参考代码:暂无
1. 概述
介绍:transformer相关工作在车道线检测领域已经被证实是可行的,只不过大部分情况其耗时比较多,这是由于多数时候还构建了bev grid query去获取bev特征,而PETR这个方法直接在图像特征上加3D位置编码就快很多了。无论是显式构建bev特征还是直接在图像特征上加3D编码,它们都是拿对应特征与目标query做cross attention得到最后结果,而这篇文章的算法以lane query作为中间桥梁,分别与bev特征和图像特征做cross attention,得以将图像特征与bev特征关联起来,这样构建的检测器轻量且不同模态间信息能够相互关联。
2. 方法设计
2.1 整体pipeline
文章算法的结构见下图:
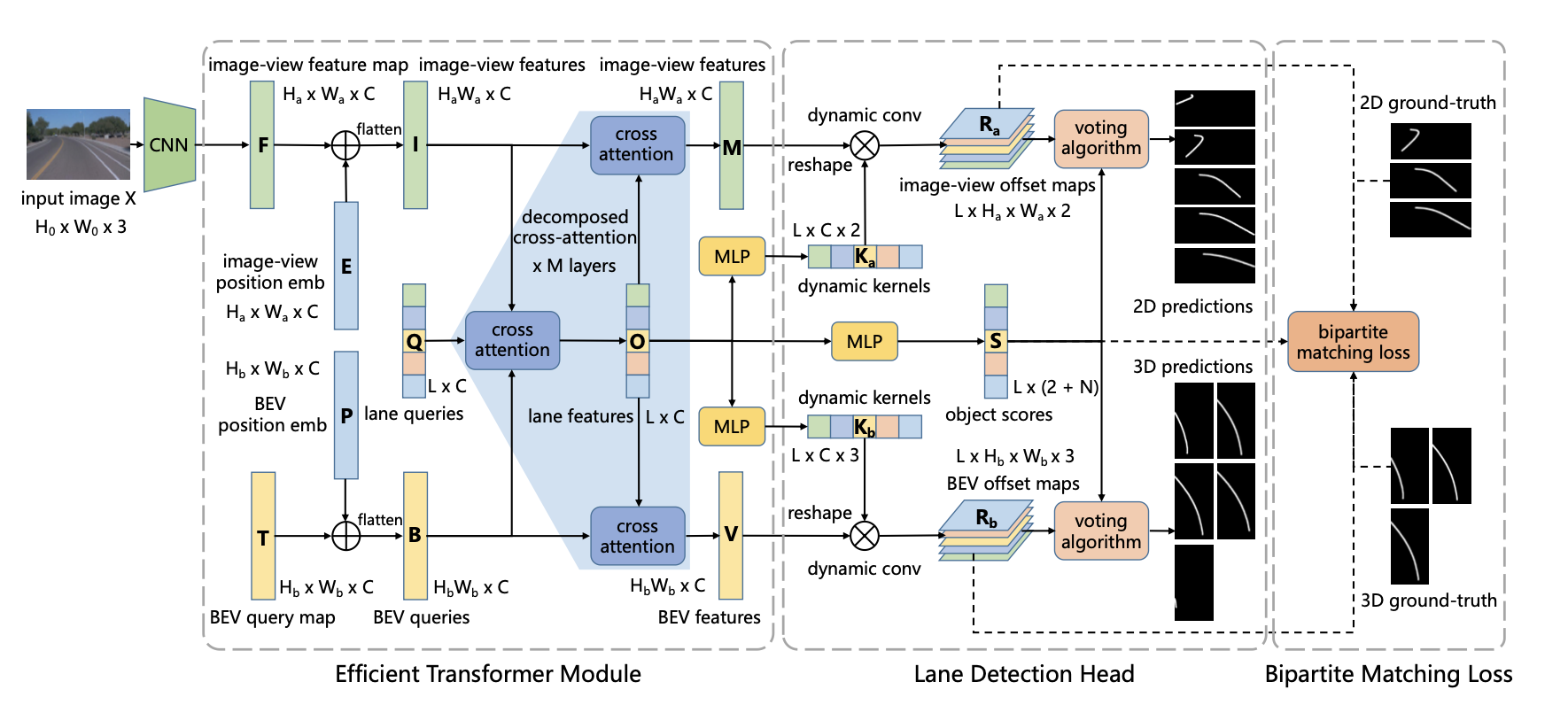
若是去掉最下面的分支文章的方法和PETR有点类似,但是这里添加了bev空间的位置编码,使得其能感知并预测bev下的分割结果。上述结构大体上可划分为如下几个部分:
- 1)lane query、图像特征、bev特征之间两两cross attention,在优化lane query表达的同时也提取和优化了bev特征
- 2)lane query得到的表达作为dynamic kernel参数分别与图像特征和bev特征做矩阵乘法得到对应感知结果。这些感知结果通过匈牙利匹配与GT关联,并计算loss反传
2.2 位置编码
图像域位置编码:
图像数据经过backbone之后得到特征 F ∈ R H a ∗ W a ∗ C F\in R^{H_a*W_a*C} F∈RHa∗Wa∗C,则在假定的深度bins下可以得到图像的相机视锥矩阵 G ∈ R H a ∗ W a ∗ D ∗ 4 G\in R^{H_a*W_a*D*4} G∈RHa∗Wa∗D∗4,而视锥矩阵可以依据相机内外参数变换到实际bev看空间下( p j p_j pj来自于 G G G):
p j ′ = K − 1 p j p_j^{'}=K^{-1}p_j pj′=K−1pj
上述的过程生成实际空间视锥表达 G ′ ∈ R H a ∗ W a ∗ D ∗ 4 G^{'}\in R^{H_a*W_a*D*4} G′∈RHa∗Wa∗D∗4,同时通过网络预测的方式得到深度先验表达 D ∈ R H a ∗ W a ∗ D D\in R^{H_a*W_a*D} D∈RHa∗Wa∗D,则图像域的位置编码被描述为:
E u v = [ ∑ d = 1 D D u v d ( G u v d ′ W 1 + b 1 ) ] W 2 + b 2 E_{uv}=[\sum_{d=1}^DD_{uvd}(G_{uvd}^{'}W_1+b_1)]W_2+b_2 Euv=[d=1∑DDuvd(Guvd′W1+b1)]W2+b2
其中, W 1 ∈ R 4 ∗ C / 4 , b 1 ∈ R C / 4 , W 2 ∈ R C / 4 ∗ C , b 2 ∈ R C W_1\in R^{4*C/4}, b_1\in R^{C/4},W_2\in R^{C/4*C}, b_2\in R^{C} W1∈R4∗C/4,b1∈RC/4,W2∈RC/4∗C,b2∈RC。
bev特征位置编码:
对于bev特征 T ∈ R H b ∗ W b ∗ C T\in R^{H_b*W_b*C} T∈RHb∗Wb∗C在给定bev特征空间到真实车体空间的转换矩阵之后便可以得到bev特征的空间网格矩阵 H ∈ R H b ∗ W b ∗ Z ∗ 4 H\in R^{H_b*W_b*Z*4} H∈RHb∗Wb∗Z∗4,同时在 T T T上预测车体坐标下的高度分布 Z ∈ R H b ∗ W b ∗ Z Z\in R^{H_b*W_b*Z} Z∈RHb∗Wb∗Z。则bev处的位置编码描述为:
p x y = [ ∑ z = 1 Z Z x y z ( H x y z W 1 + b 1 ) ] W 2 + b 2 p_{xy}=[\sum_{z=1}^ZZ_{xyz}(H_{xyz}W_1+b_1)]W_2+b_2 pxy=[z=1∑ZZxyz(HxyzW1+b1)]W2+b2
其中,这里的 W 1 , b 1 , W 2 , b 2 W_1,b_1,W_2,b_2 W1,b1,W2,b2的维度与图像域的位置编码一致。
2.3 decomposed cross attention
定义lane query、图像特征、bev特征分别为 Q ∈ R L ∗ C , I ∈ R H a W a ∗ C , B ∈ R H b W b ∗ C Q\in R^{L*C},I\in R^{H_aW_a*C},B\in R^{H_bW_b*C} Q∈RL∗C,I∈RHaWa∗C,B∈RHbWb∗C,则lane query的更新形式为(更新之后的lane query使用 O ∈ R L ∗ C O\in R^{L*C} O∈RL∗C表示):
