机器学习案例实操——鸢尾花
本文做要给大家回归一下Numpy的基础知识,毕竟python 中的sklearn中使用的是这种数据类型。然后用一个鸢尾花分类实例给大家演示机器学习的整个过程,让你快速入门机器学习。
1.Numpy基础知识回顾


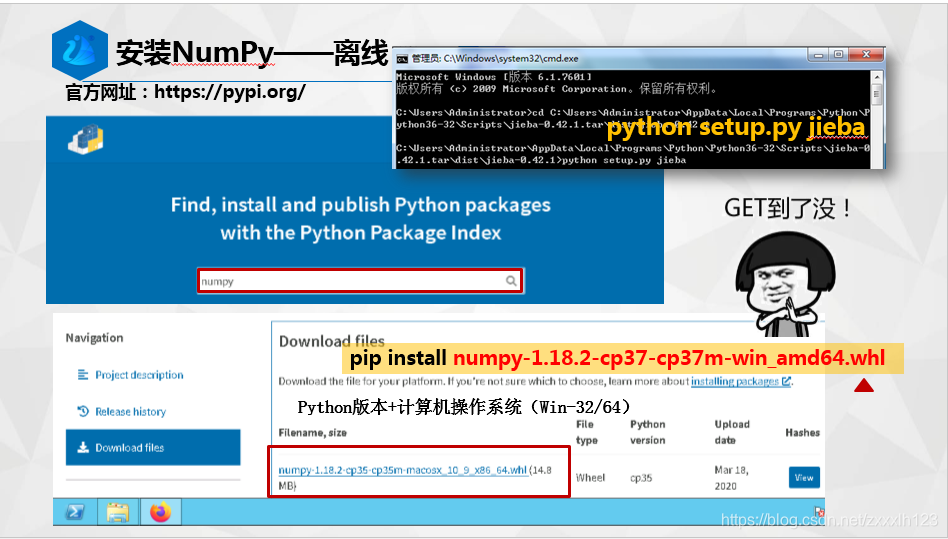


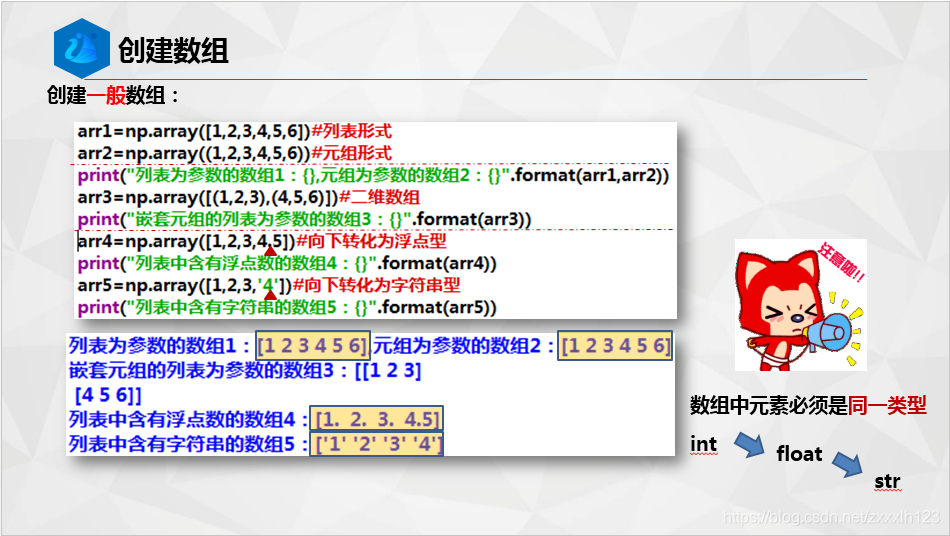

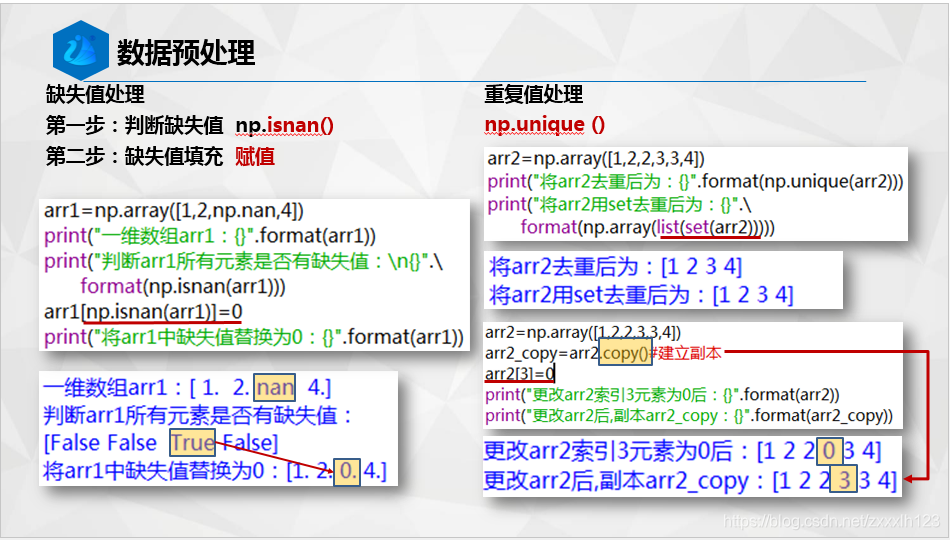
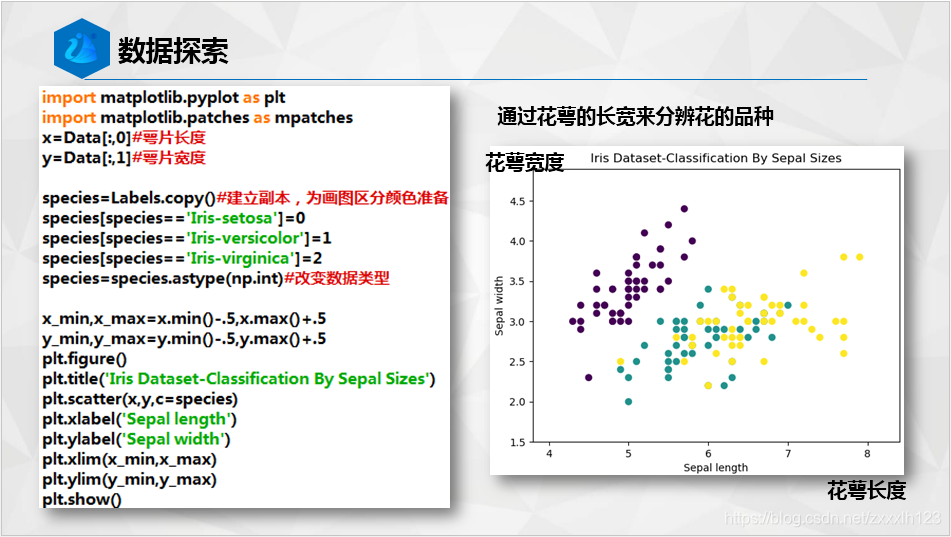
2.辨异识花

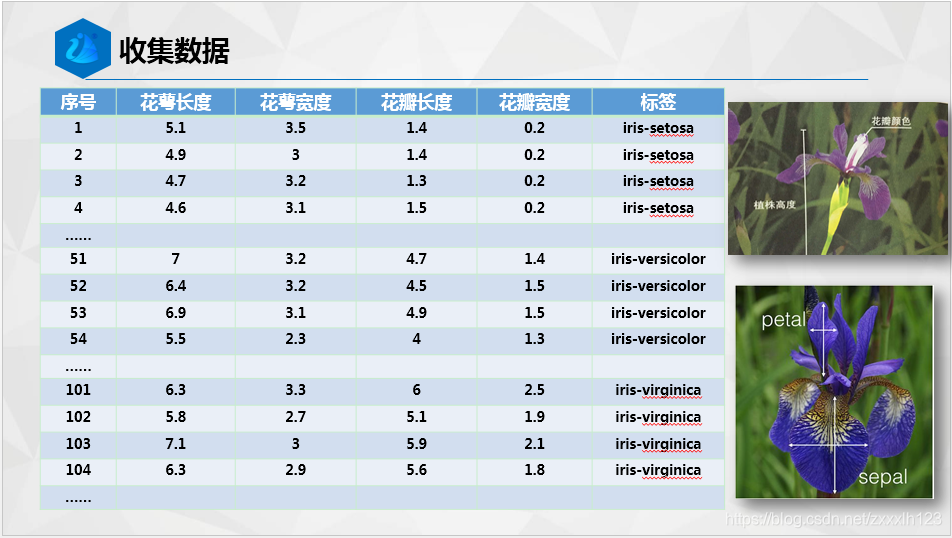
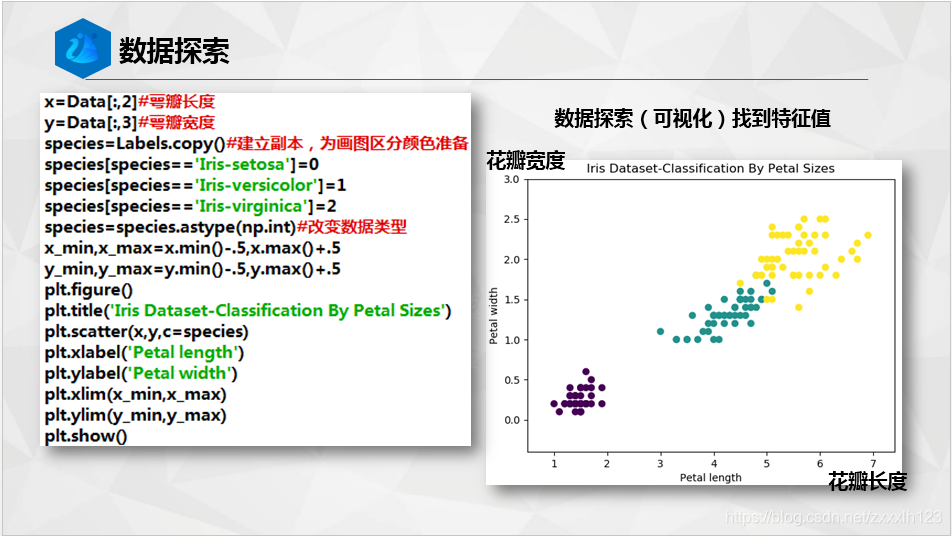


