对鸢尾花数据集进行分类,这里主要用到的是逻辑回归(Logistic Regression)。
鸢尾花数据集是一个4维3类的数据集,其数据集描述如下:
Data Set Characteristics: :Number of Instances: 150 (50 in each of three classes) :Number of Attributes: 4 numeric, predictive attributes and the class :Attribute Information: - sepal length in cm - sepal width in cm - petal length in cm - petal width in cm - class: - Iris-Setosa - Iris-Versicolour - Iris-Virginica测试代码:
# 导入数据集
iris = datasets.load_iris() # from sklearn import datasets
lg = linear_model.LogisticRegression(multi_class='ovr') # 采用 one-vs-rest 的多分类策略
predicted = model_selection.cross_val_predict(lg, iris.data, iris.target, cv=5) # 5个KFold交叉验证集
# 判断分类正误率
sums = 0
for i in range(len(predicted)):
if predicted[i] == iris.target[i]:
sums += 1
print sums * 100.0 / len(predicted), "%"
# 制图
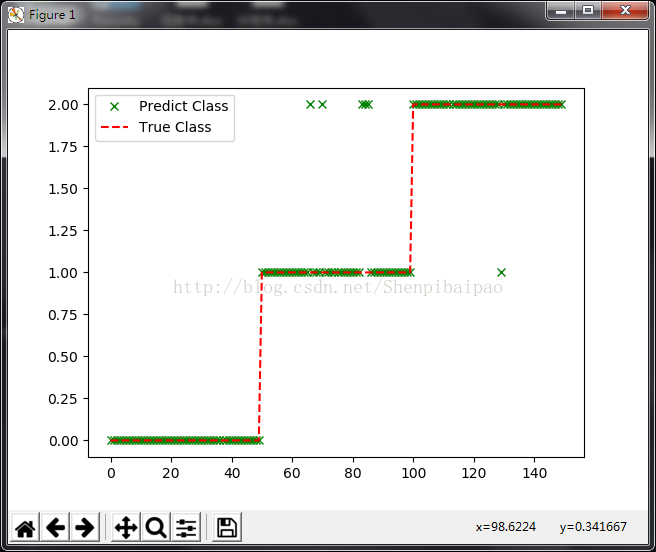
fig, ax = plt.subplots() # import matplotlib.pyplot as plt
ax.plot(range(len(predicted)), predicted, 'gx', label='Predicted Class')
ax.plot(range(len(iris.target)), iris.target, 'r--', label='True Class')
plt.show()# http://blog.csdn.net/shenpibaipao
分类正确率可以达到96.0%