前言
本文将会对逻辑回归的基础理解,数学原理,简单算法实现,鸢尾花分类问题实操案例去学习我们的逻辑回归。
一、基本理解
逻辑回归(Logistic Regression)是一种用于分类问题的机器学习算法。它的核心思想是通过对训练数据的拟合来预测未知数据的类别。逻辑回归算法适用于二分类问题,即将数据分为两个类别,比如正类和负类。它的输出是一个介于0和1之间的概率值,可以用于预测样本属于某个类别的概率。
- 问题1 逻辑回归算法是如何把回归看成分类的
- 具体来说,在将回归问题转换为分类问题时,我们通常会将输出变量离散化,也就是将连续的输出变量转换为离散的类别标签。例如,我们可以将预测某人的收入转换为预测该人是否属于高收入阶层,这就是一个二元分类问题。在这个问题中,我们将收入阈值设定为一个固定值,例如5万美元,将高于这个阈值的样本标记为正例,低于这个阈值的样本标记为负例。类似地,我们可以将预测房价的问题转换为预测房屋是否属于高价值区域的二元分类问题,将预测某个病人的病情转换为预测该病人是否患有某种疾病的二元分类问题等。
在逻辑回归当中,我们常用sigmoid函数将线性模型的输出映射到[0,1]的区间上,然后将其解释为概率。其数学公式为
- p(y)=1/(1+exp(-y))
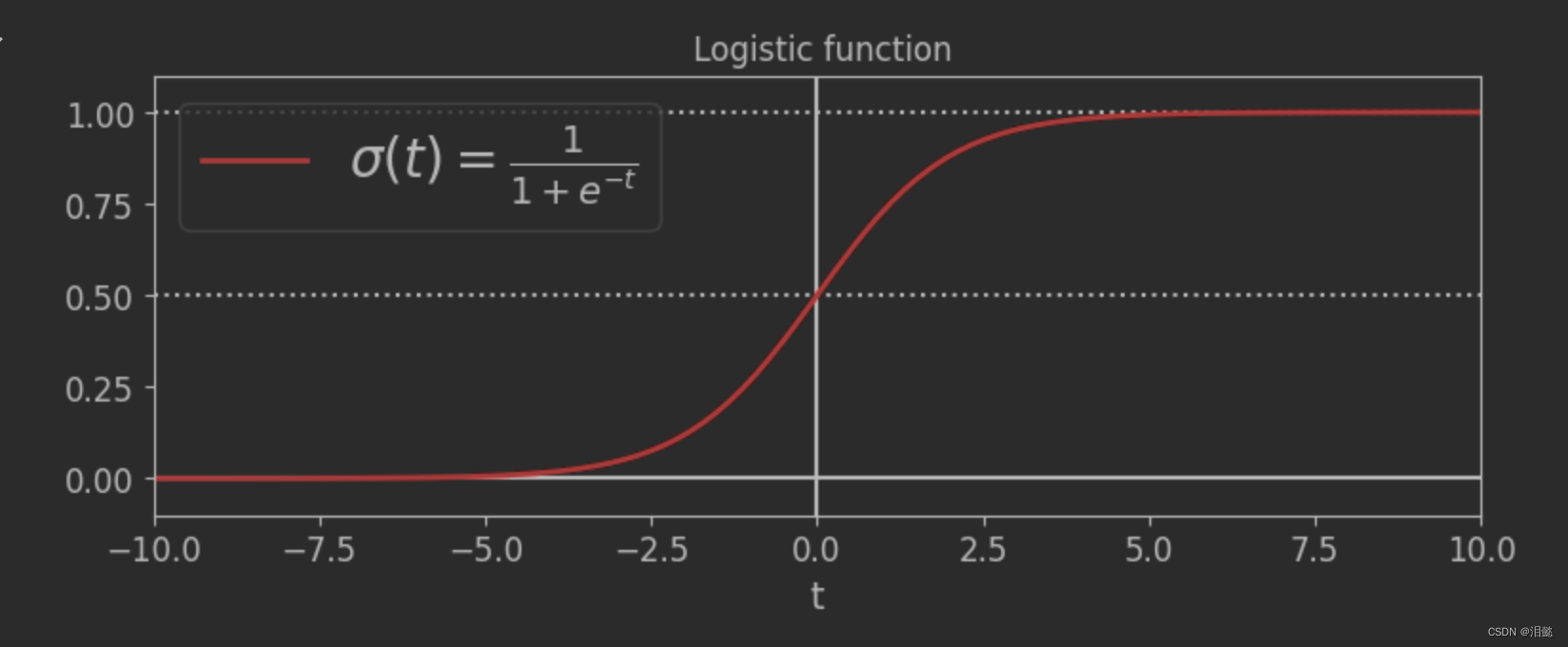
- 自变量取值为任意实数,值域为[0,1],
- 我们把任意的输入映射到了[0,1]的区间得到了我们在线性回归的预测值。
- 总的来书逻辑回归将回归看成分类的基本思想就是将连续的输出变量离散化,然后使用Sigmoid函数将线性模型的输出映射到[0,1]的区间
二、数学原理
- 逻辑回归是基于最大似然估计的方法来求解模型参数的
给定一个数据集
D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) D={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)} D=(x1,y1),(x2,y2),...,(xn,yn)
其中 x i ∈ R d x_i\in R^d xi∈Rd表示第 i i i个样本的特征向量, y i ∈ 0 , 1 y_i\in{0,1} yi∈0,1表示第 i i i个样本的类别
假设我们的逻辑回归模型为
其中 θ ∈ R d + 1 \theta\in R^{d+1} θ∈Rd+1为模型参数向量, g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1为Sigmoid函数, x 0 = 1 x_0=1 x0=1是常数项。
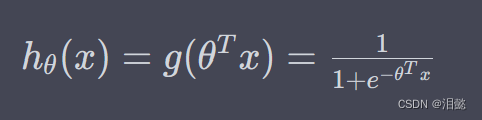
- 对于一个给定的样本 ( x i , y i ) (x_i,y_i) (xi,yi),其对数似然函数为:
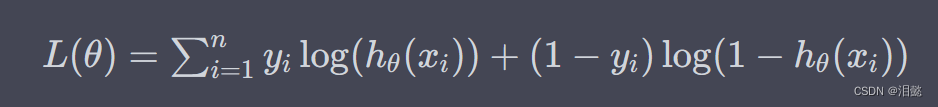
- 最大化对数似然函数等价于最小化其相反数:

-我们可以使用梯度下降法来最小化损失函数 J ( θ ) J(\theta) J(θ),更新参数的公式为:
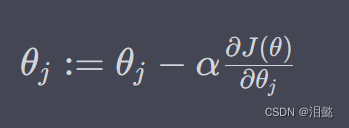
-其中 α \alpha α为学习率, ∂ J ( θ ) ∂ θ j \frac{\partial J(\theta)}{\partial\theta_j} ∂θj∂J(θ)表示损失函数 J ( θ ) J(\theta) J(θ)对参数 θ j \theta_j θj的偏导数,具体计算公式如下:
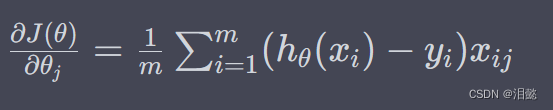
三、简单二元分类算法实现
- 初始化模型
class LogisticRegression:
def __init__(self, learning_rate=0.01, num_iterations=10000):
self.learning_rate = learning_rate
self.num_iterations = num_iterations
self.theta = None
学习率默认为0.01,最大迭代次数默认为10000
- 模型训练
def fit(self, X, y):
m, n = X.shape
X = np.hstack((np.ones((m, 1)), X))
self.theta = np.zeros(n + 1)
for i in range(self.num_iterations):
z = np.dot(X, self.theta)
h = 1 / (1 + np.exp(-z))
gradient = np.dot(X.T, (h - y)) / m
self.theta -= self.learning_rate * gradient
X 是输入特征矩阵,y 是对应的标签向量,m 和 n 分别是样本数量和特征数量。在逻辑回归中,通常在每个样本前加上一个常数项 1,以便与一个学习参数 θ 0 \theta_0 θ0 相乘。接下来,定义参数 θ \theta θ,并将其初始化为全零向量,长度为 n + 1 n+1 n+1,其中 n n n 是特征数量。
然后进行 n u m i t e r a t i o n s num_iterations numiterations 次迭代,每次迭代计算一次梯度下降的更新量,从而更新参数 θ \theta θ。在每次迭代中,首先计算出线性回归模型的预测结果 z = θ T X z = \theta^T X z=θTX,然后使用 sigmoid 函数将其转化为概率 h = g ( z ) = 1 / ( 1 + e − z ) h = g(z) = 1 / (1 + e^{-z}) h=g(z)=1/(1+e−z)。此处使用的是向量化的方式计算预测结果和梯度,其中 np.dot(X.T, (h - y)) 是计算损失函数对参数 θ \theta θ 的偏导数,除以 m m m 可以得到梯度的平均值。最后,根据学习率和梯度大小的乘积来更新参数 θ \theta θ。