下面附上代码块给大家O(∩_∩)O
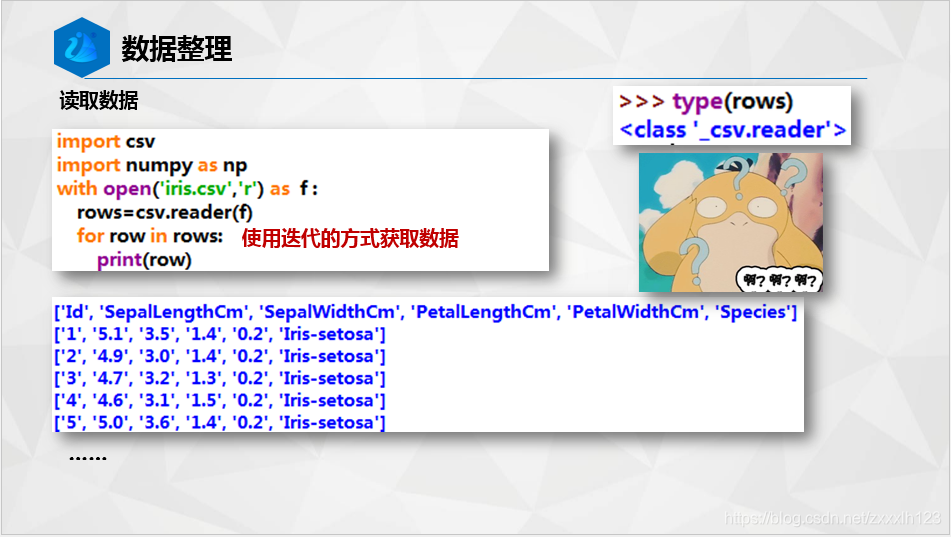
import csv
import numpy as np
with open('iris.csv','r') as f :
rows=csv.reader(f)
for row in rows:
print(row)
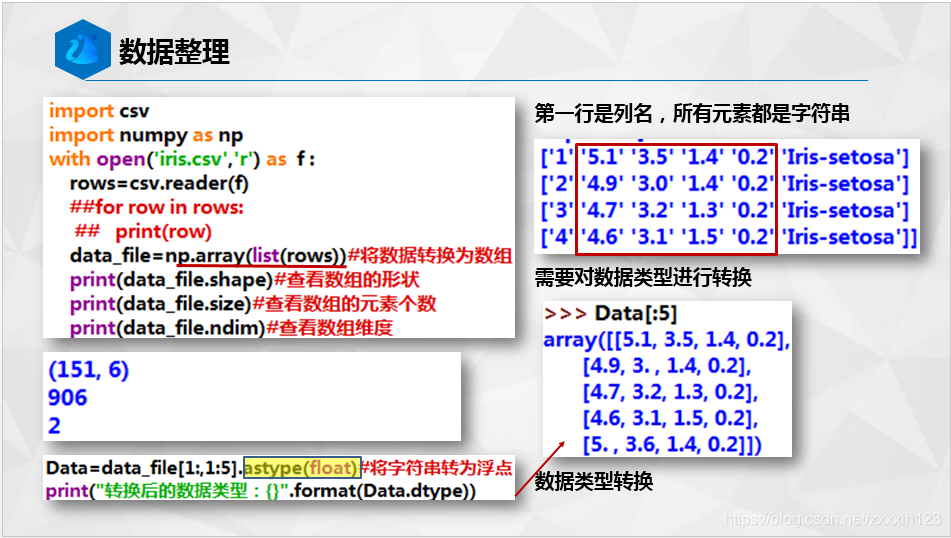
data_file=np.array(list(rows))#将数据转换为数组
print(data_file.shape)#查看数组的形状
Data=data_file[1:,1:5].astype(float)#将字符串转为浮点
