Abstract
首先,本篇论文提出了一种加权双向特征金字塔网络(BiFPN),进行简单、快速的多尺度特征融合;其次,作者提出了一种复合尺度方法,同时统一调整所有主干、特征网络和box/类别预测网络的分辨率、深度和宽度。基于这些优化和更好的骨干,提出了一个目标检测算法称为Effificientdet.
1. Introduction
目标检测算法有两个挑战:
挑战1:高效的多尺度特征融合——FPN、PANet [26]、NAS-FPN [10]等研究在融合不同的输入特征时,只做了简单的融合,各部分特征对输出特征的贡献相等;然而,由于这些不同的输入特征具有不同的分辨率,他们对输出特征的重要性很可能是不同的。为了解决这一问题,作者提出了一种简单而高效的加权双向特征金字塔网络(BiFPN),该网络在重复应用自顶向下和自下向上的多尺度特征融合的同时,引入可学习权值来学习不同输入特征的重要性。
挑战2:模型缩放——虽然以前的工作主要依赖于更大的主干网络[24,35,34,10]或更大的输入图像尺寸[13,45]来获得更高的精度,但作者观察到,当考虑到精度和效率时,扩展特征网络和box/类预测网络也是至关重要的。作者提出了一种用于对象检测器的复合缩放方法,该方法联合扩展了所有主干、特征网络、box/类预测网络的分辨率/深度/宽度。
主干,即在backbone部分进行缩放,特征网络,即在neck(特征金字塔)进行缩放,box/类预测网络即对预测head也进行缩放
3. BiFPN
传统的自上而下的FPN在本质上受到单向信息流的限制。为了解决这个问题,PANet [26]添加了一个额外的自底向上的路径聚合网络。最近,NAS-FPN [10]采用神经结构搜索来搜索更好的跨尺度特征网络拓扑,但在搜索过程中需要数千小时的GPU,发现的网络不规则,难以解释或修改,如图2(c).所示。BiFPN做了两个方面的改进:(1)PANet进行特征融合时,是通过Concat的,一般高层和低层的特征贡献程度相同,BiFPN在特征融合时,通过一组可学习的归一化权重参数调整各层贡献程度。(2)BiFPN堆叠多层实现更高维度的特征融合。
