DepressionNet: A Novel Summarization Boosted Deep Framework for Depression Detection on Social Media
文章目录

会议:SIGIR 2021
任务:抑郁用户检测
原文:链接
Abstract
本文提出了一个新颖的摘要增强的社交媒体抑郁检测深度框架。该框架首先通过混合抽取和抽象(abstractive-extractive)摘要策略在所有的用户推文上选择相关的内容,从而得到更细粒度和相关的内容。该框架由CNN和注意力增强的GRU组成,比现有Baseline性能都好。
本文的主要贡献包括:
- 提出了一个连接用户行为和帖子历史的抑郁检测深度学习框架:Depression-Net;
- 基于连接BERT-BART应用abstractive-extractive自动文本摘要模型,以此来处理两大需求:
- 通过将大量推文浓缩成简短的结论性描述,广泛覆盖抑郁症相关推文;
- 保留可能与抑郁相关的内容。
- 使用了关于用户行为的信息,开发了一个级联的深度网络,将不同层的行为特征串联起来。
Motivation
以往的社交媒体抑郁用户检测研究主要依赖于用户行为及其语言模式,这些研究的缺点是模型会在一些对检测抑郁用户不相关的内容上训练。这些内容会带来低效率和性能降低,例如,带来了维度诅咒问题,以及,这些抑郁无关内容很可能比抑郁敏感的内容对模型分类起到主导性影响。
因此我们需要引入一些方法,这些方法能够削弱这些对抑郁分类有负面影响的内容;此外,我们还需要一个有效的特征选择策略,以便能够从用户中检测出隐含/潜在的模式,即一些难以通过简单的词频统计挖掘或对表层特征建模来很好地建模的模式。
Model
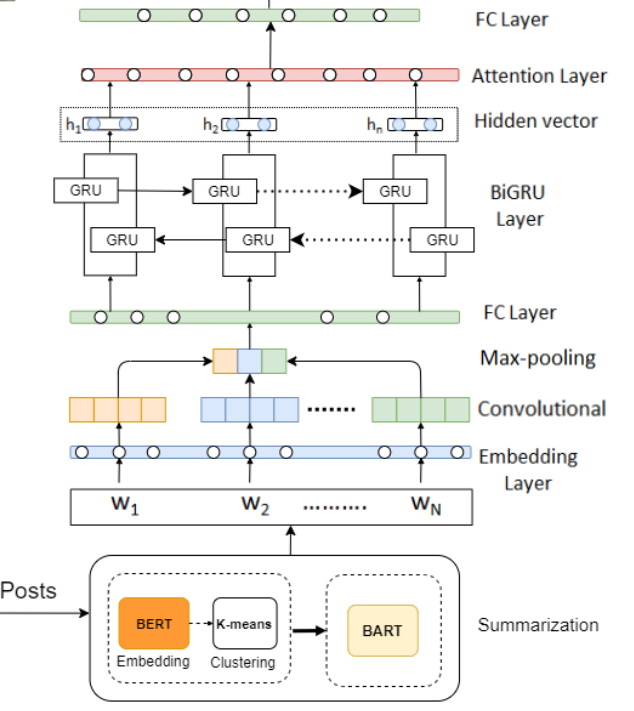
我们在基于CNN和BiGRU+Attention的深度框架使用了抽象-摘要机制,把内容压缩成一个摘要,帮助我们保留每个用户最显著的内容。CNN具有更忠实的特征建模能力,BiGRU用于缓解CNN不能捕获长序列关系的缺点。为了进一步捕获用户模式,我们引入了各种各样的用户行为特征例如:社交网络连接、情感、抑郁症领域特定和用户特定的潜在主题信息,并应用了堆叠的BiGUR。最后,模型连接用户行为和帖子摘要,我们称该模型为DepressionNet,它由两个共享的分层后融合用户行为网络和一个帖子历史感知网络组成。

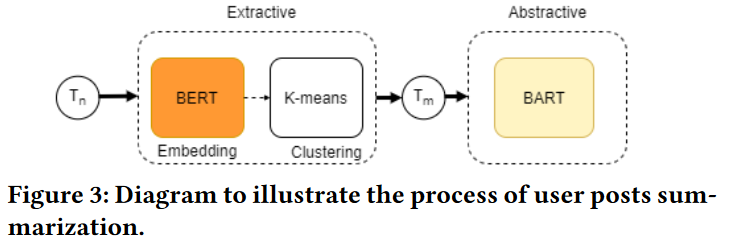
Extractive-Abstractive Summarization