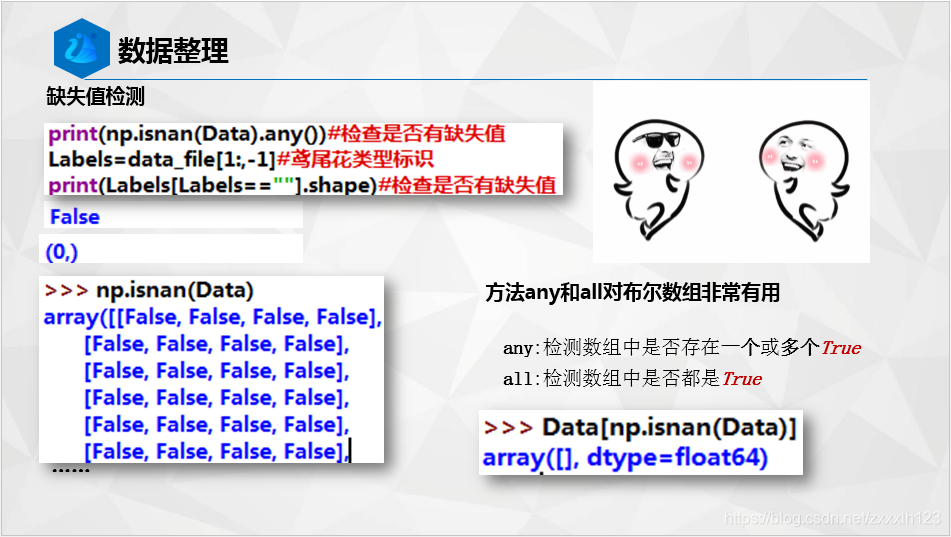
print(np.isnan(Data).any())#检查是否有缺失值
Labels=data_file[1:,-1]#鸢尾花类型标识
print(Labels[Labels==""].shape)#检查是否有缺失值
from sklearn.neighbors import KNeighborsClassifier
np.random.seed(0)#设置随机种子,产生的随机数一样
indices = np.random.permutation(len(Data))#随机打乱数组
print(indices)
Data_train = Data[indices[:-10]]#随机选取140样本作为训练集
Labels_train = Labels[indices[:-10]]#随机选取140样本标签作为训练集
Data_test = Data[indices[-10:]]#剩下10个样本作为测试集
Labels_test = Labels[indices[-10:]]#剩下10个样本标签作为测试集
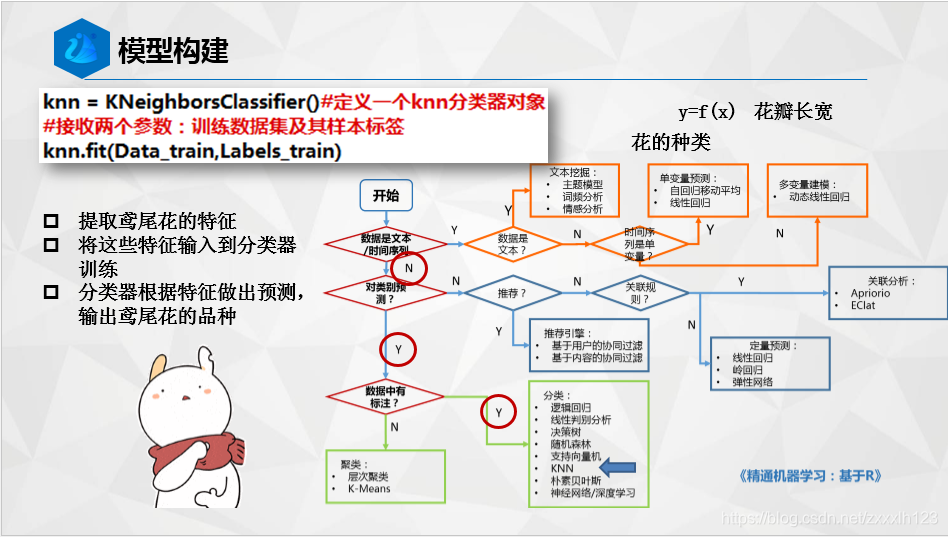
knn = KNeighborsClassifier()#定义一个knn分类器对象
knn.fit(Data_train,Labels_train)#接收两个参数:训练数据集及其样本标签
Labels_predict = knn.predict(Data_test) #调用该对象的测试方法,主要接收一个参数:测试数据集
probility=knn.predict_proba(Data_test)#计算各测试样本基于概率的预测
neighborpoint=knn.kneighbors(Data_test[-1],5,False)
score=knn.score(Data_test,Labels_test,sample_weight=None)#调用该对象的打分方法,计算出准确率
print('Labels_predict = ')
print(Labels_predict )#输出测试的结果
print('Labels_test = ')
print(Labels_test)#输出原始测试数据集的正确标签
print('Accuracy:',score)#输出准确率计算结果
print(probility)
编写打磨课件不易,走过路过别忘记给咱点个赞,小女子在此(❁´ω`❁)谢过!