A Robust Adversarial Training Approach to Machine Reading Comprehension
2020 AAAI 百度,北大,厦大
动机:
同样是针对robustness,one of the most promising ways is to augment the training dataset
Since the types of adversarial examples are innumerable, it is not adequate to manually design
In this paper, we propose a novel robust adversarial training approach to improve the robustness of MRC models in a more generic way.
Specificly, dynamically generates adversarial examples based on the parameters of current model and further trains the model by using the generated examples in an iterative schedule.
it does not require any specification of adversarial attack types

AddSent:(Jia and Liang 2017) generates the misleading text by modifying the question according to
certain rules and proofreads manually
AddAnsCtx:we generate the misleading text by removing the answer words in answer sentences.
方法:
- Takes a well trained MRC model as the adversarial generator, and trains perturbation embedding sequences to minimize output probabilities of real answers
- Greedily samples word sequences from perturbation embeddings as misleading texts to create and enrich our adversarial example set.
- Trains the MRC model to maximize probabilities of real answers to defend against those adversarial examples.
具体而言:
During the training, we treat the model as a generator and all model parameters are fixed.
the training method only tries to perturb each passage input ep with an additional perturbation embedding sequence.

k is the insert position index, 随机加入
l is the length of the e’

对于每个位置i来说,对每个词的权重和为1

where αij is a trainable parameter for wi
Ques: W和alpha 对不同的样例都是一样的?

1、To generate misleading answer texts and distract the MRC model,design a cross entropy loss
aims to cheat the model and make the model believe the answer is locating in perturbation embedding sequence
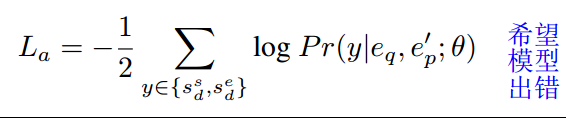
where sd is the distract answer span located in perturbation embedding sequence.
2、To generate misleading context texts, we design a loss function aims to minimize the model estimation on ground truth span sg

3、 define our training loss function as: loss越大越难骗过模型;loss越小,噪音越好
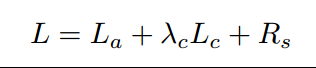
此外,Add a regularization term Rs ,
to control the similarity between perturbation embeddings and questions & answers
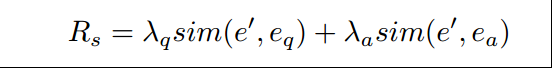
sim(·, ·) is defined as a bag-of-words cosine similarity function:
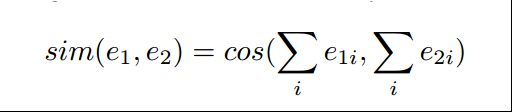
最后,
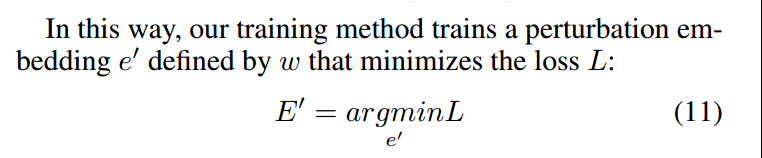
we repeat the training process for each instance until the loss L is converged or lower than a certain threshold, then return the weight matrix w for further sampling
贪心采样

We simply sample the maximum weighted

Therefore, for each instance, generating a misleading text is sampling a max weighted token sequence
Retraining with Adversarial Examples
we enrich training data with sampled adversarial examples and retrain our models on the enriched data
扩充数据
Given a misleading text and its corresponding triple data <q, p, s>, we insert the misleading text A back into its position k of the passage.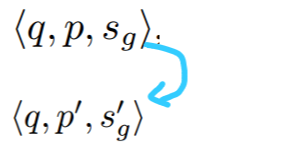
整个流程

实验
Standard SQuAD development set and five different types of adversarial test sets.

实验设置
• We randomly insert perturbation embedding between sentences, k 不确定的
• We limit the perturbation sequence length l to be 10
• we randomly set λq, λp to be -10 or 10, and set λc to be 0.5.
• And we set sd with random length in the middle of each perturbation embedding.
• we set the threshold as 1.5 and we set the maximum training step as 200 (most training losses tend to be stable (differences are lower than 1e-3) around 200 steps.)
• In training iteration, we set maximum training time T to be 5, trainloss’s stopping threshold yta to be 12.0.
• we randomly sample 5% training data for adversarial training and larger ratios will not provide satisfied performance within a single iteration according to our early experiments.
• After sampling, we retrain MRC models follow the early stopping strategy
• 对每个batch 都会收集local 词表。for each training instance, we utilize a local vocabulary V , in which tokens are mainly related to questions and passages.
• To make the model easier to converge, the vocabulary size is limited to 200.

结果


- ASD dataset has more overlaps with AS and AA.
- Our data has a more extensive distribution in the space. Its extensiveness enable itself to cover more types of adversarial examples
Ablation study

生成的一个结果:
