From:Jason Brownlee——https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
另一个很好的示例——https://www.cnblogs.com/Belter/p/8831216.html
P.S.The first machine learning project was officially launched at 2020.02.02.
When you are applying machine learning to your own datasets(数据集), you are working on a project.
★A machine learning project may not be linear(线性), but it has a number of well known steps: //众所周知的步骤:
1.Define Problem.
2.Prepare Data.
3.Evaluate Algorithms.
4.Improve Results.
5.Present Results.
没有涵盖机器学习项目中的所有步骤,因为这是您的第一个项目,我们需要关注关键步骤。
★第一次的意义:
真正使用新平台或工具的最佳方法是端到端完成机器学习项目并涵盖关键步骤。即,从加载数据,汇总数据,评估算法和做出一些预测。如果可以这样做,您将拥有一个可以在数据集之后使用的模板。一旦有了更多信心,您就可以填补空白,例如 进一步的数据准备和改善结果任务。
★鸢尾花数据集——https://archive.ics.uci.edu/ml/datasets/Iris
★项目概述——Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)三个种类中的哪一类。
★we are going to cover★
Ⅰ. Loading(加载) the dataset.//导入数据
Ⅱ. Summarizing(汇总) the dataset.//概述数据
Ⅲ. Visualizing(可视化) the dataset.//数据可视化
Ⅳ. Evaluating some algorithms.//评估算法
Ⅴ. Making some predictions.//实施预测
Ⅰ. Loading the dataset
You can download the Iris Data Set from https://archive.ics.uci.edu/ml/datasets/Iris
(Fisher,1936)
数据集包含150个鸢尾花的观测值。花的测量单位有四列,以厘米为单位。第五列是观察到的花的种类。所有观察到的花均属于三种。在此步骤中,我们将从CSV文件URL加载鸢尾花数据。
1.1 导入函数库(使用的所有模块,函数和对象)
# Load libraries
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
1.2 加载数据集
注:我们可以直接从UCI机器学习存储库中加载数据。我们正在使用pandas来加载数据。接下来,我们还将使用pandas通过描述性统计信息和数据可视化来探索数据。
请注意,我们在加载数据时指定每列的名称!这将在以后探索数据时提供帮助。
【从CSV文件URL加载鸢尾花数据!如果存在网络问题,则可以将iris.csv文件下载到您的工作目录中,并使用相同的方法将URL更改为本地文件名来加载它。】
# Load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
数据集应加载而不会发生任何事件。
附加:
在训练模型时,需要用到大量数据,最常见的做法就是利用历史的数据来训练模型。这些数据通常会以CSV的格式来存储(或者能够转化为CSV格式)。在启动ML项目之前,必须先将数据导入到Python中,有三种办法:
①通过标准的Python库导入
②通过NumPy导入
③通过Pandas导入
另一个简单方法(如下代码):直接利用Python中的机器学习包scikit-learn直接导入该数据集!!这个方式可以看到一个很清楚的数据表~
from sklearn.datasets import load_iris
data = load_iris()
print(dir(data)) # 查看data所具有的属性或方法
print(data.DESCR) # 查看数据集的简介
import pandas as pd
#直接读到pandas的数据框中
pd.DataFrame(data=data.data, columns=data.feature_names)
The dataset should load without incident.
Ⅱ. Summarizing the dataset
Now it is time to take a look at the data.
In this step we are going to take a look at the data a few different ways:
(以几种不同的方式看一下数据)
- Dimensions of the dataset. //数据集的尺寸
- Peek at the data itself. //窥视数据本身
- Statistical summary of all attributes. //所有属性的统计摘要
- Breakdown of the data by the class variable. //通过类变量对数据进行分类
每次查看数据都是一个命令,这些命令会在以后的项目中反复使用!
警告 ⚠ 用上述第二种代码载入数据集将不能使用这些功能…试过了…
2.1 查看数据集维度
We can get a quick idea of how many instances (rows) and how many attributes (columns) the data contains with the shape property.【译文:我们可以通过shape属性快速了解数据包含多少个实例(行)和多少个属性(列)。】
# shape
print(dataset.shape)
You should see 150 instances(实例)and 5 attributes(属性):(150,5)
2.2 查看数据
For example:eyeball the first 20 rows of the data——
# head
print(dataset.head(20))
运行后会显示数据集的前20行,简易表格形式!
2.3 Statistical Summary 统计摘要
Now we can take a look at a summary of each attribute.【每个属性的摘要】
包括:计数,平均值,最小值和最大值以及一些百分位数。
# descriptions
print(dataset.describe())
//所有数值都具有相同的标度(厘米),相似的范围介于0到8厘米之间。
2.4 Class Distribution 类分布
现在让我们看一下属于每个类的实例(行)的数量。我们可以将其视为绝对计数。
# class distribution
print(dataset.groupby('class').size())
运行结果:发现每个类具有相同数量的实例(数据集的50或33%)。
Ⅲ. Visualizing the dataset
We now have a basic idea about the data. We need to extend that with some visualizations.