O i = Q i + ∑ j = 1 H a W a f o ( Q i , I j ) g o ( I j ) + ∑ k = 1 H b W b f o ( Q i , B k ) g o ( B k ) O_i=Q_i+\sum_{j=1}^{H_aW_a}f_o(Q_i,I_j)g_o(I_j)+\sum_{k=1}^{H_bW_b}f_o(Q_i,B_k)g_o(B_k) Oi=Qi+j=1∑HaWafo(Qi,Ij)go(Ij)+k=1∑HbWbfo(Qi,Bk)go(Bk)
其中, g o g_o go代表的是一个不带bias的全连阶层,而attention weight则是由 f o f_o fo得到的:
f o ( Q i , I j ) = e x p ( Q i T W θ T W ϕ I j ) ∑ j = 1 H a W a e x p ( Q i T W θ T W ϕ I j ) f_o(Q_i,I_j)=\frac{exp(Q_i^TW_\theta^TW_\phi I_j)}{\sum_{j=1}^{H_aW_a}exp(Q_i^TW_\theta^TW_\phi I_j)} fo(Qi,Ij)=∑j=1HaWaexp(QiTWθTWϕIj)exp(QiTWθTWϕIj)
其中,权重 W θ , W ϕ ∈ R C ∗ C W_\theta,W_\phi \in R^{C*C} Wθ,Wϕ∈RC∗C。
得到新一层的lane query表达之后需要更新bev特征了:
V i = B i + ∑ j = 1 L f v ( B i , O j ) g v ( O j ) V_i=B_i+\sum_{j=1}^Lf_v(B_i,O_j)g_v(O_j) Vi=Bi+j=1∑Lfv(Bi,Oj)gv(Oj)
同样的对于图像特征也进行更新:
M i = I i + ∑ j = 1 L f m ( I i , O j ) g m ( O j ) M_i=I_i+\sum_{j=1}^Lf_m(I_i,O_j)g_m(O_j) Mi=Ii+j=1∑Lfm(Ii,Oj)gm(Oj)
这里将不同的attention机制进行比较,其中original和decomposed attention它们的模块见下图所示:
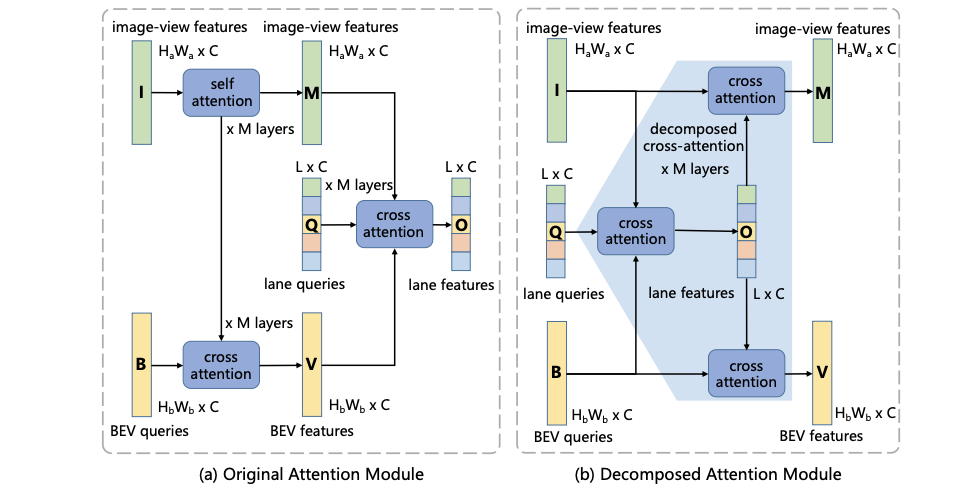
对于IPM-based attention则参考persformer中的实现,那么这三种不同类型的attention性能如何呢?见下表:

2.4 网络loss与infer
经过优化之后的lane query会经过3个MLP网络得到3个输出:图像域和bev域dynamic kernel,以及objectness S S S。dynamic kernel与对应维度特征运算得到对应的预测结果 R R R,之后用这些结果计算loss。
objectness loss:
L o b j ( Y i , Y j ∗ ) = − l o g ( S i 1 ) L_{obj}(Y_i,Y_j^{*})=-log(S_{i1}) Lobj(Yi,Yj∗)=−log(Si1)
classification loss:
L c l s ( Y i , Y j ∗ ) = − ∑ k = 0 N − 1 S j ( k + 2 ) ∗ ⋅ l o g ( S j ( k + 2 ) ) L_{cls}(Y_i,Y_j^{*})=-\sum_{k=0}^{N-1}S_{j(k+2)}^{*}\cdot log(S_{j(k+2)}) Lcls(Yi,Yj∗)=−k=0∑N−1Sj(k+2)∗⋅log(Sj(k+2))

offset loss:
L o f f s e t ( Y i , Y j ∗ ) = 1 H a W a ∑ m = 0 H a − 1 ∑ n = 0 W a − 1 ∣ ∣ R a i m n − ( R a i m n ) ∗ ∣ ∣ 1 + 1 H b W b ∑ m = 0 H b − 1 ∑ n = 0 W b − 1 ∣ ∣ R b i m n − ( R b i m n ) ∗ ∣ ∣ 1 L_{offset}(Y_i,Y_j^{*})=\frac{1}{H_aW_a}\sum_{m=0}^{H_a-1}\sum_{n=0}^{W_a-1}||R_a^{imn}-(R_a^{imn})^{*}||_1+\frac{1}{H_bW_b}\sum_{m=0}^{H_b-1}\sum_{n=0}^{W_b-1}||R_b^{imn}-(R_b^{imn})^{*}||_1 Loffset(Yi,Yj∗)=HaWa1m=0∑Ha−1n=0∑Wa−1∣∣Raimn−(Raimn)∗∣∣1+HbWb1m=0∑Hb−1n=0∑Wb−1∣∣Rbimn−(Rbimn)∗∣∣1
在进行匈牙利匹配的时候匹配代价为:
L m a t c h ( Y i , Y j ∗ ) = λ o b j L o b j ( Y i , Y j ∗ ) + λ c l s L c l s ( Y i , Y j ∗ ) + λ o f f L o f f ( Y i , Y j ∗ ) L_{match}(Y_i,Y_j^{*})=\lambda_{obj}L_{obj}(Y_i,Y_j^{*})+\lambda_{cls}L_{cls}(Y_i,Y_j^{*})+\lambda_{off}L_{off}(Y_i,Y_j^{*}) Lmatch(Yi,Yj∗)=λobjLobj(Yi,Yj∗)+λclsLcls(Yi,Yj∗)+λoffLoff(Yi,Yj∗)
与GT匹配自然是选择最小的那个了:
arg min z z ^ = ∑ j = 1 N L m a t c h ( Y z ( j ) , Y j ∗ ) \argmin_z\hat{z}=\sum_{j=1}^NL_{match}(Y_{z(j)},Y_j^{*}) zargminz^=j=1∑NLmatch(Yz(j),Yj∗)
完成匹配之后整体的loss为:
l o s s = 1 M ∑ j = 1 M [ λ o b j L o b j ( Y z ( j ) , Y j ∗ ) + λ c l s L c l s ( Y z ( j ) , Y j ∗ ) + λ o f f L o f f ( Y z ( j ) , Y j ∗ ) + 1 L − M ∑ i ∉ C λ o b j L o b j ( Y i , ϕ ) loss=\frac{1}{M}\sum_{j=1}^M[\lambda_{obj}L_{obj}(Y_{z(j)},Y_j^{*})+\lambda_{cls}L_{cls}(Y_{z(j)},Y_j^{*})+\lambda_{off}L_{off}(Y_{z(j)},Y_j^{*})+\frac{1}{L-M}\sum_{i\notin C}\lambda_{obj}L_{obj}(Y_i,\phi) loss=M1j=1∑M[λobjLobj(Yz(j),Yj∗)+λclsLcls(Yz(j),Yj∗)+λoffLoff(Yz(j),Yj∗)+L−M1i∈/C∑λobjLobj(Yi,ϕ)
模型infer的后处理,类似于YOLO形式的object和offset获取,见bev部分的伪代码:

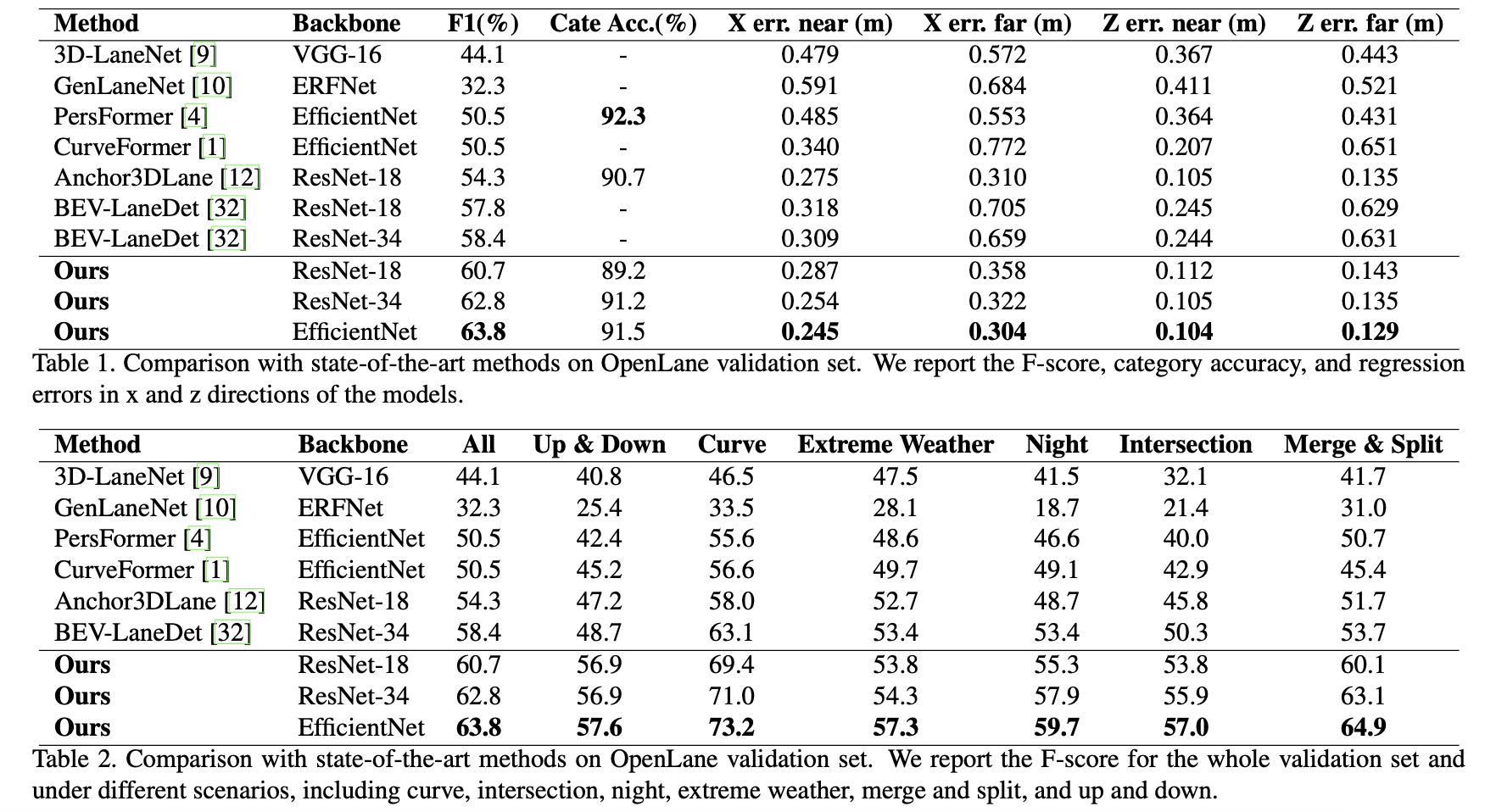
3. 实验结果
Openlane val上的性能比较和各工况下的性能表现: