本文为一篇神经机器翻译的文章,发表在2019AAAI会议上,主要提出一种深度转移网络(Deep Transition),结合多头注意力解决循环神经网络中同一层不同时刻之间shallow的问题。
Encoder-Decoder为主的神经网络结构在机器翻译任务中有重大的突破,先前诸多工作都是以Encoder-Decoder为主,一般地Encoder是用于对原始句子source sentence进行特征表示,将句子映射为一定长度的向量;Decoder则是根据对应的向量以及当前已经预测的单词来生成下一个单词,即所谓的自回归模型。Decoder部分的主要目标则是:
p
(
y
∣
x
)
=
∏
t
=
1
m
p
(
y
t
∣
y
<
t
,
x
;
θ
)
p(\mathbf{y}|\mathbf{x}) = \prod_{t=1}^{m}p(y_t|\mathbf{y}_{<t},\mathbf{x};\theta)
p ( y ∣ x ) = t = 1 ∏ m p ( y t ∣ y < t , x ; θ )
通常Encoder和Decoder可以选择CNN、RNN、Transformer等模型。本文作者认为以RNN为代表的递归神经机器翻译(RNMT)具有更大的潜力。不过在很多RNN为主的表征过程中,通常通过堆叠多层RNN来挖掘句子信息,换句话说,整个递归过程中,每一个时刻的深度可以通过多层RNN实现,但是对于时刻之间的转移却非常浅。这一问题在许多其他先前工作中也被提出。例如LAU( Linear Associative Unit)提出降低递归单元内部的梯度路径。
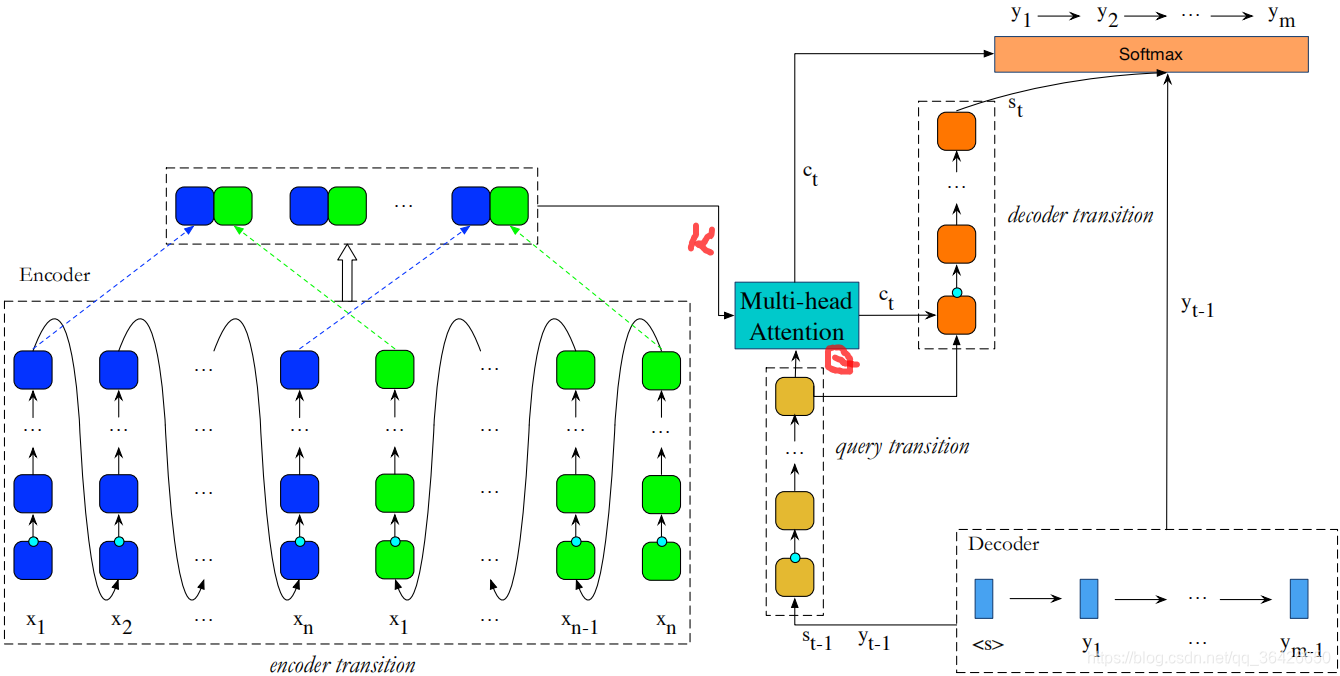
本文提出一种以GRU为主的深度转移递归神经网络模型,Encoder和Decoder均采用该网络模型分别用于编码和解码,Encoder和Decoder通过多头注意力模型相连。
GRU 是一种带有门控机制的RNN网络。其输入包括当前时刻
t
t
t
t
−
1
t-1
t − 1
t
t
t
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
^
t
h_t=(1-z_t)\odot h_{t-1}+z_t\odot \hat{h}_t
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ^ t
h
^
t
=
t
a
n
h
(
W
x
h
x
t
+
r
t
⊙
(
W
h
h
h
t
−
1
)
)
\hat{h}_t = tanh(W_{xh}x_t+r_t\odot (W_{hh}h_{t-1}))
h ^ t = t a n h ( W x h x t + r t ⊙ ( W h h h t − 1 ) )
r
t
=
σ
(
W
x
r
x
t
+
W
h
r
h
t
−
1
)
r_t = \sigma(W_{xr}x_t + W_{hr}h_{t-1})
r t = σ ( W x r x t + W h r h t − 1 )
z
t
=
σ
(
W
x
z
x
t
+
W
h
z
h
t
−
1
)
z_t = \sigma(W_{xz}x_t + W_{hz}h_{t-1})
z t = σ ( W x z x t + W h z h t − 1 )
其中
h
t
−
1
h_{t-1}
h t − 1
h
^
t
\hat{h}_t
h ^ t
h
t
−
1
h_{t-1}
h t − 1
r
t
,
z
t
r_t,z_t
r t , z t
σ
\sigma
σ
T-GRU 是一种特殊的GRU,其不同于GRU的是其只有一个输入,且为隐状态,因此更新信息
h
^
t
\hat{h}_t
h ^ t
h
t
−
1
h_{t-1}
h t − 1
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
^
t
