论文:Collaborative Learning for Weakly Supervised Object Detection
论文链接:https://arxiv.org/abs/1802.03531
弱监督目标检测(weakly supervised object detection)是指不需要框标注,仅通过图像级标签就能做目标检测。这方面的研究出发点主要是框标注的成本太高,而图像级标签相对容易获得,因此希望借助图像级标签做目标检测。这篇IJCAI2018的文章基于WSCL(weakly supervised collaborative learning)提出WSCDN(weakly supervised collaborative detection network),该算法同时训练一个弱监督模型和一个强监督模型进行目标检测,弱监督模型采用类似WSDDN的结构,通过图像标签进行训练。强监督模型采用类似Faster RCNN的结构,因为对于强监督模型而言没有监督信息,所以作者引入prediction consistency loss约束强监督模型和弱监督模型的输出。
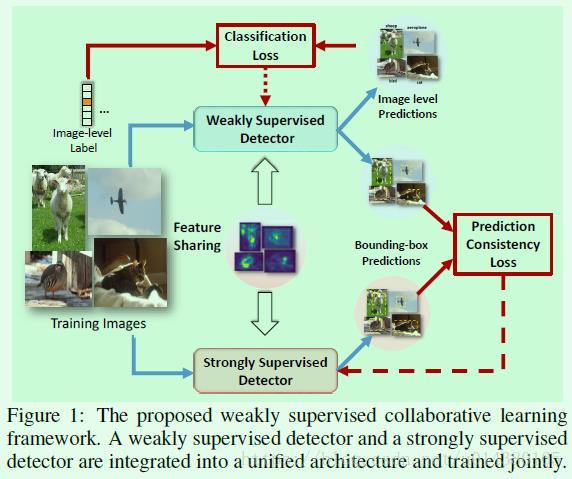
Figure1是WSCL(weakly supervised collaborative learning)的示意图,主要包含weakly supervised detector(用DW表示)和strongly supervised detector(用DS表示)两个模块。DW可以直接训练,因为DW的监督信息是图像的标签。但是直接训练DS肯定是不行的,因为DS没有监督信息,但因为DS和DW的预测目标是一致的,所以设计了prediction consistency loss来约束DS和DW的输出。这两个模型是一起训练的,而且因为两个模型的训练目标类似,所以二者之间有部分网络特征是共享的。
假设训练数据如下式子所示。N表示训练样本数量,xn表示第n个样本,也就是一张图像,yn表示第n个样本的标签,yn是一个1*C的向量,C表示类别数,因此输入图像xn中包含哪几个类别,则yn对应类别位置的数值就为1,否则为0。
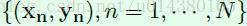
模型的预测任务可以用下面公式表示,B表示region proposal的数量,对于第i个region proposal x(i)而言,pi表示x(i)属于每个类别的概率,因此pi是一个向量;ti表示x(i)的四个坐标相关的信息,因此ti是一个长度为4的向量。
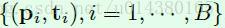
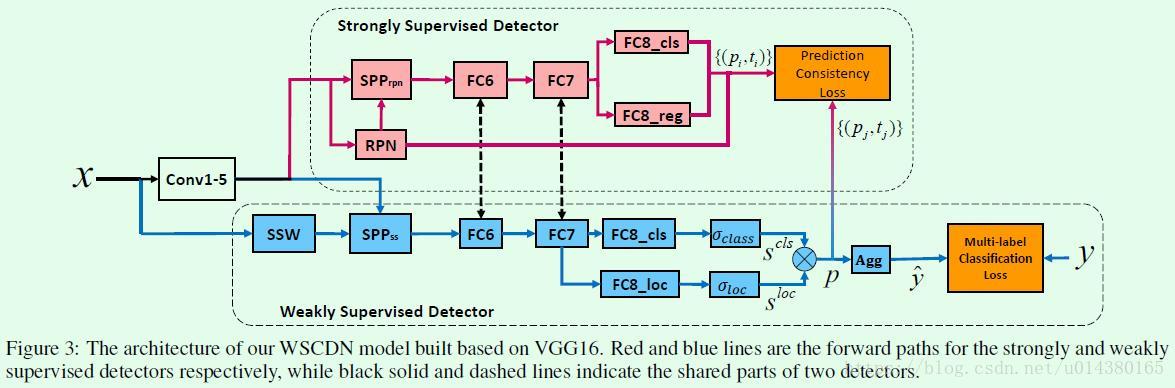
Figure3是WSCDN(weakly supervised collaborative detection network)的示意图,主要包含weakly supervised detector(用DW表示)和strongly supervised detector(用DS表示)两个模块。