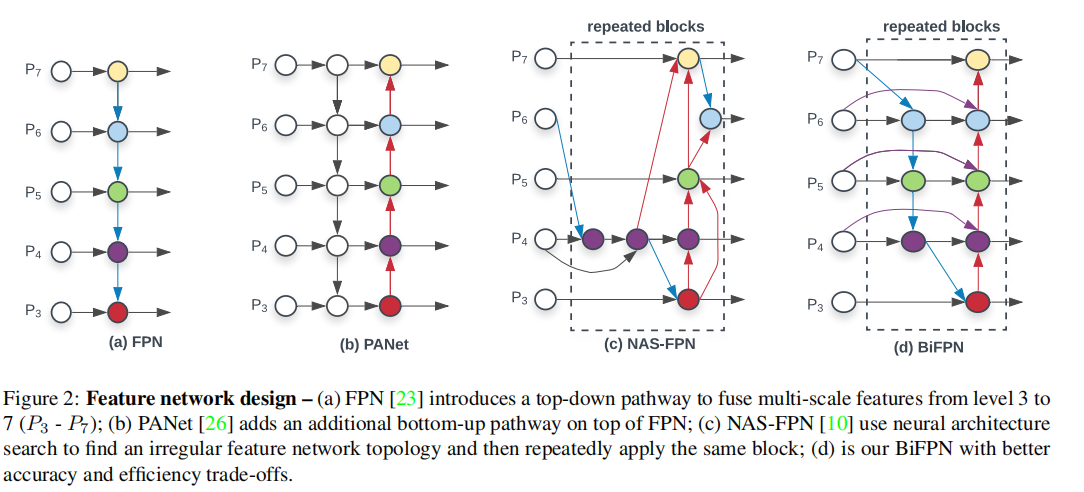
不同特征金字塔效果对比,这里,我们注意到,BiFPN与PANet构建上都是两条路径,但是PANet参数量更大,这是由于,作者为了保持参数量,在PANet前面使用了FPN的堆叠。

3.3. Weighted Feature Fusion
在权重上,作者使用标量权重,然而,由于标量权值是无界的,它可能会导致训练的不稳定性。因此,采用权重归一化来约束每个权重的值范围。
在权重归一化上,采用Softmax降低了推理速度,因此,作者采用简单的归一化操作:
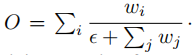
level的BiFPN特征融合示例:

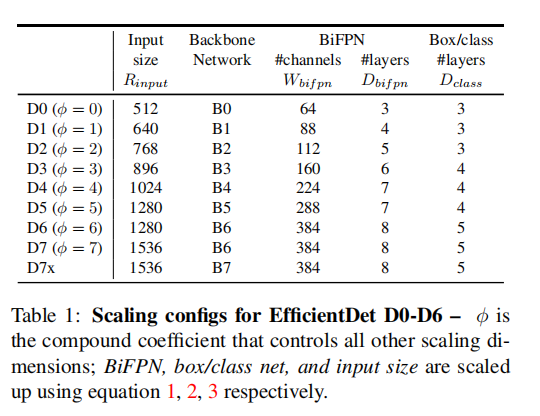
4. EffificientDet
EffificientDet在backbone、BiFPN、Box/class prediction network 均进行缩放,
使用EffificientNet-B0 to B6
BiFPN network
作者线性增加BiFPN深度(#层),因为深度需要四舍五入到小整数。对于BiFPN宽度(#通道),BiFPN宽度(#通道)呈指数增长,具体来说,选择最佳值1.35作为BiFPN宽度缩放因子。在形式上,BiFPN的宽度和深度按以下公式进行缩放:
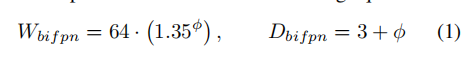
Box/class prediction network
将它们的宽度始终与BiFPN相同,但使用公式线性增加深度(#层):