h_t=(1-z_t)\odot h_{t-1}+z_t\odot \hat{h}_t
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ^ t
h
^
t
=
t
a
n
h
(
r
t
⊙
(
W
h
h
h
t
−
1
)
)
\hat{h}_t = tanh(r_t\odot (W_{hh}h_{t-1}))
h ^ t = t a n h ( r t ⊙ ( W h h h t − 1 ) )
r
t
=
σ
(
W
h
r
h
t
−
1
)
r_t = \sigma(W_{hr}h_{t-1})
r t = σ ( W h r h t − 1 )
z
t
=
σ
(
W
h
z
h
t
−
1
)
z_t = \sigma(W_{hz}h_{t-1})
z t = σ ( W h z h t − 1 )
L-GRU 是带有对输入单词input embedding线性变换的“增强版”GRU,L即代表linear。其不同于GRU的在于其输入部分包括三个,前两个与GRU相同,第三个则为input embedding的线性变换
H
(
x
t
)
H(x_t)
H ( x t )
l
t
l_t
l t
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
^
t
h_t=(1-z_t)\odot h_{t-1}+z_t\odot \hat{h}_t
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ^ t
h
^
t
=
t
a
n
h
(
W
x
h
x
t
+
r
t
⊙
(
W
h
h
h
t
−
1
)
+
l
t
⊙
H
(
x
t
)
)
\hat{h}_t = tanh(W_{xh}x_t+r_t\odot (W_{hh}h_{t-1}) + l_t\odot H(x_t))
h ^ t = t a n h ( W x h x t + r t ⊙ ( W h h h t − 1 ) + l t ⊙ H ( x t ) )
r
t
=
σ
(
W
x
r
x
t
+
W
h
r
h
t
−
1
)
r_t = \sigma(W_{xr}x_t + W_{hr}h_{t-1})
r t = σ ( W x r x t + W h r h t − 1 )
z
t
=
σ
(
W
x
z
x
t
+
W
h
z
h
t
−
1
)
z_t = \sigma(W_{xz}x_t + W_{hz}h_{t-1})
z t = σ ( W x z x t + W h z h t − 1 )
l
t
=
σ
(
W
x
l
x
t
+
W
h
l
h
t
−
1
)
l_t = \sigma(W_{xl}x_t + W_{hl}h_{t-1})
l t = σ ( W x l x t + W h l h t − 1 )
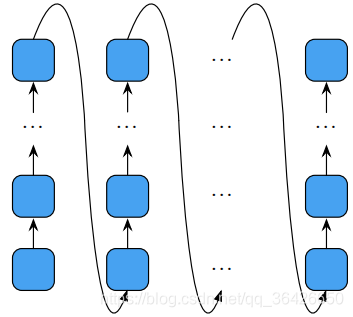
DTRNN主要在不同时刻之间添加深度的网络,相比stack RNN是在纵向加深,DTRNN则是横向加深。如图所示:
BiDeep RNN 。
如上图左,编码器为一个双向DTRNN,对于每一个时刻,先由L-GRU将上一时刻状态以及当前的input embedding和线性变换作为输入,其次逐个由T-GRU进行循环,假设DTRNN的深度为
L
s
L_s
L s
h
→
j
,
0
=
L
−
G
R
U
(
x
j
,
h
→
j
−
1
,
L
s
)
\overrightarrow{h}_{j,0} = L-GRU(\mathbf{x}_j,\overrightarrow{h}_{j-1,L_s})
h
j , 0 = L − G R U ( x j , h
j − 1 , L s )
h
→
j
,
k
=
T
−
G
R
U
k
(
h
→
j
,
k
−
1
)
