Rapid-Object-Detection-using-a-Boosted-cascade-of-simple-features
简介
文章是2001年发表的,是一篇很经典的Object Detection的文章,而文章的亮点就在于使用了”Integral Image“计算Haar-like特征,从而加速了计算;此外,文章提出利用级联的方式分类,将很多非脸特征在前面剔除了,减少了大量的计算。文章采用Adaboost训练弱分类器组成强分类器,使得分类精度也很不错,而最大的两点就是其速度在当时也是非常快的。
Haar-like Features
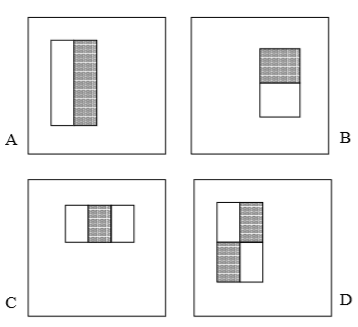
文章使用的haar特征是下面四种,也就是白色区域的像素值与黑色区域像素值之差。其中,C图和D图先分别把黑色、白色区域像素值相加,然后相减。文章提到,使用24*24的滑窗,得到的特征数量超过180,000。
Integral Image
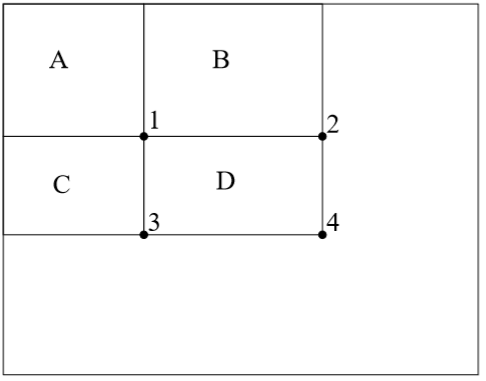
其实理解起来很简单,就是计算某个矩形区域内的像素值的和,比如下面这个图,我们要计算D区域的像素值的和,那我们就可以用s4(表示4点之前的所有像素和,后面一样)-s2-s3+s1计算得到,这样又什么好处呢?减少重复计算。比如算上图中的C类型的特征时,本来要算10点的求和值,但是由于有四个点时重用点,所以只需要算8点。
Adaboost 算法
”三个臭皮匠顶个诸葛亮“,我理解的Adaboost算法有两个很重要的点,是样本的权重,另一个是分类器的权重,Adaboost算法做的就是先给每个样本分配一个平均权重(样本概率分布),然后根据每个特征训练专门识别这个特征的分类器,这些分类器都是若分类器,但是对某一特征的分类能力很强,但是训练过程中肯定也会出现分错的样本,这时候我们就把分错的样本的权重增加,把分对的分类器的权重增加,进行迭代,前者是为了更好的训练错误率大的样本,后者是为了提高分类器的准确率。然后把弱分类器根据权重线性相加,组合起来就是一个强分类器,我们最终根据强分类器的计算结果来进行分类。
算法流程

本文应用

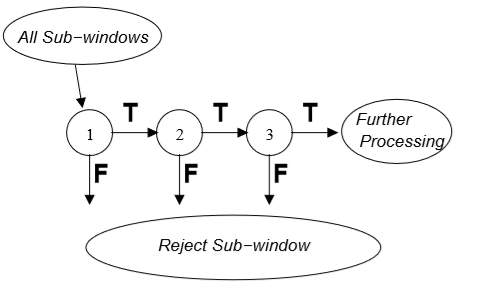
Attentional Cascade
我理解的就是在最级联的最前面放一些能够明显区别非脸特征的分类器,这样如果不是脸部特征,后面的计算就可以不用计算了,直接下一个window。
Learning Results
前两张图是通过adaboost得到的分类器中权重最大的两个特征,按照我的理解,这两个特征在原图中的反映就是人的眼部的亮度和脸部的亮度不同,以及人的两眼之间的亮度与中间鼻梁部分的亮度不同。
