0,长度为1
2.float n,m;用n/m方法显然是不行的,float的精度最多为16,显然不满足题目要求
题目的要求。
整体思路:
用最传统的竖式除法思想来解决(就是笔算时那种列竖式作除法的思想)
以5/12为例
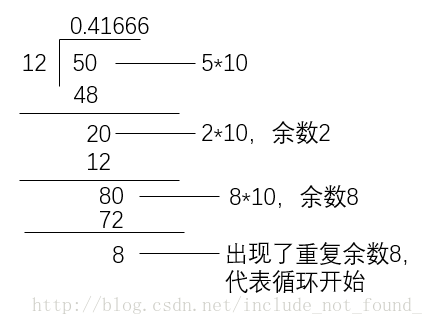
开一个数组,用数组来储存结果,整数部分单独列出,从小数部分开始判断,当当前余数与之前的某一位余数相等的时候便代表循环开始,在该位置和第一个循环节的地方加以标记,这两个位置之间的便是循环节内容,再对这个位置判断是否在小数点后50位,分情况输出即可
/*Repeating Decimals*/
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int ans[5000]; //储存answer结果
int rem[5000]; //储存remainder余数
int main(){
unsigned short m,n; //输入的正整数不会超过3000
while(cin>>m>>n){
int t=m,begin,count=0,judge=1; //begin:循环节起始的地方
memset(ans,0,sizeof(ans));
memset(rem,0,sizeof(rem));
ans[0]=t/n; //ans[0]存储整数部分
rem[0]=t%=n;
while(judge){
t*=10;
ans[++count]=t/n; //商
rem[count]=t%=n; //余数
for(int i=0;i<count;i++){
if(t==rem[i]){begin=i;judge=0;break;} //余数相等时说明开始循环
}
}
printf("%d/%d = %d.",m,n,ans[0]);
for(int i=1;i<=begin;i++)printf("%d",ans[i]);
printf("(");
for(int i=begin+1;i<=count&&i<=50;i++)printf("%d",ans[i]);//只输出<=50位
if(count>50)printf("...");
printf(")\n");
printf(" %d = number of digits in repeating cycle\n\n",count-begin);
}
return 0;
}(9)子序列
题目描述:输入两个字符串s和t,判断是否可以从t中删除掉0个或者多个字符(其他字符顺序不变)得到字符串s,输入多轮,以EOF结束
Sample Input
sequence subsequence
person compression
VERDI vivaVittorioEmanueleReDiItalia
caseDoesMatter CaseDoesMatter
Sample Output
Yes
No
Yes
No
很简单的一道题,对于t扫描一遍即可,不过需要注意字符串长度问题,之前开小了wrong answer了好几次
tips:大数组声明为全局变量提高效率,原因:局部变量内存在栈上分配的,对于每个进程/线程,栈空间大小有限,全局变量不受栈空间大小影响
#include<iostream>
#include<cstring>
using namespace std;
const int maxn=110000;
char s[maxn],t[maxn];
int main(){
while(cin>>s>>t){
int i=0,flag=0;
for(int count=0;count<strlen(t);count++){
if(t[count]==s[i])i++;
if(i==strlen(s){flag=1;break;} //扫描完毕
}
printf(!flag?"No\n":"Yes\n");
}
}(10)盒子
题目描述:输入六对整数,代表六个面的长宽,判断他们是否能够组成一个长方体。可以的话输出 POSSIBLE ,否则输出 IMPOSSIBLE
Sample Input
1345 2584
2584 683
2584 1345
683 1345
683 1345
2584 683
1234 4567
1234 4567
4567 4321
4322 4567
4321 1234
4321 1234
Sample Output
POSSIBLE
IMPOSSIBLE
思路:对于某一个面,去寻找匹配的面,匹配成功则剔除这两个面,如果三对都
匹配成功,并且对应的边也匹配则可以组成长方体
一开始的思路是声明一个大小为10000的数组,初始化为0,输入时将对应位置的count加一,结束时判断是否每一个不为0的位置都大于4,如果都大于4则代表边是可以匹配的,接下来解决面匹配的问题即可。判断面是否匹配的思路:输入每一组数a,b时,将小的给a(a若比b大,ab交换),再将所有的a从小到大排序,每两个两个就是相对的面,判断长宽是否相等即可
用第一组数据作例子

但是实际操作后发现超时了。。。主要是长度10000的数组大部分数据都是0,浪费了很多内存,所以边匹配的判断还是只能够通过讨论来实现
下面是网上的一种做法,跟我的思路差不多,但是代码层次很清晰也很简洁,可以多加学习一下。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
struct Node
{
int x,y;
}st[10];
bool cmp(Node a,Node b) //sort函数需要调用的排序方式
{
if (a.x==b.x)
return a.y<b.y; //x相等时,y小的在前
return a.x<b.x; //按x从小到大排序
}
int main()
{
int a,b;
while (scanf("%d",&a))
{
int flag=1;
scanf("%d",&b);
if (a>b) swap(a,b);
st[0].x=a,st[0].y=b;
for (int i=1;i<6;i++)
{
scanf("%d%d",&a,&b);
if (a>b) swap(a,b); //把较小的边放在前面
st[i].x=a; st[i].y=b;
}
sort(st,st+6,cmp); //将所有的a从小到大排序
for (int i=0;i<6;i+=2)
//如果每两个相邻的面的x和y不相等一定不满足
if (!(st[i].x==st[i+1].x&&st[i].y==st[i+1].y))
{
flag=0;
break;
}
if (flag)
{
if (st[0].x!=st[2].x) //不同面的最小的两条边不能重合的不满足
flag=0;
if (!((st[0].y==st[4].x&&st[2].y==st[4].y)||(st[0].y==st[4].y&&st[2].y==st[4].x)))//判断第三个面能否与前两个面相接
flag=0;
}
printf(flag?"POSSIBLE\n":"IMPOSSIBLE\n");
}
return 0;
}