DW模块(蓝色区域)主要包含3个部分:1、从图像输入到FC层。这一部分是基于预生成的region proposal提取特征。具体而言,SSW代表的就是生成region proposal的过程,SPPss是类似ROI Pooling的过程。2、FC8_cls和FC8_loc两条支路,由全连接层后接softmax层实现。其中FC8_cls支路用于计算每个region proposal x(j)属于每个类别c的概率得分sclsjc,FC8_loc支路用于计算每个region proposal x(j)属于每个类别c的位置得分slocjc,这一部分相当于约束region proposal的坐标准确率。3、基于前面两个支路的输出计算每个proposal的检测得分pjc,这个检测得分就融合了每个proposal的类别得分和位置得分。然后将同一个类别下的每个proposal得分累加作为这张图包含该类别的预测得分y^c,这两个计算过程如公式1所示,Bw表示region propsoal的数量。因此DW模块最后做的是一个多标签的分类,也就是说一张图有多个类别标签。
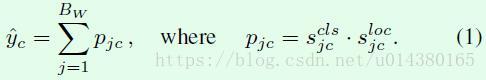
DS模块(红色区域)基本上采用Faster RCNN的思路,比如用RPN网络生成region proposal,另外DS的大部分网络特征都和DW共享。因为没有框的监督信息,所以可以看到实际的监督信息是基于DW的输出{(pj, tj)},其中pj是一个长度为c的向量,每个值用pjc表示,可以通过前面的公式1得到;tj是region proposal的4个坐标相关的值。DS模块的输出用{(pi, ti)}表示,含义同理。
既然两个模块要一起训练,就要牵扯到损失函数的问题。
DW模块损失函数采用的是交叉熵损失函数,如公式2所示。yc的值要么1要么0,表示c这个类别的物体是否出现在该图像中,y^c则表示DW模块的输出,也就是前面公式1计算的结果。

DS模块引入prediction consistency loss,如公式3所示。
该损失函数主要包含3个部分:1、CPinter表示DW和DS模块关于框类别预测的交叉熵损失函数,其中pjc是DW模块的输出,pic是DS模块的输出,c的遍历值从1到C,表示具体类别;j的遍历值从1到BW,表示DW模块的第几个region proposal;i的遍历值从1到BS,表示DS模块的第几个region proposal。这一部分保证了两个模块的输出趋于一致,和整个损失函数名称prediction consistency loss对应。
2、CPinner表示DS模块内部关于框预测类别的交叉熵损失函数。增加这一部分的原因是DW模块在训练起始时输出噪声比较大,因为增加一个DS模块的内部约束有利于训练初期的稳定。同时这部分用系数(1-β)来约束,和第一部分的系数β对应,实验中β默认取0.8。
3、CLinter表示DS和DW模块关于框坐标预测的损失函数,其中R() 表示smooth L1损失函数,同时乘以权重pjc。最后一个权重参数Iij是一个0、1值,假如region proposal x(i)和x(j)的IOU大于0.5,则Iij=1,否则Iij=0,这相当于刻画了两个模型输出的一致性,和整个损失函数名称prediction consistency loss对应。
因此整体上看和普通的目标检测算法(强监督)相比,这里的损失函数主要是引入了CPinner,其次是检测算法的监督信息采用基于弱监督算法的输出。
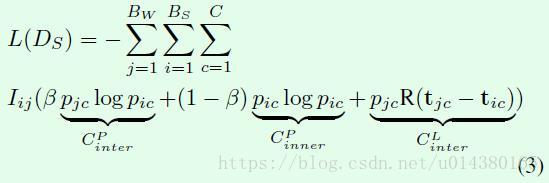
实验结果:
指标方面主要采用常见的mAP和CorLoc,从Table1在VOC 2007数据集上的效果来看,CLs的提升还是比较明显的。当然和强监督算法的效果差距还是比较大的。
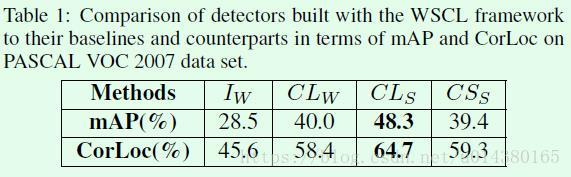
Table2是和其他算法在VOC 2007数据集上的效果对比。
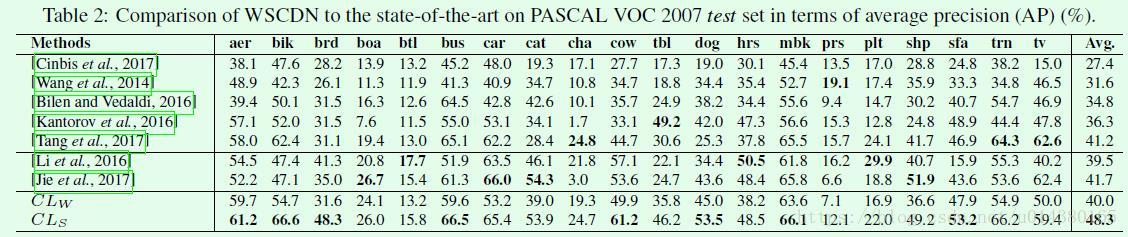
Table4是和其他算法在VOC 2012数据集上的效果对比。