We are going to look at two types of plots(图):
①Univariate plots【单变量图】 to better understand each attribute.
②Multivariate plots【多变量图】 to better understand the relationships between attributes.
3.1 单变量图——更好地理解每个属性
单变量图=每个单独变量的图。
假设输入变量是数字变量,我们可以为每个变量创建箱形图和晶须图。
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
pyplot.show()
This gives us a much clearer idea of the distribution of the input attributes:
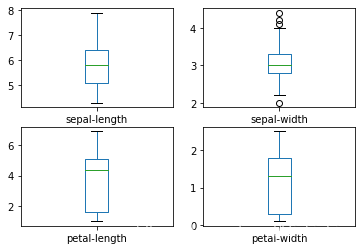
通过这些图,我们对输入属性的分布有了更清晰的认识。
我们还可以为每个输入变量创建一个直方图,以了解分布情况:
# histograms
dataset.hist()
pyplot.show()
运行结果:
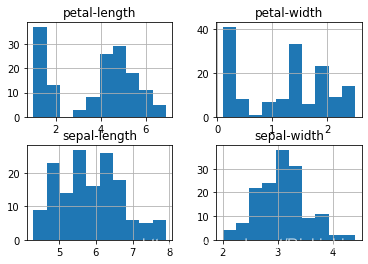
注意:看起来其中两个输入变量具有高斯分布!这一点很有用,因为我们可以使用利用高斯分布假设的算法。
3.2 多元图——更好地了解属性之间的关系
现在来看一下变量之间的相互作用。
首先,观察所有属性对的散点图。这有助于发现输入变量之间的结构化关系。
# scatter plot matrix
scatter_matrix(dataset)
pyplot.show()
运行结果: 鸢尾花数据集的每个输入变量的散点矩阵图
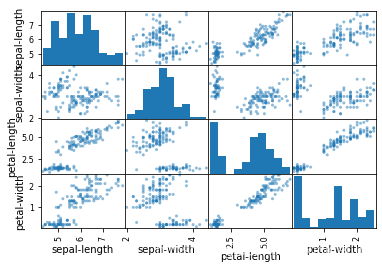
注意一些属性对的对角线分组。这表明高度相关和可预测的关系。
3.3 将数据用图像的形式展示出来
这也是数据可视化的重要部分。帮助我们对数据集有一个直观的整体印象!
e.g.下面利用该数据集4个特征中的后两个,即花瓣的长度和宽度,来展示所有的样本点。
import matplotlib.pyplot as plt
plt.style.use('ggplot')
X = data.data # 只包括样本的特征,150x4
y = data.target # 样本的类型,[0, 1, 2]
features = data.feature_names # 4个特征的名称
targets = data.target_names # 3类鸢尾花的名称,跟y中的3个数字对应
plt.figure(figsize=(10, 4))
plt.plot(X[:, 2][y==0], X[:, 3][y==0], 'bs', label=targets[0])
plt.plot(X[:, 2][y==1], X[:, 3][y==1], 'kx', label=targets[1])
plt.plot(X[:, 2][y==2], X[:, 3][y==2], 'ro', label=targets[2])
plt.xlabel(features[2])
plt.ylabel(features[3])
plt.title('Iris Data Set')
plt.legend()
plt.savefig('Iris Data Set.png', dpi=200)
plt.show()
运行结果:
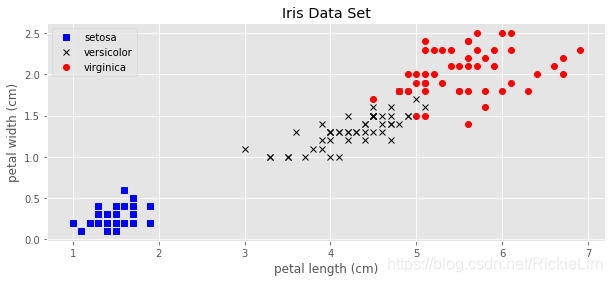
Ⅳ. Evaluating some algorithms
核心:创建一些数据模型并评估它们在看不见数据上的准确性
Here is what we are going to cover in this step:
①分离出验证数据集。
②设置测试工具以使用10倍交叉验证。
③建立多个不同的模型以根据花的测量预测物种
④选择最佳型号。
4.1 先学:为机器学习索引,切片和重塑NumPy数组
点击进入学习链接
(Python;线性代数)
4.2 创建验证数据集
我们需要知道我们创建的模型是好的!
