常见API
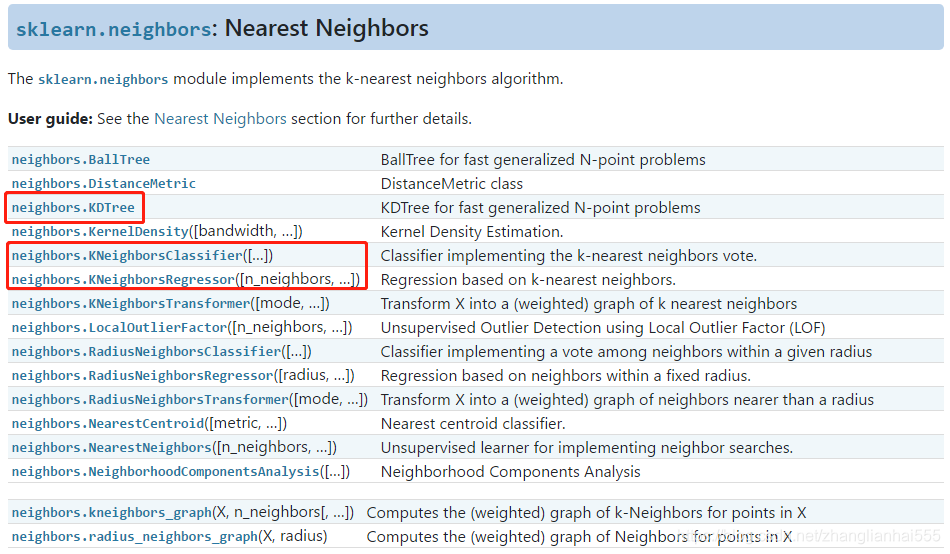
这里有我们上篇博客提到的DKTree,还有最基本的KNeighborsClassifier(用于分类) 和 KNeighborsRegressor(用于回归),这里列出常见的参数:
| 参数 | KNeighborsClassifier / KNeighborsRegressor |
|---|---|
| weights | 样本权重,可选参数: uniform(等权重)、distance(权重和距离成反比,越近影响越强);默认为uniform |
| n_neighbors | 邻近数目,默认为5 |
| algorithm | 计算方式,默认为auto,可选参数: auto、ball_tree、kd_tree、brute;推荐选择kd_tree |
| leaf_size | 在使用KD_Tree的时候,叶子数量,默认为30 |
| metric | 样本之间距离度量公式,默认为minkowski(闵可夫斯基);当参数p为2的时候,其实就是欧几里得距离 |
| p | 给定minkowski距离中的p值,默认为2 |
数据
这里使用比较经典的鸢尾花数据,来做分类。相关数据已上传上去。(不知为何,每次上传的资源,设置的所需积分/C币都是0,但最终莫名的变成了其他数值,恶心)
数据链接:https://download.csdn.net/download/zhanglianhai555/12340138
代码
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import warnings
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier#KNN
from sklearn.preprocessing import label_binarize
from sklearn import metrics
## 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
## 数据加载
path = "datas/iris.data"
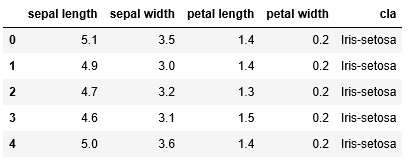
names = ['sepal length', 'sepal width', 'petal length', 'petal width', 'cla']
df = pd.read_csv(path, header=None, names=names)
df['cla'].value_counts()
df.head()
def parseRecord(record):
result=[]
r = zip(names,record)
for name,v in r:
if name == 'cla':
if v == 'Iris-setosa':
result.append(1)
elif v == 'Iris-versicolor':
result.append(2)
elif v == 'Iris-virginica':
result.append(3)
else:
result.append(np.nan)
else:
result.append(float(v))
return result
### 1. 数据转换为数字以及分割
## 数据转换
datas = df.apply(lambda r: parseRecord(r), axis=1)
## 异常数据删除
datas = datas.dropna(how='any')
## 数据分割
X = datas[names[0:-1]]
Y = datas[names[-1]]
## 数据抽样(训练数据和测试数据分割)
X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.4, random_state=0)
print ("原始数据条数:%d;训练数据条数:%d;特征个数:%d;测试样本条数:%d" % (len(X), len(X_train), X_train.shape[1], X_test.shape[0]))
原始数据条数:150;训练数据条数:90;特征个数:4;测试样本条数:60
##### KNN算法实现
# a. 模型构建
# 模型中介绍的K值:n_neighbors
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, Y_train)
# b. 模型效果输出
## 将正确的数据转换为矩阵形式
y_test_hot = label_binarize(Y_test,classes=(1,2,3))
## 得到预测属于某个类别的概率值
knn_y_score = knn.predict_proba(X_test)
## 计算roc的值
knn_fpr, knn_tpr, knn_threasholds = metrics.roc_curve(y_test_hot.ravel(),knn_y_score.ravel())
## 计算auc的值
knn_auc = metrics.auc(knn_fpr, knn_tpr)
print ("KNN算法R值:", knn.score(X_train, Y_train))
print ("KNN算法AUC值:", knn_auc)
# c. 模型预测
knn_y_predict = knn.predict(X_test)
KNN算法R值: 0.9888888888888889
KNN算法AUC值: 0.9700000000000001
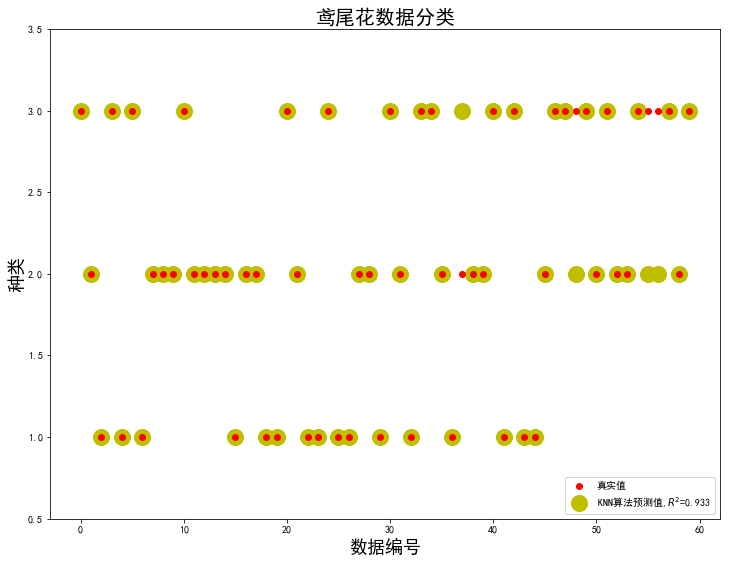
## 画图2:预测结果画图
x_test_len = range(len(X_test))
plt.figure(figsize=(12, 9), facecolor='w')
plt.ylim(0.5,3.5)
plt.plot(x_test_len, Y_test, 'ro',markersize = 6, zorder=3, label=u'真实值')
plt.plot(x_test_len, knn_y_predict, 'yo', markersize = 16, zorder=1, label=u'KNN算法预测值,$R^2$=%.3f' % knn.score(X_test, Y_test))
plt.legend(loc = 'lower right')
plt.xlabel(u'数据编号', fontsize=18)
plt.ylabel(u'种类', fontsize=18)
plt.title(u'鸢尾花数据分类', fontsize=20)
plt.show()