HyperFace: ADeep Multi-task Learning
Framework for Face Detection, Landmark
Localization, Pose Estimation, and Gender
Recognition
概要
论文采用多任务学习的方法,实现了利用CNN 同时做人脸检测,关键点定位,姿态估计和性别预测4项任务。利用多任务学习同时完成几项人脸检测任务是该篇论文主要亮点。
简介
这里提了一个概念——hyperfeatures,其实含义就是指提取多个卷积层的特征做多任务学习,之所以要这么做,是因为论文层数较浅的卷积层包含较多的细节、局部信息,更适合于关键点定位和姿态估计,对于层数较深的卷积层则包含较多的整体信息,可以用于人脸检测和性别预测。
然而由于多个卷积层包含的信息十分庞大,难以直接拿来做多任务学习,所以需要一种特征融合(feature fusion)技术用以将多层的特征信息线性或非线性的结合到一块子空间上。论文构建了一个单独的fusion-CNN 层用来复用hyperfeatures,利用该fusion-CNN输出的特征做多任务学习。
主要的贡献有如下四点:
1):提出了一种新的CNN框架,可以复用中间层特征做多任务学习。
2):提出了两种后处理方法,迭代区域选择和基于关键点的NMS,可以有效提示整体性能。
3):对比了采用单任务学习和多任务学习下的R-CNN性能差别。
4):4种任务在各非约束评测集上都取得了突破性结果。
HYPERFACE
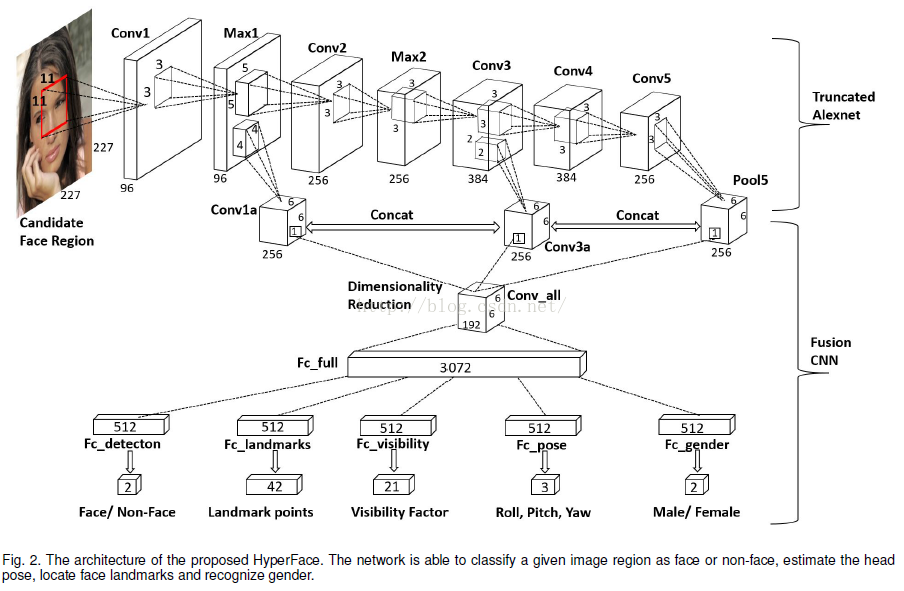
算法主要包含三个模块,第一个模块从图像中产生候选区并resize到227*227输入到网络;第二个模块是CNN,如上图所示,做二分类,分类出是否为人脸,如果是人脸则输出关键点、姿态、性别预测结果;第三个模块是一个后处理,包含候选区迭代和基于关键点的NMS。
HYPERFACE架构
在设计网络架构时,有两个前提,分别是:
1、 CNN特征分布于各层中,浅层网络反映局部特征信息,适于关键点检测和姿态估计,深层网络反映全局特征信息,适于检测和分类。
2、 多任务协同学习被证明比单任务独立学习更加有效。
基于这两点,设计了HYPERFACE这种网络结构,由于相邻层网络包含着较多的重复信息,所以在采样特征时,间隔选择网络提取特征即可。
作者设计的网络基于AlexNet,提取的中间网络层分别是max1,conv3,pool5,由于三个层的特征维度不同,所以不能直接将其拼接在一起,作者设计了conv1a和conv3a卷积层卷积Max1和Conv3的特征,获得归一化的统一特征维度,最后和pool5拼接在一起,得到6*6*768维度的feature maps,由于特征庞大,又增加了卷积核为1*1的Conv_all卷积层将特征降维到6*6*192[1],之后是一个全连接层,输出3072维的特征向量,之后将该特征向量分为5个部分,每一个512维,用于分别学习不同任务。在每一个全连接层后部署非线性ReLU激活函数。为了不丢失局部信息,在fusion网络中不使用任何pooling操作。
训练过程
作者选择AFLW作为训练集,并从中抽取1000张作为测试集,采用了多种损失函数用以训练不同任务:
人脸检测
作者使用Select Search用以生成候选区,IOU大于0.5时为正例(l=1),小于0.35的作为负例(l=0),使用softmax损失函数。

