对于监督学习,训练数据都是事先已知预测结果的,即训练数据中已提供了数据的类标。无监督学习则是在事先不知道正确结果(即无类标信息或预期输出值)的情况下,发现数据本身所蕴含的结构等信息。
无监督学习通过对无标记训练样本的学习来寻找这些数据的内在性质。
聚类的目标是发现数据中自然形成的分组,使得每个簇内样本的相似性大于与其他簇内样本的相似性。同时聚类可以起到探索数据性质的作用。
聚类的思想是:将数据集划分为若干个不相交子集(称为一个簇,cluster),每个簇潜在地对应于某一个概念。但是聚类的过程仅仅能生成簇结构,而每个簇所代表的概念的语义由使用者子集解释。也就是说,聚类算法并不会告诉你它生成了的这些簇分别代表什么意义。它只会高斯你算法已经将数据集划分为这些不相交的簇了。
聚类(或称为聚类分析)是一种可以找到相似对象群组的技术,与组间对象相比,组内对象之间具有更高的相似度。
聚类在商业领域的应用包括:按照不同主题对文档、音乐、电影等进行分组,或基于常见的购买行为,发现有相同兴趣爱好的顾客,并以此构建推荐引擎。
聚类分为三种:基于原型的聚类、基于层次(hierarchical)的聚类、基于密度(density-based)的聚类。分别对应以下三种算法:
K-means:
K-means算法是基于原型的聚类。基于原型的聚类意味着每个簇都对应一个原型,它可以是一些具有连续型特征的相似点的中心点(平均值),或者是类别特征情况下相似点的众数——最典型或是出现频率最高的点。
优点是易于实现,且具有很高的计算效率。可以高效识别球形簇。但算法的缺点在于必须事先指定先验的簇数量k。当k值选择不当,则可能导致聚类效果不佳。并且在实际应用中,簇数量并非总是是显而易见的,特别当面对一个无法可视化的高维数据集则很难预先确定簇数量。同时k-means的另一个特点是簇不可重叠,也不可分层,且假定每个簇至少会有一个样本。
聚类的目标就是根据样本自身特征的相似性对其进行分组。
K-means算法步骤如下:
1、从样本点中随机选择k个点作为初始簇中心。
2、将每个样本点划分到距离它最近的中心点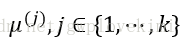
3、用各簇中所有样本的中心点替代原有的中心点。
4、重复步骤2和3,直到中心点不变或者到达预定迭代次数时,算法终止。
关于对象之间的相似性:将相似性定义为距离的倒数,在m维空间中,对于特征取值为连续型实数的聚类分析来说,常用的聚类独立标准是欧几里得距离平方:
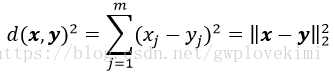
下标索引j为样本点x和y的第j个维度(特征例)。接下来的内容以i来代表样本索引;j代表簇索引。
将k-means算法描述为一个简单的优化问题,通过迭代使得簇内误差平方和(within-cluster sum of squared errors, SSE)最小,也称作簇惯性
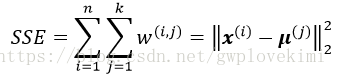
其中,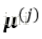
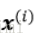
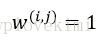
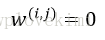
给出Python代码如下:
from sklearn.datasets import make_blobs
x,y=make_blobs(n_samples=150,n_features=2,centers=3,cluster_std=0.5,shuffle=True,random_state=0)
#scikit中的make_blobs方法常被用来生成聚类算法的测试数据
#直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。
###########################将所生成的聚类数据画出来##############################
import matplotlib.pyplot as plt
plt.scatter(x[:, 0], x[:, 1], c='white', marker='o', edgecolor='black', s=50)
plt.grid()
plt.tight_layout()
plt.show()
######################采用scikit-learn中的KMeans################################
from sklearn.cluster import KMeans
km=KMeans(n_clusters=3,init='random',n_init=10,max_iter=300,tol=1e-04,random_state=0)
#将簇的数量设定为3个。设置n_init=10,程序能够基于不同的随机初始中心独立运行算法10次,并从中选择SSE最小的作为最终模型。
#通过max_iter参数,指定算法每轮运行的迭代次数。
#tol=1e-04参数控制对簇内误差平方和的容忍度
#对于sklearn中的k-means算法,如果模型收敛了,即使未达到预定迭代次数,算法也会终止
#注意,将init='random'改为init='k-means++'(默认值)就由k-means算法变为k-means++算法了