- 模型预测
def predict(self, X):
m, n = X.shape
X = np.hstack((np.ones((m, 1)), X))
prob = 1 / (1 + np.exp(-np.dot(X, self.theta)))
y_pred = (prob >= 0.5).astype(int)
return y_pred
根据逻辑回归模型的定义,使用参数 theta 计算出每个样本属于正类的概率值。具体来说,先计算出每个样本的线性回归预测值 z = θ T X z = \theta^T X z=θTX,然后使用 sigmoid 函数将其转化为概率 h = g ( z ) = 1 / ( 1 + e − z ) h = g(z) = 1 / (1 + e^{-z}) h=g(z)=1/(1+e−z)。可以使用向量化的方式一次性计算所有样本的预测概率,即 prob = 1 / (1 + np.exp(-np.dot(X, self.theta)))。
最后,将概率值转化为类别标签。当概率值大于等于 0.5 时,将其判定为正类,否则判定为负类。将 True 和 False 转化为 1 和 0,即可得到二元分类问题的预测结果。这段代码实现了逻辑回归模型对新数据进行分类预测的过程,其核心思想是使用学习到的参数计算新数据点的预测概率,并根据阈值将预测概率转化为类别标签。
-上面的代码不过是为了理解数学算法的实现,我们在实际还是经常用sklearn中的LogisticRegression来实现二元和多元分类。
四、实战案例
- 加载数据集
这里我们加载鸢尾花数据集
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris=load_iris()
iris
鸢尾花有4个特征集,我们实验中将会用到后面两个特征值
- 数据预处理
# 将鸢尾花数据集中的前两个特征提取出来,并将鸢尾花品种标签转换为数字标签
import pandas as pd
X=iris.data[:,2:]
y=pd.Categorical(iris.target).codes
y
iris.target 是 scikit-learn 中自带的鸢尾花数据集的标签,它包含 3 种不同的分类,分别用 0、1、2 表示。但在某些机器学习任务中,我们需要将这些分类转化为数值形式,以便于模型处理。pd.Categorical(iris.target) 可以将 iris.target 转化为 Pandas 中的 Categorical 类型,表示一组有限的离散取值。而 .codes 则可以将 Categorical 类型转化为整数编码。这个操作同样适用于其他模型标签值当中。
