We simplify recently proposed contrastive self-supervised learning algorithms without requiring
specialized architectures or a memory bank.
- composition of data augmentations plays a critical role in defining effective predictive tasks,【数据增量的构成在定义有效的预测任务中起着关键作用】
- introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations【在表征和对比性损失之间引入可学习的非线性转换,极大地提高了学习表征的质量】
- contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning.
Most mainstream approaches fall into one of two classes: generative or discriminative.
大多数主流方法属于两类中的一类:生成型或判别型。
Generative approaches learn to generate or otherwise model pixels in the input space on representations learned with different self-supervised methods (pretrained on ImageNet).
生成式的方法学着去生成或者在(用不同的自监督方法学习到的表示)输入空间的像素上建模。【生成式方法学习生成或以其他方式模拟输入空间中的像素,这些像素是通过不同的自我监督方法(在ImageNet上预训练)学习的。】
Discriminative approaches learn representations using objective functions similar to those used for supervised learning, but train networks to perform pretext tasks where both the inputs and labels are derived from an unlabeled dataset.
【判别性方法使用类似于监督学习的目标函数来学习表征。
但要训练网络来执行输入和标签都来自于未标记的数据集的借口任务。】
Many such approaches have relied on heuristics to design pretext tasks , which could limit the generality of the learned representations.【许多这样的方法依靠启发式方法来设计借口任务,这可能会限制所学表征的通用性。】
Discriminative approaches based on contrastive learning in the latent space have recently shown great promise, achieving state-of-the-art results。
Composition of multiple data augmentation operations
is crucial in defining the contrastive prediction tasks that
yield effective representations. In addition, unsupervised
contrastive learning benefits from stronger data augmentation than supervised learning。【多种数据增强操作的组成对于定义产生有效表征的对比性预测任务至关重要。
此外,无监督的对比性学习比有监督的学习更受益于强大的数据增强。】
Introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations.
【在表征和对比损失之间引入一个可学习的非线性转换,大大改善了学习表征的质量。】
Representation learning with contrastive cross entropy loss benefits from normalized embeddings and an appropriately adjusted temperature parameter【对比性交叉熵损失的表征学习得益于规范化的嵌入和适当调整的温度参数】
Contrastive learning benefits from larger batch sizes and longer training compared to its supervised counterpart.Like supervised learning, contrastive learning benefits from deeper and wider networks.对比学习对比学习和监督学习相比,得益于更大的batch sizes和更长的训练。像监督学习一样,对比学习得益于更深和更广的网络。
Inspired by recent contrastive learning algorithms (see Sec-tion 7 for an overview), SimCLR learns representations by maximizing agreement between differently augmented views of the same data example via a contrastive loss in the latent space. 【SimCLR通过潜空间中的对比损失,使同一数据实例的不同增强视图之间的一致性最大化,从而学习表征。】
-
一个随机的数据增强模块可以转换任何给出的数据例子,导致相同例子的两个相关的视角
Xi,Xj,我们认为是一个positive对。我们按顺序应用三种简单的增强方法:random cropping followed by
resize back to the original size, random color distortions, and
random Gaussian
blur【随机裁剪,然后调整到原始尺寸,随机颜色扭曲,以及随机高斯模糊。】在第三章节中所示,随机裁剪和颜色扭曲对达到一个好的效果是至关重要的。 -
一个能够从增强的数据样例中获取表示向量的,基于编码器的神经网络。
我们的框架允许在没有任何限制的情况下对网络结构进行各种选择。我们选择简单的方法,采用常用的ResNet,得到hi = f( ~xi) =
ResNet( ~xi) 其中hi∈Rd是平均池化层后的输出。 -
一个小的神经网络投影头g(-),将表征映射到应用了对比性损失的空间中。
-

定义了 (在由minibatch派生的增强样例对 上的) 对比预测任务,从而得到2N个数据点。
我们没有明确地给出negative examples。相反我们给出了一对positive pair,把剩下的2N-1作为negative examples。样例(i,j)的positive pair损失函数定义如下:
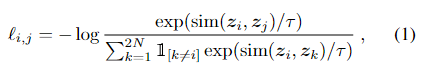
τ denotes a temperature parameter.
最后的损失是在所有positive pairs中计算出来的。(归一化的温度标度交叉熵损失)。

Training with large batch size may be unstable when using standard SGD/Momentum with linear learning rate scaling.【在使用线性学习率缩放的标准SGD/Momentum时,大批量的训练可能是不稳定的。】 To stabilize the training, we use the LARS optimizer (You et al.,2017) for all batch sizes.

在数据并行的分布式训练中,BN的平均值和方差通常在每个设备上进行本地汇总。在我们的对比学习中,由于正数对是在同一设备中计算的,该模型可以利用本地信息泄漏来提高预测的准确性,而不需要改进表征。我们通过在训练期间汇总BN平均数和方差整体设备来解决这个问题。
实验参数设定
We use ResNet-50 as the base encoder network, and a 2-layer MLP projection head to project the representation to a 128-dimensional latent space.【我们使用ResNet-50作为基础编码器网络,和一个2层的MLP投影头,将表征投射到128维的潜空间。】 As the loss, we use NT-Xent, optimized using LARS with learning
rate of 4.8 (= 0.3 × BatchSize/256) and weight decay of 10−6. We train at batch size 4096 for 100 epochs。we use linear warmup for the first 10 epochs,
and decay the learning rate with the cosine decay schedule without restarts。【我们在前10个历时中使用线性预热。
并使用余弦衰减时间表衰减学习率,不需要重新启动。】
三种数据增强方式
空间\几何转换方法
外表转换方法(颜色扭曲,亮度,对比度,饱和度)
高斯滤波,索贝尔滤波
我们的实验表明,无监督对比学习与监督学习相比,前者从更强的数据增强中获益。虽然之前的工作已经报道了数据增强对自监督学习是有用的。我们表明,在监督学习中没有产生准确性优势的数据扩充,仍然可以对对比学习有很大的帮助。
4.1无监督对比学习得益于更大的模型(深度和广度)
我们发现,随着模型规模的增加,监督模型和在无监督模型上训练的线性分类器之间的差距缩小了,这表明无监督学习比监督模型更能从更大的模型中获益。
5、可调节温度的归一化交叉熵损失比替代方案效果更好
5.2对比学习得益于更大的bitch_size和更长的训练过程
训练的epochs是小的值(100),那么更大的bitch_size有更明显的优势。当训练的epochs增多的时候,差距就会减小甚至消失。在对比学习中,更大的bitch_size提供了更多的negative样本,促进了收敛融合。(花费了更少的epochs就达到了给定的正确率)。同样的,训练过程增长也会提供更多的negative样本。
pretext tasks是个啥
pretext tasks 通常被翻译作“前置任务”或“代理任务”, 有时也用“surrogate task”代替。是为了学习一个好的任务表示。
- 这种训练不是我们本身的训练任务,并不是本身这次训练需要做的事情。
- 虽然不是这次训练需要做的事情,但是他可以促进我们的训练,达到更好的效 果。
The strength of this simple framework suggests that, despite a recent surge in interest, self-supervised learning remains undervalued.【这个简单框架的优势表明,尽管最近兴趣大增,但自我监督学习的价值仍然被低估了】