y_km=km.fit_predict(x)
############################做可视化处理########################################
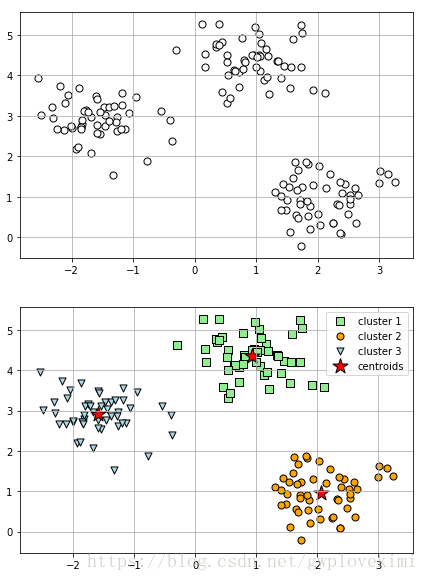
plt.scatter(x[y_km == 0, 0],x[y_km == 0, 1],s=50, c='lightgreen',marker='s', edgecolor='black',label='cluster 1')
plt.scatter(x[y_km == 1, 0],x[y_km == 1, 1],s=50, c='orange', marker='o', edgecolor='black',label='cluster 2')
plt.scatter(x[y_km == 2, 0],x[y_km == 2, 1],s=50, c='lightblue',marker='v', edgecolor='black',label='cluster 3')
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1],s=250, marker='*',c='red', edgecolor='black',label='centroids')
#簇中心保存在KMeans对象的centers_属性中
plt.legend(scatterpoints=1)
plt.grid()
plt.tight_layout()
plt.show()结果如下图所示:
经典的k-means算法使用随机点作为初始中心点,若初始中心点选择不当,有可能会导致簇效果不佳或产生收敛速度慢等问题。解决这一问题的其中一种方案就是在数据集上多次运行k-means算法,并根据误差平方和(SSE)选择性能最好的模型。另一种方案就是使用k-means++算法让初始中心点彼此尽可能远离,相比传统的k-means算法,它能够产生更好、更一致的结果。
k-means++算法的初始化过程可以概括如下:
1)初始化一个空的集合M,用于存储选定的k个中心点。
2)从输入样本中随机选定第一个中心点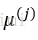
3)对于集合M之外的任一样本点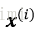
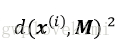
4)使用加权概率分布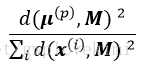
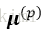
5)重复步骤2、3,直到选定k个中心点。
6)基于选定的中心点执行k-means算法。
给出Python代码如下:
from sklearn.datasets import make_blobs
x,y=make_blobs(n_samples=150,n_features=2,centers=3,cluster_std=0.5,shuffle=True,random_state=0)
#scikit中的make_blobs方法常被用来生成聚类算法的测试数据
#直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。
######################采用scikit-learn中的KMeans################################
from sklearn.cluster import KMeans
km=KMeans(n_clusters=3,init='k-means++',n_init=10,max_iter=300,tol=1e-04,random_state=0)
#将簇的数量设定为3个。设置n_init=10,程序能够基于不同的随机初始中心独立运行算法10次,并从中选择SSE最小的作为最终模型。
#通过max_iter参数,指定算法每轮运行的迭代次数。
#tol=1e-04参数控制对簇内误差平方和的容忍度
#对于sklearn中的k-means算法,如果模型收敛了,即使未达到预定迭代次数,算法也会终止
#注意,将init='random'改为init='k-means++'(默认值)就由k-means算法变为k-means++算法了
y_km=km.fit_predict(x)
############################做可视化处理########################################
import matplotlib.pyplot as plt
plt.scatter(x[y_km == 0, 0],x[y_km == 0, 1],s=50, c='lightgreen',marker='s', edgecolor='black',label='cluster 1')
plt.scatter(x[y_km == 1, 0],x[y_km == 1, 1],s=50, c='orange', marker='o', edgecolor='black',label='cluster 2')
plt.scatter(x[y_km == 2, 0],x[y_km == 2, 1],s=50, c='lightblue',marker='v', edgecolor='black',label='cluster 3')