- 模型训练
#测试集,训练集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#创建模型
softmax_reg = LogisticRegression(multi_class = 'multinomial',solver='lbfgs')
softmax_reg.fit(X,y)
multi_class 是 LogisticRegression 类的一个参数,用于指定多分类问题的处理方法。它有以下取值:
'ovr':使用一对多方法进行多分类(默认值)。
'multinomial':使用多项式逻辑回归方法进行多分类。
- 当 multi_class=‘ovr’ 时,逻辑回归会对每个类别训练一个二分类模型,然后将最终结果进行组合。这种方法简单易懂,但是可能存在分类不准确的情况。
- 当 multi_class=‘multinomial’ 时,逻辑回归会直接对多分类问题进行建模,通过对所有类别的概率分布进行建模,并选择概率最高的类别作为预测结果。这种方法能够减少分类错误的情况,但是需要更多的计算资源和时间。
- 在默认情况下,multi_class 参数的取值为 ‘auto’,即根据数据集自动选择多分类方法。如果数据集中的类别数目小于等于二,则使用二分类方法;如果类别数目大于二,则默认使用一对多方法进行多分类。
- 需要注意的是,在使用多项式逻辑回归方法进行多分类时,需要将 solver 参数设置为 ‘lbfgs’ 或 ‘newton-cg’,这两种求解器能够处理多类别分类问题。如果 solver 参数设置为其他值,则会出现错误。
-模型精确度
accuracy=modal.score(X_test,y_test)
print('accuracy:',accuracy)
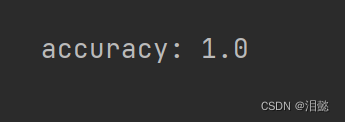
准确率表示模型正确分类的样本数占总样本数的比例。,图中为1,越接近1表示模型越好。
我们也可以直接通过数学算法实现比较容易理解
import numpy as np
y_test_pred=modal.predict(X_test)
accuracy=np.sum((y_test_pred==y_test))/y_test.shape[0]
print('accuracy:',accuracy)
- 绘制散点图
import numpy as np
plt.scatter(X[:,0],X[:,1],c=y,edgecolors='black')#c=y 表示将向量 y 的值作为颜色参数,edgecolor='black'散点图边框颜色
#绘制分类边界
x_min=np.min(X[:,0])