- 动机:摘要可以帮助我们的模型主要关注那些浓缩和突出的内容,本文是第一个把文本摘要用到社交媒体抑郁检测上的。如下图的词云所示,对于抑郁用户的言论,经过摘要以后,原先的冗余、抑郁无关词如:“still”、"eleven"被删除掉了,“sic””、"mental"这样的抑郁相关词变得显著。在非抑郁用户的言论中,我们也观察到了同样的模式。在摘要之后,焦点只停留在大多数非冗余模式上。

-
本文提出了一个融合抽象式和抽取式摘要之间相互作用的框架。考虑到一个用户的帖子是数量巨大,噪声多,存在许多冗余信息,应用抽取式摘要能够通过删除冗余信息帮助我们自动选择用户生成内容,而生成式(抽象式)摘要则在保留语义信息的同时进一步压缩内容。本文使用了BERT-BART模型来进行摘要。
-
BERT编码句子和K-means聚类:对于用户帖子历史 T n T_n Tn,应用抽取式摘要来选取最重要的 m m m个帖子 T m T_m Tm。使用BERT来进行句子嵌入,BERT为每个推文输出了一个向量表示,该向量表示是基于单词的而不是句子。接着,在表征了文本语义中心的高维向量上使用K-means聚类,选取聚类中心来抽取最重要的推文。
-
BART生成式摘要:随后,我们进一步压缩在抽取式摘要阶段可能未被发现的剩余冗余信息。我们使用在CNN/DM数据集上微调过的BART-large进行抽象式摘要。输出摘要: S = w 1 , w 2 , . . , w N , S ∈ R V × N S= {w_1, w_2, .., w_N },S ∈ R^{V×N} S=w1,w2,..,wN,S∈RV×N, V V V表示词表大小, N N N表示摘要长度。
-
CNN+BiGRU+Attention捕获序列信息:BART生成的词嵌入表征了用户帖子在词级别的摘要,这个词嵌入作为堆叠的CNN和BiGRU-Attention模块的输入,以捕获序列信息,如句子的上下文。注意力机制在这一场景中具有优势,因为它有助于模型关注抑郁相关词。
-
词嵌入:通过使用Skipgram模型, S S S中的每个 w i w_i wi随后被转换为词 x i x_i xi的向量,我们使用了预训练的300维嵌入,嵌入的摘要句可以被表示为: X = x 1 , x 2 , . . , x N X={x_1, x_2, .., x_N} X=x1,x2,..,xN。
-
CNN:词向量的加权矩阵将被用作词嵌入层输出,然后输入到CNN+Max-pooling+ReLu。CNN的目标是用来抽取最相关的嵌入摘要句子特征。推文的词向量表示通常比较复杂,因此词向量维度由CNN定期提取,通过池化学习摘要文本中的空间结构提取重要特征。最后,添加一个全连接层,为BiGRU提供统一的全局综合特征。