使用统计方法来估计我们在看不见的数据上创建的模型的准确性。我们还希望通过对实际看不见的数据进行评估,从而对看不见的最佳模型的准确性进行更具体的估计。
(具体做法)也就是说,我们将保留一些算法不会看到的数据,并将使用这些数据来获得第二个独立的想法,即最佳模型实际上可能有多精确。
我们将加载的数据集分为两个部分,其中80%将用于训练,评估和选择模型,另外20%将作为验证数据集。
# Split-out validation dataset
array = dataset.values
X = array[:,0:4]
y = array[:,4]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1)
现在,您在X_train和Y_train中具有用于准备模型的训练数据,以及稍后可以使用的X_validation和Y_validation集。
(请注意,我们使用python slice来选择NumPy数组中的列。)
4.3 Test Harness 测试线束
使用分层的10倍交叉验证来估计模型的准确性。
附:「交叉验证」到底如何选择K值?
这会将我们的数据集分成10个部分,在9上训练,在1上测试,然后对训练测试拆分的所有组合重复。
分层是指:数据集的每个折叠或拆分旨在使示例分布与整个训练数据集中相同。
我们通过random_state参数将随机种子设置为固定数字,以确保每种算法都在训练数据集的相同分割上进行评估。
定义:我们使用“ 准确性 ” 指标来评估模型。这是正确预测的实例数除以数据集中的实例总数乘以100得到的百分比(例如,准确度为95%)。
4.4 建立模型
我们不知道哪种算法可以解决此问题或使用哪种配置。从图中我们可以看出,有些类在某些维度上是部分线性可分的,所以我们希望总体上得到好的结果。
★测试6种不同的算法:
//这是简单的线性算法(LR和LDA),非线性算法(KNN,CART,NB和SVM)的很好的结合!
逻辑回归(LR)
线性判别分析(LDA)
K最近邻居(KNN)
分类和回归树(CART)
高斯朴素贝叶斯(NB)
支持向量机(SVM)
★构建和评估我们的模型:
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
结果如下:6个模型的准确性估算
LR: 0.951807 (0.052427)
LDA: 0.976923 (0.035251)
KNN: 0.951807 (0.052427)
CART: 0.953205 (0.061888)
NB: 0.952448 (0.062375)
SVM: 0.984615 (0.030769)
4.5 选择最佳模型
现在,我们有6个模型和每个模型的准确性估算。我们需要将模型进行比较并选择最准确的模型。(请注意,由于学习算法的随机性,结果可能会有所不同。)
在这种情况下,我们可以看到支持向量机(SVM)的估计准确性得分最高,约为0.98或98%!
————————————————————————————————————————
我们还可以创建模型评估结果的图,并比较每个模型的分布和平均准确性。每种算法都有大量的精度度量,因为每种算法都被评估了10次(通过10倍交叉验证)。
比较每种算法的结果样本的方法是为每种分布创建箱形图和晶须图并比较分布。
# Compare Algorithms
pyplot.boxplot(results, labels=names)
pyplot.title('Algorithm Comparison')
pyplot.show()
运行结果: 鸢尾花数据集上的盒须图比较机器学习算法
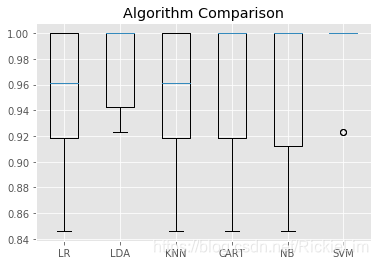
我们可以看到箱形图和晶须图在该范围的顶部被压缩,许多评估达到了100%的准确度,而有些评估则下降到了80%的高准确度。
Ⅴ. Making some predictions
We must choose an algorithm to use to make predictions.
The results in the previous section suggest that the SVM was perhaps the most accurate model. We will use this model as our final model.
现在,我们要对验证集中的模型的准确性有所了解。这将使我们对最佳模型的准确性进行独立的最终检查。注意:保留验证集非常重要,以防万一您在训练过程中滑倒,例如过度适合训练集或数据泄漏。
5.1 做出预测
在整个训练数据集上拟合模型,并在验证数据集上进行预测。
# Make predictions on validation dataset
model = SVC(gamma='auto')
model.fit(X_train, Y_train)
predictions = model.predict(X_validation)
5.2 评估预测
可以通过将预测结果与验证集中的预期结果进行比较来评估预测结果,然后计算分类准确性,以及混淆矩阵和分类报告。
# Evaluate predictions
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
运行结果:
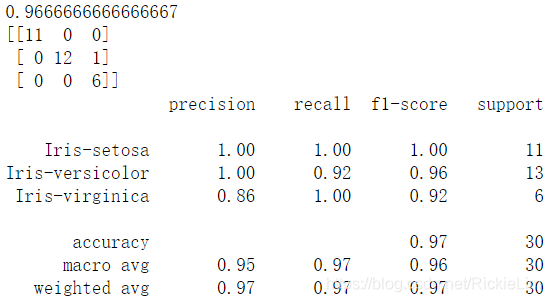
我们可以看到,在保留数据集上,准确性为0.966或大约96.6%。
上图,混淆矩阵提供了三个错误的指示。最后,分类报告按精度,召回率,f1得分和支持分类显示了每个分类,并显示了出色的结果(允许的验证数据集很小)。
