一、获取数据集
用Scikit-Learn自带的鸢尾花数据集。
from sklearn.datasets import load_iris
iris_dataset = load_iris()
二、检查数据
该数据集其实是已经经过多次检验过的经典的数据集,并不需要检查数据这个步骤。但是我们还是按照一般步骤来,假装我们不知道该数据集里是否有异常值和特殊值,此时,就可以将数据可视化。一种可视化的方法是绘制散点图矩阵,数据散点图矩阵将一个特征作为x轴,另一个特征作为y轴,两两查看所有特征。输入以下代码即可绘制散点图矩阵:
%matplotlib inline
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
iris_dataframe = pd.DataFrame(X_train,columns=iris_dataset.feature_names)
grr = pd.scatter_matrix(iris_dataframe,c=y_train,marker='o',figsize=(10,10),hist_kwds={'bins':20},s=60,alpha=0.8,cmap='viridis')
运行结果如下:
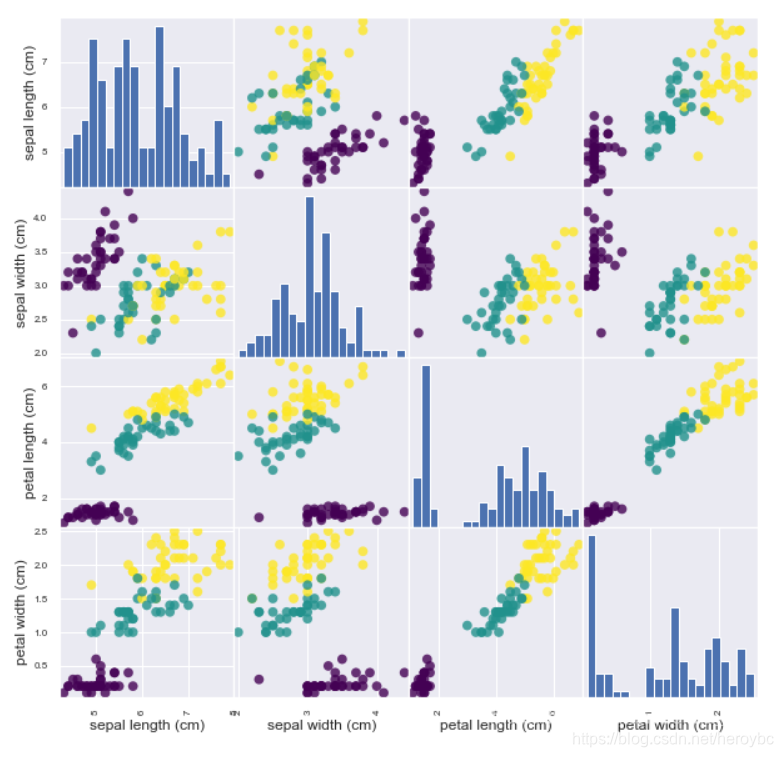
由图可知,利用花瓣和花萼的测量数据基本可以将三个类别区分开,这说明机器学习模型很可能可以学会区分它们。
三、构建训练模型
这里我们选择k近邻分类模型,k近邻算法中k的含义是,我们可以考虑训练集中与新数据点最近的任意k个邻居,而不是只考虑最近的那一个。输入以下代码就可以对数据进行训练了:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
四、进行训练、预测并评估
之前我们已经将数据分为训练集和测试集了,训练集用于模型训练,而测试集用于模型评估,以精度来衡量模型的优劣,即对测试数据中的每朵鸢尾花进行预测,并将预测结果与标签进行对比,计算品种预测正确的花所占的比例。代码如下:
knn.fit(X_train,y_train)
y_pred = knn.predict(X_test)
print('Test set score:\n{}'.format(np.mean(y_pred == y_test)))
结果如下:
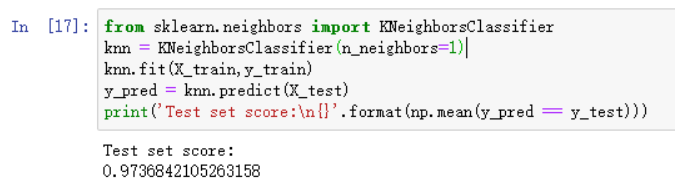
可以看到,精度为97.4%