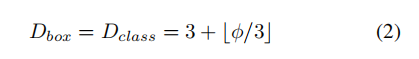
Input image resolution
使用方程线性增加分辨率:
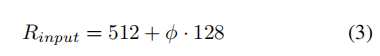
5. Experiments
5.1. EffificientDet for Object Detection 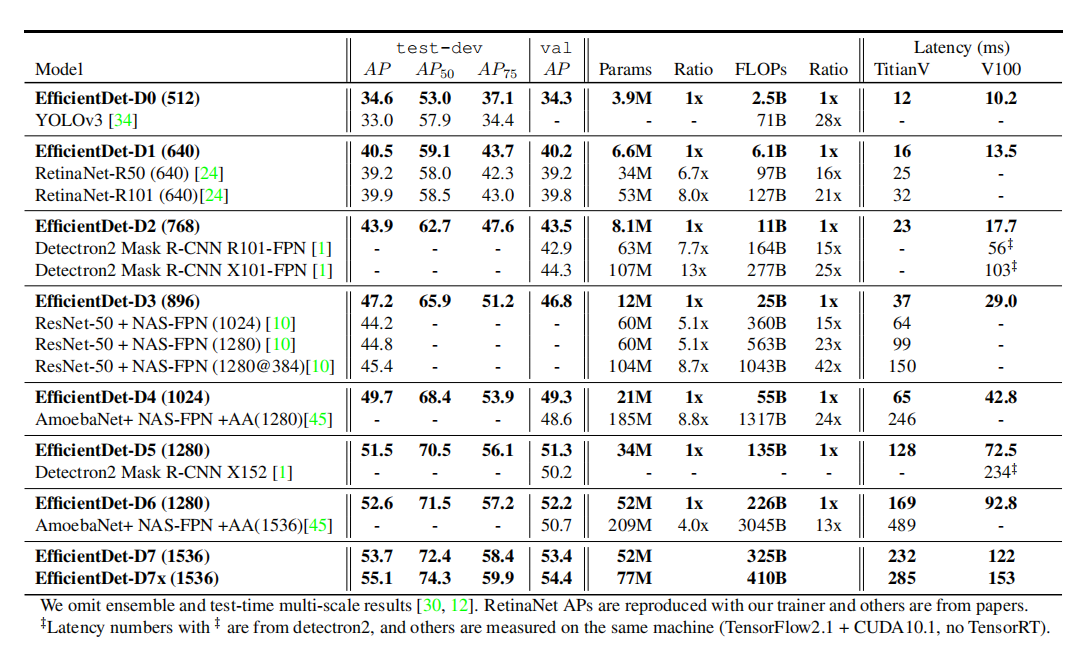
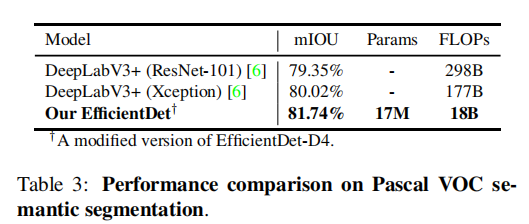
5.2. EffificientDet for Semantic Segmentation
6. Ablation Study
6.1. Disentangling Backbone and BiFPN
EffificientNet骨干和BiFPN对最终的最终模型都至关重要。

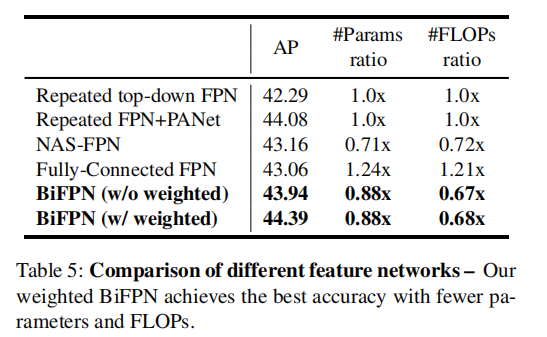
6.2. BiFPN Cross-Scale Connections
BiFPN实现了与repeated FPN+PANet相似的精度,但使用更少的参数和计算量。通过附加的加权特征融合,BiFPN进一步以更少的参数和计算量实现了最好的精度。
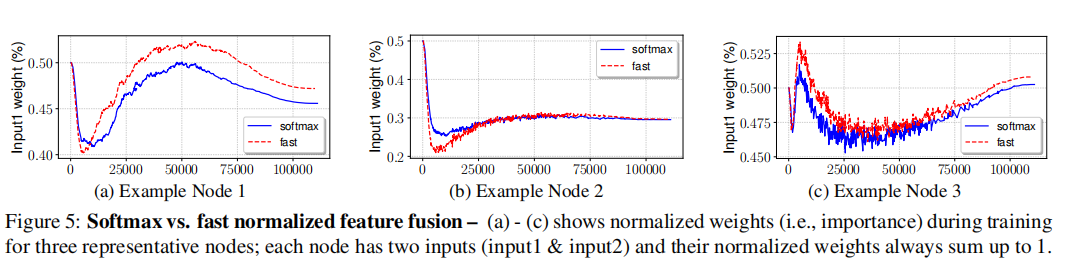
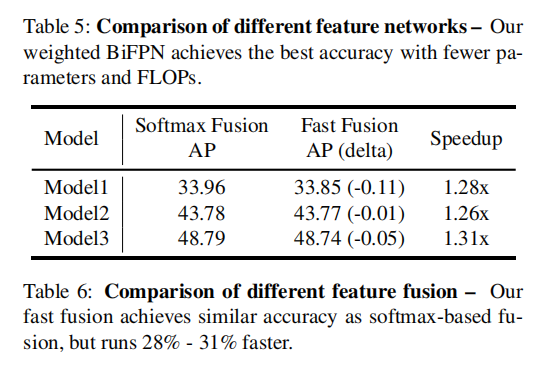
6.3. Softmax vs Fast Normalized Fusion
快速归一化融合方法实现了与基于softmax的融合相似的精度,但在gpu上运行速度快1.26x-1.31倍。
归一化的权值在训练过程中变化迅速,这表明不同的特征对特征融合的贡献不相等。尽管有快速的变化,快速归一化融合方法对所有三个节点总是显示出与基于softmax的融合非常相似的学习行为。