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1],s=250, marker='*',c='red', edgecolor='black',label='centroids')
#簇中心保存在KMeans对象的centers_属性中
plt.legend(scatterpoints=1)
plt.grid()
plt.tight_layout()
plt.show()结果如下图所示:
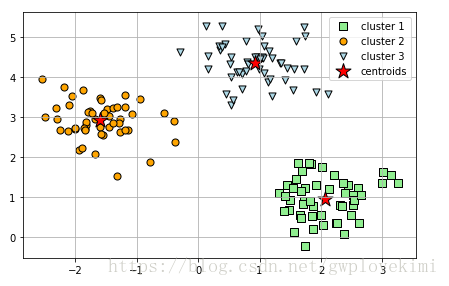
感觉,只看这个程序的效果,k-means和k-means++差别不大。
k-means算法又分为硬聚类和软聚类。硬聚类指的是数据集中每个样本只能划分到一个簇(即上面用到的算法)。而软聚类,又称为模糊聚类算法可以将一个样本划分到一个或者多个簇。对于软聚类本博文不做详细介绍(因为sklearn中没有实现),有兴趣的读者可以参考书籍《Python机器学习》11.1.2节。
通过肘方法来确定簇的最佳数量
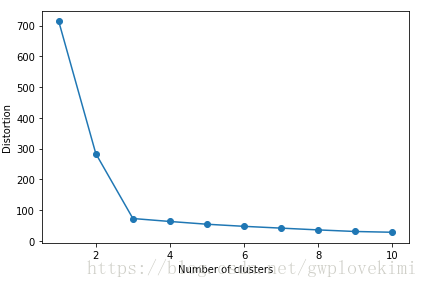
无监督学习中存在一个问题,就是并不知道问题的确切答案,由于没有数据集样本类标的确切数据,所以无法在无监督学习中用评估监督学习模型性能的指标。因此,为了对聚类效果进行定量分析,需要使用模型内部的固有度量来比较不同k-means聚类结果的性能(如前面讨论过的簇内误差平方和,即聚类偏差)。通过下面代码来查看簇内误差平方和:

基于簇内误差平方和,我们可使用图形工具,即所谓的肘方法,针对给定任务估计出最优的簇数量k。直观地看,增加k的值可以降低聚类偏差,这是应为样本会更加接近其所在簇的中心点。肘方法的基本理念就是找出聚类偏差骤增时的k值:
from sklearn.datasets import make_blobs
x,y=make_blobs(n_samples=150,n_features=2,centers=3,cluster_std=0.5,shuffle=True,random_state=0)
############################绘制不同k值对应的聚类偏差图##########################
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
distortions = []
for i in range(1, 11):
km = KMeans(n_clusters=i, init='k-means++',n_init=10,max_iter=300,random_state=0)
km.fit(x)
distortions.append(km.inertia_)
plt.plot(range(1, 11), distortions, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.tight_layout()
plt.show()结果如下图所示:
通过轮廓图定量分析聚类质量
另一种评估聚类质量的定量分析方法是轮廓分析。此方法也可用于k-means之外的其他聚类方法。轮廓分析可以使用一个图形工具来度量簇中样本聚集的密集程度。通过如下三个步骤,可以计算数据集中单个样本的轮廓系数:
1)将某一样本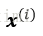
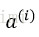
2)将样本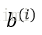
3)将簇分离度与簇内聚度之差除以二者中的较大者得到轮廓系数,如下式所示:
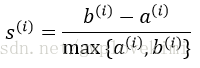
轮廓系数的值介于-1到1之间。从上述公式可见,若簇内聚度与分离度相等(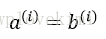
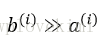
给出Python代码如下:
from sklearn.datasets import make_blobs
x,y=make_blobs(n_samples=150,n_features=2,centers=3,cluster_std=0.5,shuffle=True,random_state=0)
############################绘制k=3时k-means算法的轮廓系数图##########################
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cm
from sklearn.metrics import silhouette_samples
km = KMeans(n_clusters=3,init='k-means++',n_init=10,max_iter=300,tol=1e-04,random_state=0)
y_km = km.fit_predict(x)
cluster_labels = np.unique(y_km)
n_clusters = cluster_labels.shape[0]
silhouette_vals = silhouette_samples(x, y_km, metric='euclidean')#silhouette_samples计算获得metric
y_ax_lower, y_ax_upper = 0, 0
yticks = []
for i, c in enumerate(cluster_labels):
c_silhouette_vals = silhouette_vals[y_km == c]
c_silhouette_vals.sort()
y_ax_upper += len(c_silhouette_vals)
color = cm.jet(float(i) / n_clusters)
plt.barh(range(y_ax_lower, y_ax_upper), c_silhouette_vals, height=1.0,edgecolor='none', color=color)
yticks.append((y_ax_lower + y_ax_upper) / 2.)
y_ax_lower += len(c_silhouette_vals)
silhouette_avg = np.mean(silhouette_vals)
plt.axvline(silhouette_avg, color="red", linestyle="--")
plt.yticks(yticks, cluster_labels + 1)
plt.ylabel('Cluster')
plt.xlabel('Silhouette coefficient')
plt.tight_layout()
plt.show()结果如下图所示:
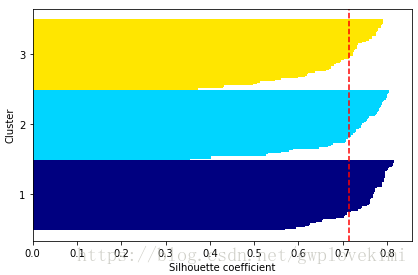
通过观察轮廓图,可以快速知晓不同簇的大小,且能够判断出簇中是否包含异常点。由上图可见,轮廓系数未接近0点,此指标显示聚类效果不错。此外,为了评判聚类效果的优势,我们在图中增加了轮廓系数的平均值(虚线)
为了展示聚类效果不佳的轮廓图的形状,使用两个中心点来初始化k-means算法
from sklearn.datasets import make_blobs
x,y=make_blobs(n_samples=150,n_features=2,centers=3,cluster_std=0.5,shuffle=True,random_state=0)
############################绘制k=2时k-means算法的轮廓系数图##########################
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cm
from sklearn.metrics import silhouette_samples
km = KMeans(n_clusters=2,
init='k-means++',
n_init=10,
max_iter=300,
tol=1e-04,
random_state=0)
y_km = km.fit_predict(x)
#############################画出聚类效果图#####################################
plt.scatter(x[y_km == 0, 0],x[y_km == 0, 1],s=50,c='lightgreen',edgecolor='black',marker='s',label='cluster 1')
plt.scatter(x[y_km == 1, 0],x[y_km == 1, 1],s=50,c='orange',edgecolor='black',marker='o',label='cluster 2')
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1],s=250, marker='*', c='red', label='centroids')
plt.legend()
plt.grid()
plt.tight_layout()
plt.show()
###########################绘制轮廓图对聚类结果进行评估##########################
cluster_labels = np.unique(y_km)
n_clusters = cluster_labels.shape[0]
silhouette_vals = silhouette_samples(x, y_km, metric='euclidean')
y_ax_lower, y_ax_upper = 0, 0
yticks = []
for i, c in enumerate(cluster_labels):
c_silhouette_vals = silhouette_vals[y_km == c]
c_silhouette_vals.sort()
y_ax_upper += len(c_silhouette_vals)
color = cm.jet(float(i) / n_clusters)
plt.barh(range(y_ax_lower, y_ax_upper), c_silhouette_vals, height=1.0,edgecolor='none', color=color)
yticks.append((y_ax_lower + y_ax_upper) / 2.)
y_ax_lower += len(c_silhouette_vals)
silhouette_avg = np.mean(silhouette_vals)
plt.axvline(silhouette_avg, color="red", linestyle="--")
plt.yticks(yticks, cluster_labels + 1)
plt.ylabel('Cluster')
plt.xlabel('Silhouette coefficient')
plt.tight_layout()
plt.show()结果如下图所示:
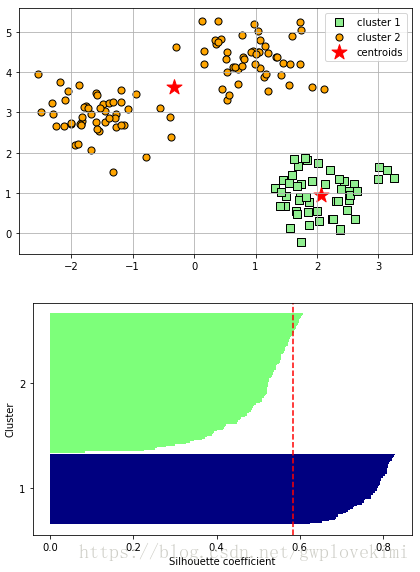
由结果图可以看出,轮廓具有哦明显不同的长度和宽度,因此改聚类非最优结果。
层次聚类:
层次聚类(hierarchical clustering)算法的一个优势在于:它能够使我们绘制出树状图(基于二叉层次聚类的可视化),这有助于我们使用有意义的分类法解释聚类结果。层次聚类的另一优势在于我们无需事先指定簇的数量。
层次聚类可以在不同层上对数据集进行划分,形成树状的聚类结构。
层次聚类有两种主要方法:凝聚层次聚类和分裂层次聚类。在分裂层次聚类中,我们首先把所有样本看作是同一个簇中,然后迭代地将簇分为更小的簇,直到每个簇只包含一个样本。然凝聚层次聚类则是与分裂层次聚类相反,最初把每个样本看作是一个单独的簇,重复地将最近的一对簇合并,直到所有的样本都在一个簇中为止。
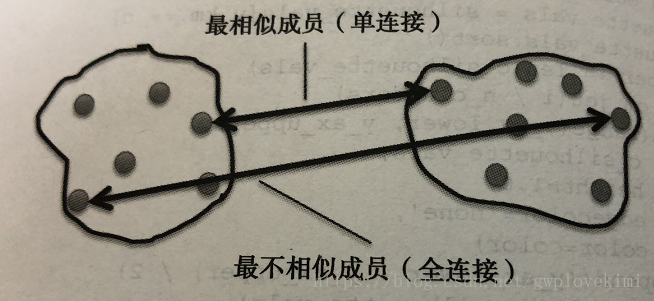
在凝聚层次聚类中,判定簇间距离的两个标准方法分别是单连接和全连接。可以使用单连接方法计算每一对簇中最相似两个样本的距离,并合并距离最近的两个样本所属的簇。与之相反,全连接的方法是通过比较找到分布于两个簇中最不相似的样本(距离最远的样本)进而完成簇的合并。如下图所示:
基于全连接方法的凝聚层次聚类的迭代过程如下:
1)计算得到所有样本间的距离矩阵。
2)将每个数据点看作是一个单独的簇。
3)基于最不相似(距离最远)样本的距离,合并两个最接近的簇。
4)更新相似矩阵(样本间距离矩阵)。
5)重复步骤2到4,直到所有样本都合并到一个簇为止。
给出python代码如下:
####################先随机生成一些样本数据用于计算###############################
import numpy as np
np.random.seed(123)
#seed( ) 用于指定随机数生成时所用算法开始的整数值,
#如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同
variables=['X','Y','Z']#列表样本的不同特征
labels=['ID_0','ID_1','ID_2','ID_3','ID_4']#5个不同的样本
x=np.random.random_sample([5,3])*10#返回随机的浮点数,在半开区间 [0.0, 1.0)
import pandas as pd
df=pd.DataFrame(x,columns=variables,index=labels)
#DataFrame是Pandas中的一个表结构的数据结构,包括三部分信息,表头(列的名称),表的内容(二维矩阵),索引(每行一个唯一的标记)。
print(df)
##########################基于距离矩阵进行层次聚类###############################
#使用SciPy中的子模块spatial.distance中的pdist函数来计算距离矩阵
from scipy.spatial.distance import pdist,squareform
#pdist观测值(n维)两两之间的距离。距离值越大,相关度越小
#squareform将向量形式的距离表示转换成dense矩阵形式。
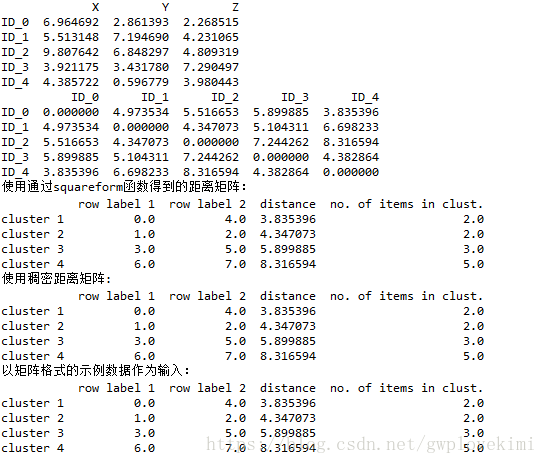
row_dist = pd.DataFrame(squareform(pdist(df, metric='euclidean')),columns=labels,index=labels)
#基于样本的特征X、Y和Z,使用欧几里得距离计算了样本间的两两距离。
#通过将pdist函数的返回值输入到squareform函数中,获得一个记录成对样本间距离的对称矩阵
print(row_dist)
#使用cluster.hierarchy子模块下的linkage函数。此函数以全连接作为距离判定标准,它能够返回一个关联矩阵
from scipy.cluster.hierarchy import linkage
##############################分析聚类结果######################################
#使用通过squareform函数得到的距离矩阵:
row_clusters1 = linkage(pdist(df, metric='euclidean'), method='complete')
df1=pd.DataFrame(row_clusters1,
columns=['row label 1', 'row label 2',
'distance', 'no. of items in clust.'],
index=['cluster %d' % (i + 1)
for i in range(row_clusters1.shape[0])])
print("使用通过squareform函数得到的距离矩阵:")
print(df1)
#使用稠密距离矩阵:
row_clusters2 = linkage(pdist(df, metric='euclidean'), method='complete')
#进一步分析聚类结果
df2=pd.DataFrame(row_clusters2,
columns=['row label 1', 'row label 2',
'distance', 'no. of items in clust.'],
index=['cluster %d' % (i + 1) for i in range(row_clusters2.shape[0])])
print("使用稠密距离矩阵:")
print(df2)
#以矩阵格式的示例数据作为输入:
row_clusters3 = linkage(df.values, method='complete', metric='euclidean')
df3=pd.DataFrame(row_clusters3,
columns=['row label 1', 'row label 2',
'distance', 'no. of items in clust.'],
index=['cluster %d' % (i + 1)
for i in range(row_clusters3.shape[0])])
print("以矩阵格式的示例数据作为输入:")
print(df3)
###################采用树状图的形式对聚类结果进行可视化展示#######################
from scipy.cluster.hierarchy import dendrogram
import matplotlib.pyplot as plt
row_dendr = dendrogram(row_clusters1, labels=labels,)
plt.tight_layout()
plt.ylabel('Euclidean distance')
plt.show()结果如下图所示:
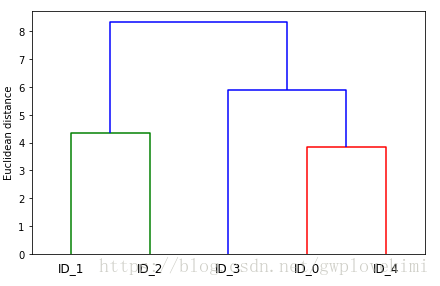
此树状图描述了采用凝聚层次聚类合并生成不同簇的过程。首先是ID0和ID4合并,接下来是ID1和ID2合并。
接下来,采用sklearn中的AgglomerativeClustering类进行基于凝聚的层次聚类。
####################先随机生成一些样本数据用于计算###############################
import numpy as np
np.random.seed(123)
#seed( ) 用于指定随机数生成时所用算法开始的整数值,
#如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同
variables=['X','Y','Z']#列表样本的不同特征
labels=['ID_0','ID_1','ID_2','ID_3','ID_4']#5个不同的样本
x=np.random.random_sample([5,3])*10#返回随机的浮点数,在半开区间 [0.0, 1.0)
###############################基于凝聚的层次聚类###############################
from sklearn.cluster import AgglomerativeClustering
ac = AgglomerativeClustering(n_clusters=2,
affinity='euclidean',
linkage='complete')
labels = ac.fit_predict(x)
print('Cluster labels: %s' % labels)结果如下图所示:
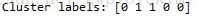
ID1和ID2归到一起,ID0、ID3和ID4归到一起,跟上面是一样的。
密度聚类:
密度聚类假设聚类结构能够通过样本分布的紧密程度来确定
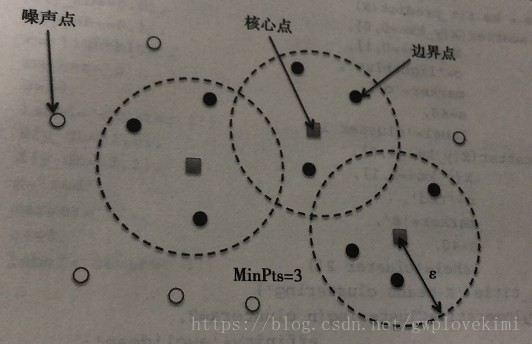
基于密度空间的聚类算法(density based spatial clustering of application with noise,DBSCAN)。与k-means算法不同,DBSCAN的簇空间不一定是球状的。此外,不同于k-means和层聚类,DBSCAN可以识别并移除噪声点,因此它不一定会将所有的样本点都划分都某一簇中。如下图所示:
理论部分就不多说了,下面直接给出代码(通过创建半月形数据集,将三种聚类算法进行对比):
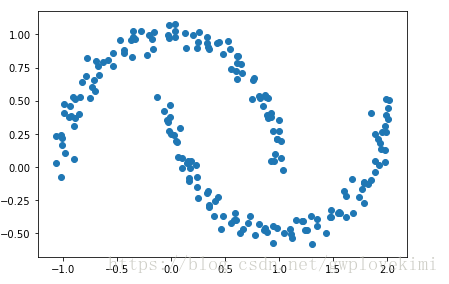
###############################构建半月形数据集#################################
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
plt.scatter(X[:, 0], X[:, 1])
plt.tight_layout()
plt.show()
##############################采用k-means算法进行聚类###########################
from sklearn.cluster import KMeans
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 3))
km = KMeans(n_clusters=2, random_state=0)
y_km = km.fit_predict(X)
ax1.scatter(X[y_km == 0, 0], X[y_km == 0, 1],
edgecolor='black',
c='lightblue', marker='o', s=40, label='cluster 1')
ax1.scatter(X[y_km == 1, 0], X[y_km == 1, 1],
edgecolor='black',
c='red', marker='s', s=40, label='cluster 2')
ax1.set_title('K-means clustering')
#############################基于凝聚的层次聚类#################################
#采用sklearn中的AgglomerativeClustering类进行基于凝聚的层次聚类
from sklearn.cluster import AgglomerativeClustering
ac = AgglomerativeClustering(n_clusters=2,
affinity='euclidean',
linkage='complete')
y_ac = ac.fit_predict(X)
ax2.scatter(X[y_ac == 0, 0], X[y_ac == 0, 1], c='lightblue',
edgecolor='black',
marker='o', s=40, label='cluster 1')
ax2.scatter(X[y_ac == 1, 0], X[y_ac == 1, 1], c='red',
edgecolor='black',
marker='s', s=40, label='cluster 2')
ax2.set_title('Agglomerative clustering')
plt.legend()
plt.tight_layout()
plt.show()
##########################采用DBSCAN算法进行聚类################################
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=0.2, min_samples=5, metric='euclidean')
y_db = db.fit_predict(X)
plt.scatter(X[y_db == 0, 0], X[y_db == 0, 1],
c='lightblue', marker='o', s=40,
edgecolor='black',
label='cluster 1')
plt.scatter(X[y_db == 1, 0], X[y_db == 1, 1],
c='red', marker='s', s=40,
edgecolor='black',
label='cluster 2')
plt.legend()
plt.tight_layout()
plt.show()结果如下图所示:
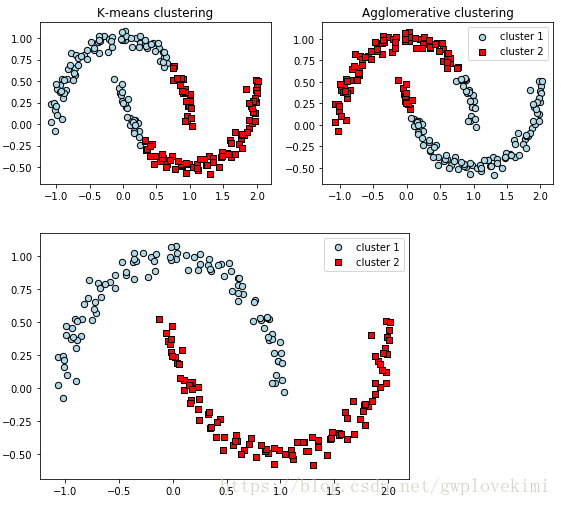
DBSCAN可以对任意形状的数据进行聚类。而k-means算法和基于全连接的层次聚类算法无法将两个簇分开。但同时,DBSCAN也存在一些缺点。对于一个给定样本数量的训练数据集,随着数据集中特征数量的增加,维度灾难的负面影响会随之递增。在使用欧几里得距离度量时,维度灾难问题尤为突出。此外,为了能够生成更优的聚类结果,需要对DBSCAN中的两个超参(MintPts和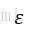
补充,这里所谓的两个超参本人也不是很了解,给出书里截图下如:

总结以上三种算法:k-means算法基于指定数量的簇中心,将样本划分为球形簇。层次聚类不需要事先指定簇的数量,且聚类的结果可以通过树状图进行可视化展示。而基于密度空间的聚类算法则是基于样本的密度对其进行分组,且可以处理异常值以及识别非球形簇。
主要参考资料:
- 《Python机器学习》
- 《Python大战机器学习》