《NEURQURI: NEURAL QUESTION REQUIREMENT INSPECTOR FOR ANSWERABILITY PREDICTION IN MACHINE READING COMPREHENSION》
这篇文章是Samsung research and South Korea发表在2020 ICLR上的。主要是针对机器阅读理解当中的不可回答问题,提出了一个自己的模块和一种新的损失函数的计算方式。并且在三个数据集SQuAD 2.0, NewsQA and MS MARCO进行了验证,得到了一致性的改善。
分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
这篇文章的一个动机就是说考虑到问题里面可能会包含各种各样的这个情况,而答案是需要满足这些情况的。比如说有一个例子: What was the projection of sea level increases in the fourth assessment report?
这个问题里的限制或者说约束就是increase and forth并不是decrease and second.
所以针对这个问题模型提出了Neural question requirement inspection model。
2、NeurQuRI
2.1 overview

文章的ideas来源于《Globally coherent text generation with neural checklist models》,模型结构看上去也比较简单,左边就是传统的答案抽取片段模型。这个模型会抽取出候选答案,并且将其和问题作为我们提出的模型的输入,最后会计算出一个哨兵向量,它就代表着这个问题的可回答性。同时在右边它主要包括两个部分,分别是inspection encoder和Inspection comparator。
2.2 Inspection encoder
在第1个模块里面,输入就是候选答案和问题输出是一个哨兵。
在这里面我有几个疑点会用高亮标出来。

在这个模块中会得到一个隐状态inspection vector h \bf h h 和一个cumulative satisfaction score vector a t \bf a_t at
这个隐含向量它编码了,答案需要考虑问题当中的某些情况的信息。(我的理解它就是GRU当中的一个隐状态,只不过是把最后我得到的Inspection vector融入进去而已)
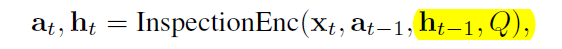
具体来说,先将候选答案中的tokens和问题中的tokens经过embedding层。并且对两者进行线性,使其保持一致的hidden size。接着会对问题中的每个词进行一个计算。对于t时刻,计算问题中第i个词的新表示,他表示的是不满足条件的情况。因为是1-
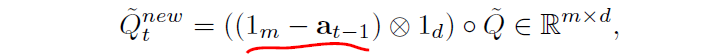
后面那一项符号表示repeat ( 1 m − a t − 1 1_m - \bf a_{t-1} 1m−at−1) d次,使其维度一致才能进行元素相乘。(有点迷惑,后面用到它再说)
接着,使用一个门机制,对候选答案中的词进行一个更新。目的是为了去过滤掉,部分包含在x当中的信息。
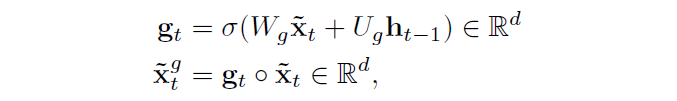
第3步就开始计算一个satisfaction score,使用上面更新的unmet问题q和答案x进行一个计算。(相当于做两个词之间的相关性)
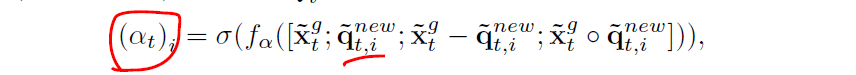
其实这个地方我就蛮奇怪的,他既然计算的是satisfaction score,即打分高表示可回答。那他为什么要用不满足条件的更新后的问题向量去和答案进行计算? 也就是上面疑惑为啥要 ( 1 m − a t − 1 ) (1_m - \bf a_{t-1}) (1m−at−1)
随后会计算inspection vector通过max polling。这个地方它又是将可满足的打分和不满足的问题×起来,再去进行max pooling。
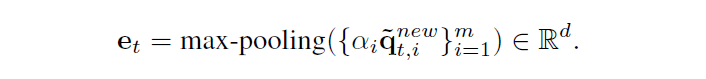
最后这个inspection vector就可以作为一个额外的特征参与循环神经网络(GRU)的计算并且去更新状态向量。

同时也会更新cumulative satisfaction score,可满足的得分最多不能超过1,所以在两者的得分加和,与1之间取了一个最小值:
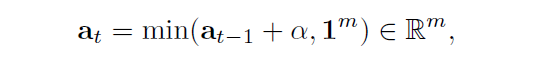
where 1 m 1^m 1m is an m dimensional ones vector so that each element.
2.3 Inspection comparator
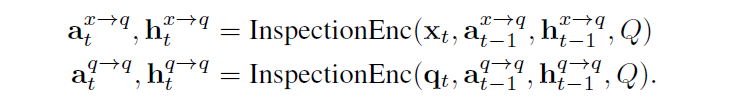
在对问题本身和问题和答案之间的关系,做完inspection encoder之后,通过输出的隐状态,我们就可以计算一个不可回答的打分:
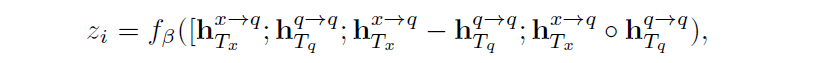
为什么要用问题本身做一个inspection,文章说原因是包含所有的问题词。那么直接用question embedding不可吗? 更直觉吗这不是。
2.4 Joint Training and Prediction
模型在预测可回答性的时候,是根据模型计算出的一个参考答案来计算的,所以对于可回答和不可回答的真实标签,我们需要放宽一下它的限制。

这里感觉有点问题,如果仅仅是因为它抽取出来的答案和标准答案之间的召回率很低,就认为它是不可回答的,即label=1,那有可能是你模型抽取答案本来就存在错误。
同样的,三个loss:
1.是否可回答分类loss:
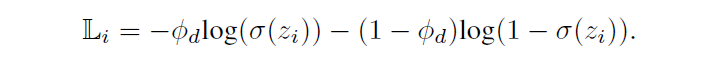
2.Satisfaction Score Loss.
这是作者提出的一种新的损失函数。在inspection encoder当中,会计算出两个得分,他们的得分越高,表示他们是越satisfied。对于问题本身来说,他跟自己的satisfaction肯定是满足的,所以希望他们的打分都很大。那对于问题和答案来说,如果问题是不可回答的,那么希望他们的satisfaction打分都很低。反之,越低越好。
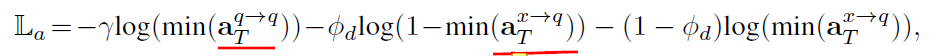
3.Inspector-Reader Joint Normalization
这个就是抽取答案的loss,为了惩罚有可能找错答案,文章考虑把计算出的哨兵也加进来:
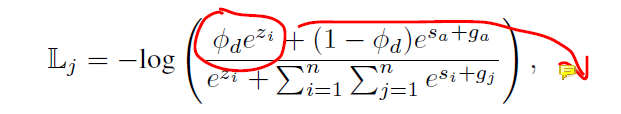
3、Experiment
1、主实验


对于生成的数据集MS MARCO,他也采用抽取式方法的指标来计算,文章说的是遵循SQUAD2.0 的方式。
从实验结果来说,这个方法在基本上所有的模型上都有效,而且对于越传统的方法效果提升的越明显。
2、对于loss的ablation分析,很神奇

文章里也说到了这么一句话:

尝试不一样loss组合方式,效果差异挺大;对于不同的数据集loss的选择也对实验效果造成比较大的差异。所以说损失函数之前的系数(文章选择的1:1:1),组合,选择,到底有一个什么样子的影响,确实很难去衡量。
我们在做实验的时候也会发现有的时候你这个损失加上可能还会让效果变差,但有的时候你去改变一下他们之间的系数关系,效果又会变好。不知道什么时候能够看到一篇就关于这个损失函数的一个大佬的文章,这里期待一下。
3、软标签

这个实验说明用软标签效果更好,可是就像我前面说的那样,标签有可能是错的,仅仅因为模型抽取的答案和真实答案的召回率低就认为答案不可回答,直观上存在问题。incredible!
但是如果你抽取模型足够的好,抽取的答案能够足够的准确,那么我觉得大部分的标签还是,和真实标签是一致的。感觉这里如果作者再做一个标签去软化的一个程度,有多少标签是被软化的,如果能够去做个这样的统计,感觉更有说服力吧。
最后给一个可视化的结果:

他会计算出问题当中所有词的一个打分。如果问题当中某一个词跟“参考答案”当中所有的词都没有关系,那么这个词的得分会特别的低,相比较其他词来说,其他词的得分会比较高,这样在问题的得分的一个分布上,就会出现有一个或者某几个的词特别低的情况。可以间接的反映这个问题在某种Condition下是跟“参考答案”没太大关系。从而判断出该问题不可回答。
不过个人感觉还是有问题,还是那句话,你的参考答案不一定是对的,拿一个不对的东西去做一个衡量是否带来新的问题。(感觉陷入死循环了,哈哈哈)
4、Discussion
优点:
- 通过Inspection encoder 考虑了问题为什么不可回答。
- 引入了一个新的loss,其实也是Inspection encoder 的产物。
值得探讨:
- 就我在文章高亮的部分,大家可以留言讨论一下,头脑风暴!
雏鹰AI