\overrightarrow{h}_{j,k} = T-GRU_k(\overrightarrow{h}_{j,k-1})
h
j , k = T − G R U k ( h
j , k − 1 )
其中
k
∈
[
1
,
L
s
]
k\in [1,L_s]
k ∈ [ 1 , L s ]
C
=
{
[
h
→
j
,
L
s
,
h
←
j
,
L
s
]
}
C=\{[\overrightarrow{h}_{j,L_s},\overleftarrow{h}_{j,L_s}]\}
C = { [ h
j , L s , h
j , L s ] }
解码器部分包含query transition和decoder transition。假设两个部分的DTRNN深度分别为
L
q
L_q
L q
L
d
L_d
L d
s
t
,
0
=
L
−
G
R
U
(
y
t
−
1
,
s
t
−
1
,
L
q
+
L
d
+
1
)
s_{t,0} = L-GRU(\mathbf{y}_{t-1}, \mathbf{s}_{t-1, L_q+L_d+1})
s t , 0 = L − G R U ( y t − 1 , s t − 1 , L q + L d + 1 )
s
t
,
k
=
T
−
G
R
U
(
s
t
,
k
−
1
)
s_{t,k} = T-GRU(\mathbf{s}_{t, k-1})
s t , k = T − G R U ( s t , k − 1 )
其中
k
∈
[
a
,
L
q
]
k\in [a,L_q]
k ∈ [ a , L q ]
t
−
1
t-1
t − 1
y
t
\mathbf{y}_t
y t
c
t
=
M
u
l
t
i
−
H
e
a
d
A
t
t
e
n
t
i
o
n
(
C
,
s
t
,
L
q
)
c_t=Multi-HeadAttention(C,s_{t,L_q})
c t = M u l t i − H e a d A t t e n t i o n ( C , s t , L q )
多头注意力模型与Transformer的一致,这里不细提。其输出部分则作为decoder transition的输入,另外decoder transition的输入还包括query transition最后一层的T-GRU的输出:
s
t
,
L
q
+
1
=
L
−
G
R
U
(
c
t
,
s
t
,
L
q
)
s_{t,L_q+1} = L-GRU(c_t, s_{t,L_q})
s t , L q + 1 = L − G R U ( c t , s t , L q )
s
t
,
L
q
+
p
=
T
−
G
R
U
(
s
t
,
L
L
q
+
p
−
1
)
s_{t,L_q+p} = T-GRU(s_t, L_{L_q+p-1})
s t , L q + p = T − G R U ( s t , L L q + p − 1 )
其中
p
∈
[
2
,
L
q
+
1
]
p\in [2,L_q+1]
p ∈ [ 2 , L q + 1 ]
因此总的来说,在解码过程中,query transition是为了将上一时刻的预测词进行一次深度编码为查询器,用这个查询器从编码器中查询下一个可能的词的隐特征,查询的过程则是使用多头注意力实现alignment对齐,然后通过decoder transition将这个词的隐特征解码并通过full connection映射到标签分布上。
作者在(中文-英文),(英文-德文),(英文-法文)三个任务上进行了实验,同时实施消融实验(Ablation)验证L-GRU和T-GRU以及结合使用的效果。作者在实验中还使用了dropout用于防止过拟合,label smoothing做标签平滑处理(不采用0-1独热编码,对于其他类都有非0的很小的概率),层级正则化以及位置表征。
【1】 Deep architectures for neural machine translation