-
BiGRU-Attention:CNN输出的特征表示作为BiGRU的输入,BiGRU每一时刻的输出的单词表征由前向和后向的表征通过异或运算合并。注意力权重计算方式: u t = t a n h ( h t ) ) u_t = tanh(h_t)) ut=tanh(ht)),然后通过softmax最后加权求和输出的结果作为模型学习到的摘要特征。
-
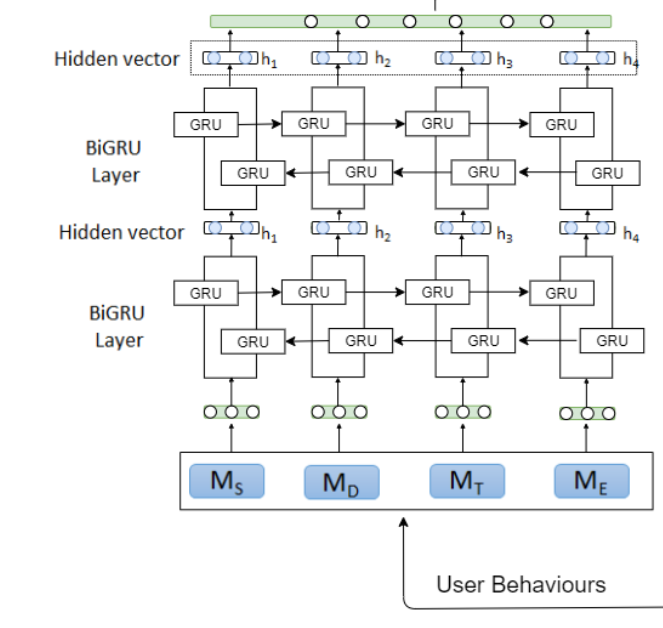
User Behaviour Modelling
-
用户行为特征抽取
把用户行为特征划分为四种类型,如下表所示。
- 用户社交网络。
- 情绪。VAD词典:包括一系列英文单词与它们在V、A、D三个维度的得分。我们用户的每条推特计算其VAD得分,进而计算每个用户的VAD得分。此外,对推文中的表情分为积极、中性、消极进行统计。
- 抑郁领域特定特征。考虑两种特征:抑郁症状和抗抑郁相关。
- 抑郁症状:统计DSM-IV中九个抑郁症状中任一症状在用户推文中的出现次数,症状在9个列表中指定,每个列表包含特定症状的各种同义词。
- 抗抑郁相关:我们从维基百科中创建了一个单独的抗抑郁药物名称列表,统计其在用户推文中的出现次数。
- 话题特征。主题建模通过用户在混合成员假设下发现显著模式(表示为tweet中单词上的分布),即每个推文可能表现出多个模式。频繁出现的话题对于抑郁症检测具有重要作用。本文首先考虑所有抑郁用户的完整推文的语料库,并将每个推文拆分成一个单词列表,然后将所有单词按照出现频率的递减顺序进行组装。我们已经删除了数据中的停用词。应用无监督的LDA主题模型抽取潜在话题分布,对于每个用户,我们分别计算每个单词在该用户推文中出现的次数。

-
stacked BiGRU特征建模:
为了获得细粒度信息,我们对每个多模式特征应用了堆叠BiGRU。具体而言,使用了两个BiGRU,它们分别在后向和前向捕捉每个用户的行为语义,然后是全连接层,行为建模的结果是捕获行为语义信息的高级表示,在抑郁症诊断中发挥关键作用(消融实验已验证)。
Fusion of User Behaviour and Post History
模型整体结构由两个不同的并行网络组成,即用户帖子历史网络(帖子历史感知网络和全连接层)和用户行为网络(两个共享的分层后融合网络,共享我这里理解指的应该是针对四种特征 ,GRU的权重共享吧)。
层次化的时序感知网络融合多个全连接层来集成用户行为表示和用户发布。
对于一个用户,我们提取了一个紧凑的特征,表示行为和用户帖子历史,然后进行后期融合。本文提出的框架建模了一种捕捉行为语义的高层表示,类似地,用户帖子历史由从用户历史中提取的表示抑郁症状逐渐增长的表示组成。我们将这两种表示进行拼接,生成一个既考虑用户行为又考虑用户历史推文反映的特征图。DepressionNet网络的输出是一个响应图,表示抑郁用户和非抑郁用户之间的相似性得分。
由于网络融合了多个层次全连接卷积层,因此,网络可能具有不同的空间分辨率。为了克服这一挑战,我们利用最大池化将浅层卷积层降采样到与深层卷积层相同的分辨率。
用户行为网络的层次化整合带来了性能的显著提升(消融实验已验证)。
Experiments and Results
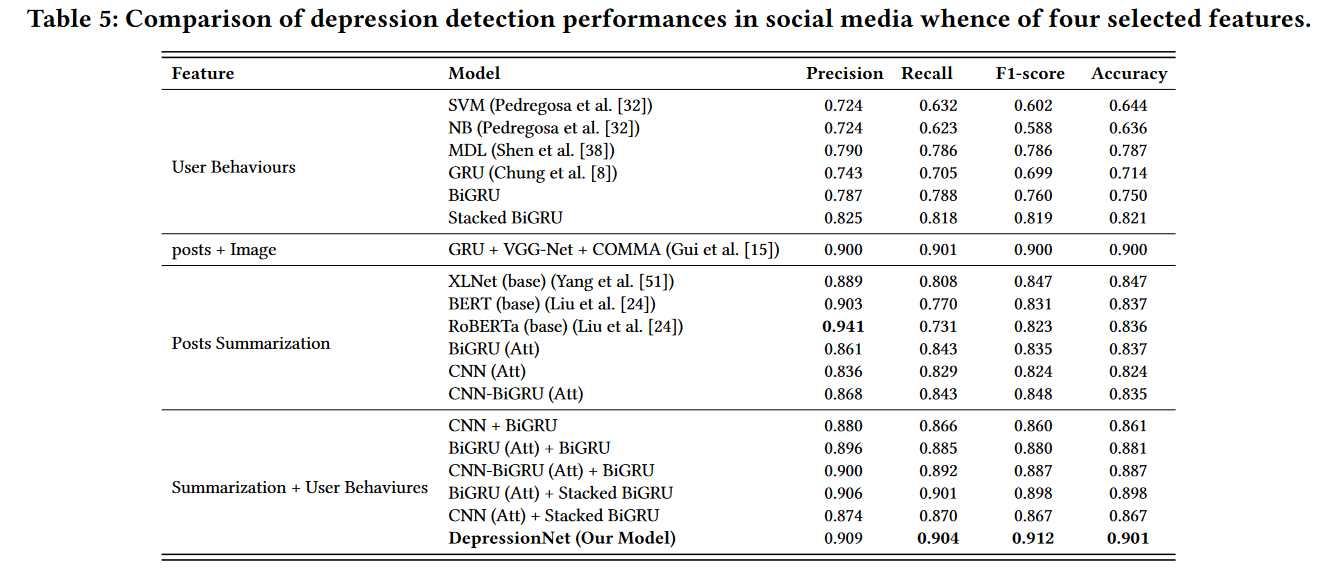
通过消融实验分析发现,仅使用用户帖子摘要的效果要比仅使用用户行为特征要好。对比试验结果表明,联合用户帖子摘要和用户行为特征的模型,DepressionNet达到了最佳性能。
此外,对比试验表明了引入用户帖子中的图像能起到很重要的作用,Depression的性能比post+Image略好,联合学习文本和图像之间的相互作用有助于为模型提供额外的多模态知识。
不仅Depression表现出了很好的性能,它的各部分也展现出了不错的性能。例如stacked BiGRU用于捕获用户行为特征,CNN+BiGRU(Att)用户摘要建模,它们相比其他模型都表现得更好。
作者还做了大量其他实验验证各个行为特征对模型的作用和影响,文本长度、以及不同用户推文选取策略的影响,摘要显示出了显著的优越性和稳定性。通过t-SNE可视化评估生成式摘要发现,无论是BART还是DistilBART,抑郁的摘要文档和非抑郁的摘要文档之间存在明显的分离。
Conclusion
本文提出了一个新颖的分层深度学习网络,融合多个全连接层以集成用户行为表征和用户帖子。本文引入了摘要增强的方法,以过滤无关内容,增强模型对抑郁相关信息的关注度,降低数据维度,提高模型的效率。自动摘要还使得我们的特征选择不存在任意的设计选择,例如丢弃带有某些预定义的单词或句子在一定长度内的句子。最终,用户行为和摘要增强的帖子历史语义的联合作用使得模型比现有的SOTA基线性能都显著地好。
本文的idea是联合用户行为和用户发布的文本内容,联合建模,提升抑郁检测的性能。并且针对用户文本内容太多、噪声多、冗余多以及抑郁症状的特点(越到后期越显著),为了过滤无关内容增强显著内容的分类主导性影响,引入了文本摘要。作者对模型每个部分设计的动机都说明得很好,值得学习。就是那个融合得地方看得不太明白,不就是几个全连接层串在一起吗?为什么说得那么复杂, 单纯为了讲故事夸大其词吗?