1.前言
什么叫做聚类,这是一种典型的无监督机器学习算法。简单来说就是把相似度高的放到一堆。在这里我们关注的重点并不是特征和标签之间的关系,而是样本与样本之间的关系。
2.K-means聚类
K-means是所有实现聚类的算法中最常用的一种,因为其简单,效果好。听到简单二字是不是觉得有点兴奋,如果学习也是一条食物链的话,那么像这些容易捕捉的猎物,简直就是初学者信心增长的能量之水。那么就一起来蔑视它,蹂躏它把!
K就是我们最终要划分的簇数量,说人话就是要把数据划分为多少堆。其过程是这样的:在一堆数据中,先随机初始化K个簇心,将所有的点按照离簇心最近的原则划分为K个簇。选择每个簇中最中心的位置作为簇心,重新按照离簇心最近的原则分簇;直到所有点所属的簇都不再改变。
3. 关键问题点
1.K的选择
通过上面的描述我们会有一个疑问,所谓的K-means中K的数量到底应该如何选择, 一堆陌生的数据本来就很使人头大,我怎么会知道它应该分成几堆呢?对不起,这个问题暂时还没有一个完美的解决方案。可行的解决方案就是试,多试几个,哪一个可以让你的boss满意,那就可以了。
2.初始化簇心
簇心的初始化,一般有一下几个方法:
1.随机初始化,直接任性的随机初始化K个点,数据量不是很大的情况下也看不出来什么。
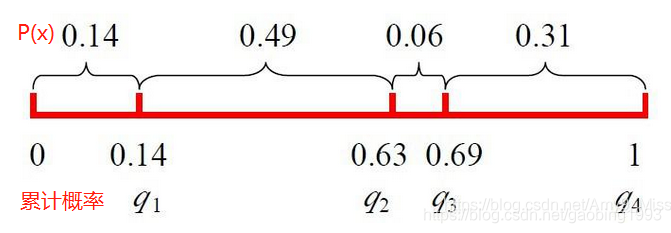
2.轮盘法选择簇心,见名思意,轮盘法是随机从数据中随机选择簇心,离已有的簇心更远的点被选中的概率就会越大。下面的代码实现了轮盘法,其先计算出所有的点到簇心的距离之和,再乘以一个[0,1]之间的随机数,将点到簇心距离之和缩小。然后用这个和去减掉每个点到簇心的距离。因为上面的随机缩小,也因为最大距离在数据中的分布并不是确定的,综合来看的话实现了离现有簇心越远的点被选中的可能性越大。下面的图出自这篇博客
def kpp_centers(data_set, k) :
"""
从数据集中返回 k 个对象可作为质心
"""
cluster_centers = []
cluster_centers.append(random.choice(data_set))
d = [0 for _ in range(len(data_set))]
for _ in range(1, k):
total = 0.0
for i, point in enumerate(data_set):
d[i] = get_closest_dist(point, cluster_centers) # 与最近一个聚类中心的距离
total += d[i]
total *= random.random()
for i, di in enumerate(d): # 轮盘法选出下一个聚类中心;
total -= di
if total > 0:
continue
cluster_centers.append(data_set[i])
break
return cluster_centers3.距离计算
一般情况下我们使用欧氏距离,表示两个点之间的距离。也可以使用余弦距离表示。欧式距离更关心点和点之间的实际距离,余弦距离更关注两个点在方向上的差异
4.总结
本文我们介绍了K-means聚类算法,其工作原理就是根据点到簇心的距离,不断的重新分簇,调整簇心,直到簇不再变动。从而实现了簇内距离最小,簇间距离最大化。并且介绍了两种选择簇心的方法,随机法和轮盘法。以及两种计算距离的方式,和它们的差异。
路飞说过,只要活下去,就一定会有美好的事情发生。相信所有发生在自己身上的事情,都是应该发生在自己身上的,连一件多余的也没有。想清楚后,就不再因为过去犯的错而耿耿于怀,也不因为一些短暂的荣耀而洋洋得意。举世非之而不加沮,举世誉之而不加劝!昨天因为一些事情我很狂,但是我告诉自己先一个人使劲的狂几十分钟吧!时间到了就去工作,恢复理性。这样,在那些贼难受,贼孤单的日子里,我才并不会把它们放在心上。