论文地址:EfficientDet
论文总结
本文是基于EfficientNet展开的检测网络,其提出了一种新的特征融合手段(BiFPN),以及检测器上的缩放方案(如EfficientNet一样的多维度组合缩放方案),可以得到一个高效率又高性能的网络。
BiFPN通过对FPN添加一个bottom-up的路径以及做了一些修改,之后又对每一个特征融合的特征添加了权重的影响,这与传统的相同大小feature map直接相加不同。
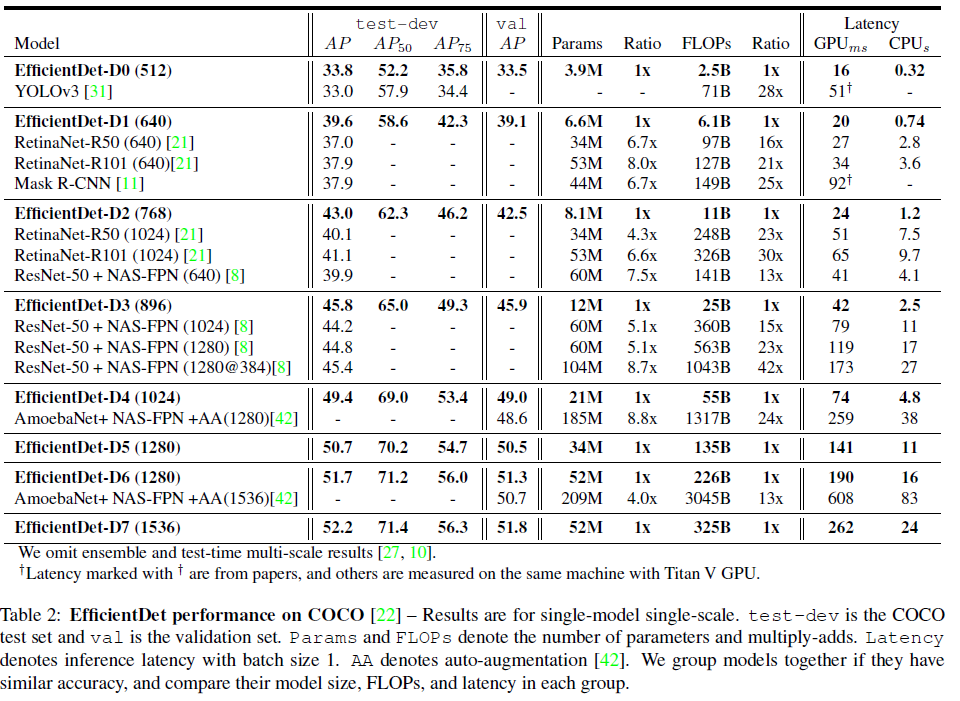
网络性能展示如下:

论文介绍
BiFPN是一个有效的双向的同尺度连接(cross-scale connections),如下图的(d)所示。

有效的跨尺度连接方案如下:
- 移除只有一个输入的边;作者认为如果一个结点只有一个输入,没有特征融合,则其可以认为是相对没那么重要的;
- 特征融合的时候添加多一个同一尺寸大小的输入,这样就可以在没有增加太多计算量的情况下融合更多的特征信息;
- 不像PANet只有一个top-down和一个bottom-up路径,EfficientNet将这个组合作为一个基本block,可重复多次来获得更高层次的特征融合。
同时,作者认为特征融合不同输入的权重应该不一样,所以本文提出增加学习特征融合的Input对应的weight。一般来说,增加权重有几种方式:(1)标量,即每一个输入对应一个标量的权重;(2)向量,即每一个输入的每一个channel都对应一个权重;(3)张量,即每一个元素都有其对应的权重。经过实验,作者发现标量的权重可以达到和向量、张量一样的效果。
但张量是无边界的,可能会带来训练的不稳定,所以作者打算通过归一化使得权重限制在 0 0 0~ 1 1 1之间。一开始使用softmax,但那会带来性能的降低(速度慢),后来直接用权值进行归一化 ∑ i w i ε + ∑ j w j \sum_i \frac{w_i}{\varepsilon+\sum_jw_j} ∑iε+∑jwjwi,也获得了差不多的结果;
一般特征融合之后会使用一个conv操作。为了进一步提升性能,EfficientDet使用depthwise conv用于特征融合后的操作。
网络架构
组合缩放
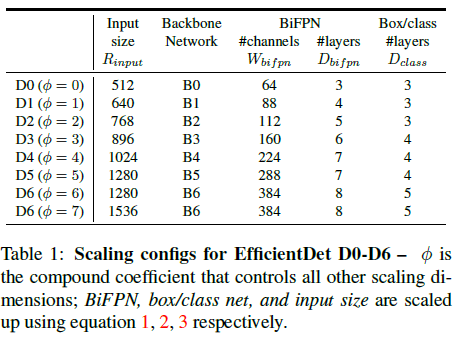
Backbone network使用EfficientNet一样的缩放策略,即EfficientNet-B0~B6,这样就可以简单利用ImageNet预训练好的checkpoint。
BiFPN network,宽度 W b i f p n W_{bifpn} Wbifpn(channel)使用指数增长的缩放: W b i f p n = 64 ∗ ( 1.3 5 ϕ ) W_{bifpn}=64*(1.35^\phi) Wbifpn=64∗(1.35ϕ)文中 ϕ \phi ϕ在{1.2,1.25,1.3,1.35,1.4,1.45}中使用网格搜索,最终选择使用1.35作为width的缩放系数;深度 D b i f p n D_{bifpn} Dbifpn(layer)使用线性增长的方案: D b i f p n = 3 + ϕ D_{bifpn}=3+\phi Dbifpn=3+ϕ Box/class prediction network,使用的channel数与BiFPN一致,但layers数以如下方式增长: D b o x = 3 + ⌊ ϕ ⌋ D_{box}=3+\lfloor \phi \rfloor Dbox=3+⌊ϕ⌋ Input image resolution,因为网络最后下采样 128 128 128,所以以 128 128 128作为系数: R i n p u t = 512 + ϕ ∗ 128 R_{input}=512+\phi*128 Rinput=512+ϕ∗128
需要注意的是,缩放方案是基于启发式的,但并不是最优的。

论文实验
损失函数使用Focal Loss,其系数 α = 0.25 \alpha=0.25 α=0.25, γ = 1.5 \gamma=1.5 γ=1.5。使用RetinaNet的训练预处理:多分辨率crop/scale 和 flip;没有使用自动增强(数据增强)策略。
性能对比:

softmax归一化和普通归一化的实验对比:


从图5中的三个随机结点的权重学习可以看出,两种方案的学习曲线是相似的。最后的性能(AP)也相差不大,却有不小的速度差异。