x_max=np.max(X[:,0])
y_min=np.min(X[:,1])
y_max=np.max(X[:,1])
xv,yv=np.meshgrid(np.linspace(x_min,x_max,100),np.linspace(y_min,y_max,100))
Z_=modal.predict(np.c_[xv.ravel(),yv.ravel()])
Z=Z_.reshape(xv.shape)
plt.pcolormesh(xv,yv,Z,cmap=plt.cm.Paired,alpha=0.1)
# 设置图形参数
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.xlim(xv.min(), xv.max())
plt.ylim(yv.min(), yv.max())
plt.xticks(())
plt.yticks(())
# 显示图形
plt.show()
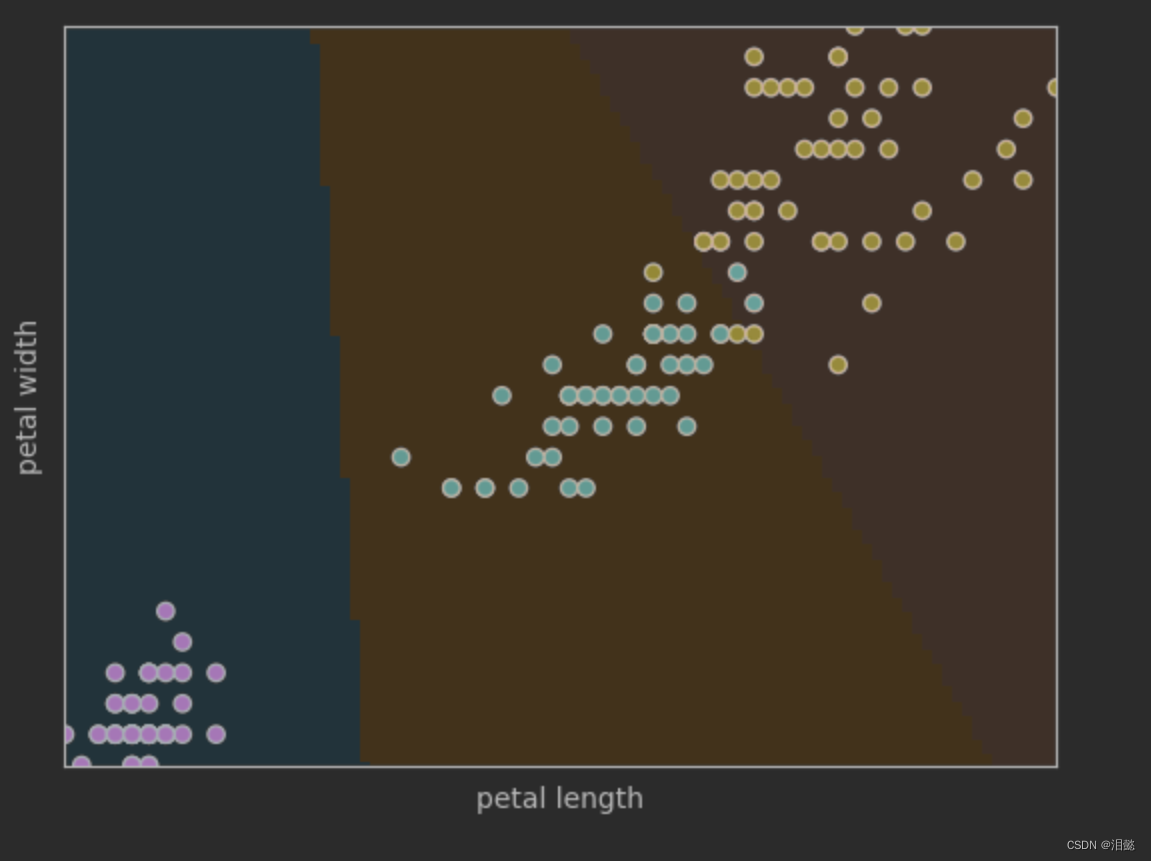
我们绘制了原始数据的散点图,以及我们预测结果的决策分类边界
- 对于其中的难以理解的参数解释
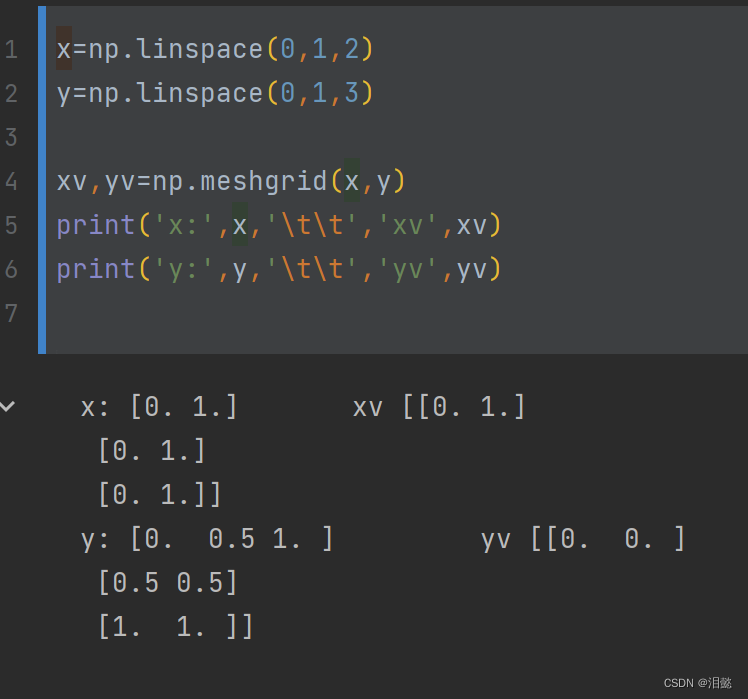
- np.meshgrid()函数用于生成一个网格点矩阵,它的输入是两个一维数组x,y,输出是两个二维数组X,Y,其中X的行向量是x的复制,Y的列向量是y的复制
- xv.ravel()函数将二维数组xv转化成一维数组,ravel()方法将一个多维数组展开成一个一维数组。这个函数通常用于将多维数组展开成一维数组,方便数据处理。上面的数据是多维的,我们将其展开为一维,默认值为0和1,效果一样
- plt.pcolormesh()函数用于绘制二维网格上的颜色块,它的输入是两个二维数组X,Y和一个与X,Y形状相同的二维数组Z。函数将根据Z数组的值绘制颜色块,X,Y数组表示颜色块的位置信息。这个函数通常用于绘制分类边界等二维网格上的颜色块。
总结
逻辑回归是一种二分类算法,主要用于将输入变量映射到离散的输出变量,通常用于分类问题。在本文呢中我们学习了逻辑回归的数学公式和简单算法实现,并使用了Python中的sklearn库对鸢尾花数据集进行了逻辑回归分类的实战案例。以及逻辑回归对于多分类问题的处理方法,并介绍了如何在sklearn库中选择和使用不同的多分类处理方法,包括如何可视化逻辑回归分类结果。
在本文中我只对多分类的案例进行实操,大家可以关注本专栏,或者查看关于逻辑回归的二分类问题案例
【机器学习】模型评估方法介绍与使用上面介绍了逻辑回归的简单的二分类案例,或者想关注梯度下降模型的二分类案例的话也可以关注【机器学习】模型评估-手写数字集模型训练与评估
- 本人能力有限,上述内容如有任何错误,欢迎指正
希望大家多多支持,后续分享更多有趣的东西