p表示该区域是人脸的概率,从Fc_detection获取得到。
关键点定位
AFLW包含21个关键点信息,IOU大于0.35的作为正例被采用,所有关键点坐标被归一化,采用相对值,映射函数为:
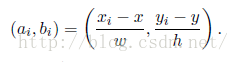
xi,yi为关键点坐标,x,y为人脸中心的坐标,w,h为人脸宽高,对于缺失的关键点,被设置为(0,0)。使用Euclidean损失函数,如下所示:

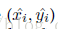
可见预测
作者这里还训练了一个用于预测关键点是否可见的分类器,采用IOU大于0.35的候选框作为正例,使用Euclidean损失函数,如下所示:
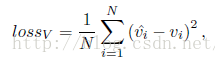
vi表示该候选框,第i个关键点是否可见的真值,1为可见,反之为0, 
姿态估计
使用Euclidean损失函数训练roll(p1),pitch(p2),yaw(p3),IOU大于0.5的为正例:
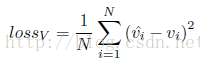
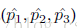
性别预测
IOU大于0.5的作为正例,损失函数为:
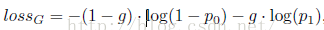
g=0表示male,为1表示female。(p0,p1)是一个2维预测向量,由网络计算得到。
全局损失函数
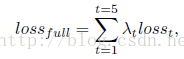
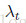
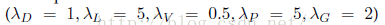
,分别对应上面5项。
Testing
这里主要讲两个点,Iterative Region Proposals(IRP)和Landmarks-based Non-MaximumSuppression(L-NMS)。
IRP
作者先指出了Fast_SS(作者使用的一种Selective Search的改进算法)的不足,其不能准确定位一些噪声较大的人脸,导致其在检测过程中因分数过低而被漏检。于是,作者采用了一种新的策略,使用FaceRectCalculator[2](应该是一种借助关键点信息生成人脸框的工具)借助关键点信息产生候选区域。在网络中预测一轮后,再利用新的关键点信息生成新的人脸框,迭代该过程。论文设置的迭代次数为1,伪代码如下所示:

L-NMS
跟其他NMS算法的不同就是不以人脸框坐标作为参数,而是以关键点中的最小四个角坐标作为参数,作者觉得这样的话更加人脸紧凑,可以避免相邻脸被合并或漏检等情况。伪代码如下:

NMS取top-k的结果,人脸框选择得分最大的,其余几项选择top-k的中值,也就是说,最终结果由top-k决定的投票结果,作者设置k为5.
Runtime
8核CPU加泰坦XGPU的配置也只能达到3s一张的水平,其中有2s用在selectivesearch上,但是作者指出,一次forward pass仅需0.2s,但是这速度依然够慢了。
我的心得:这篇论文很难付诸应用,因为其速度实在难以令人接受,其亮点在于中间层特征的利用和多任务学习,这两点相辅相成,往往比单任务学习可以取得更好的效果。
关于作者指出selective search耗费了太长时间,其实faster r-cnn已经解决了该问题,借鉴faster r-cnn的RPNs网络,其实速度可以提升不少。
[1] .C. Szegedy, W. Liu, Y. Jia, P.Sermanet, S. Reed, D. Anguelov,D. Erhan, V. Vanhoucke, and A. Rabinovich. Goingdeeper withconvolutions. CoRR, abs/1409.4842, 2014.
[2] . M. Kostinger, P. Wohlhart, P. Roth,and H. Bischof. Annotated facial landmarks in the wild: A large-scale,real-world database for facial landmark localization. In IEEE InternationalConference on Computer Vision Workshops, pages 2144–2151, Nov 2011.