目录
机器学习分为有无监督学习,无监督学习和强化学习。而自监督学习(Self-Supervised Learning)是无监督学习的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。
自监督学习有一个非常强的动机:目前,大部分神经网络的训练仍然使用的是有监督范式,需要耗费大量的标注数据,标注这些数据是非常耗时费力的。而自监督的提出就是为了打破对人工标注的依赖,即使在没有标注数据的情况下,也可以高效地训练网络。众所周知,神经网络的训练需要任务来进行驱动,所以自监督学习的核心就是来合理构造有利于模型学习的任务。目前来说构造这些任务的方法大致可以划分为三个方面:
- 1) 基于 pretext task ( 代理任务 )
- 2) 基于 contrastive learning ( 对比学习 )
- 3) 基于 mask image modeling ( 掩码图像模型 )
本系列第一弹就来学习下对比学习,对比学习的经典网络就是MOCO系列了,在 MoCo 之前也有一些算法是基于某种形式的对比损失函数,例如 NPID、CPC、CMC 等,但是 MoCo 这篇论文则将之前的对比学习总结成字典查找的框架,再基于此提出 MoCo。本文就以小白视角进行MOCO网络思想学习。
论文下载地址:MoCo v1
代码下载地址:MoCo v1 Code
MoCo的核心思想有两点:第一是提出了Momentum Contrast(动量对比)的概念,第二是通过队列对数据结构进行维护(队列:先进先出)。下面来详细介绍这两点。
1.Momentum Contrast

对每个 batch 数据施加两组不同的数据增强,从而得到两组数据,作为模型的输入,其中一组为 x_query,通过 q_encoder 获得对应的特征向量 q;另一组为 x_key ,通过 k_encoder (即上图的 momentum encoder) 获得对应的特征向量 k。这两组 q,k 则作为正样本(来自于同一张原始影像,只是用来不同的数据增强方式)对进行损失函数的计算。而之前存在 queue 中的所有特征向量 k 和本次计算所得的 q 则作为负样本(来自于不同原始影像的所有元素都认为是负样本)对进行损失函数计算,两者结合便是 MoCo 算法训练所需要的损失函数。
这里的正负样本比较难理解,图像举例说明, 假设有两个图片,图片1和图片2。先在图片1中通过数据增强产生两张图片,记作A,B,在图片2中截出一个patch记作C,现在把B和C放到样本库里面,样本库图片的位置随机打乱,然后以A作为查找的对象,让你从样本库中找到与A对应的图片。


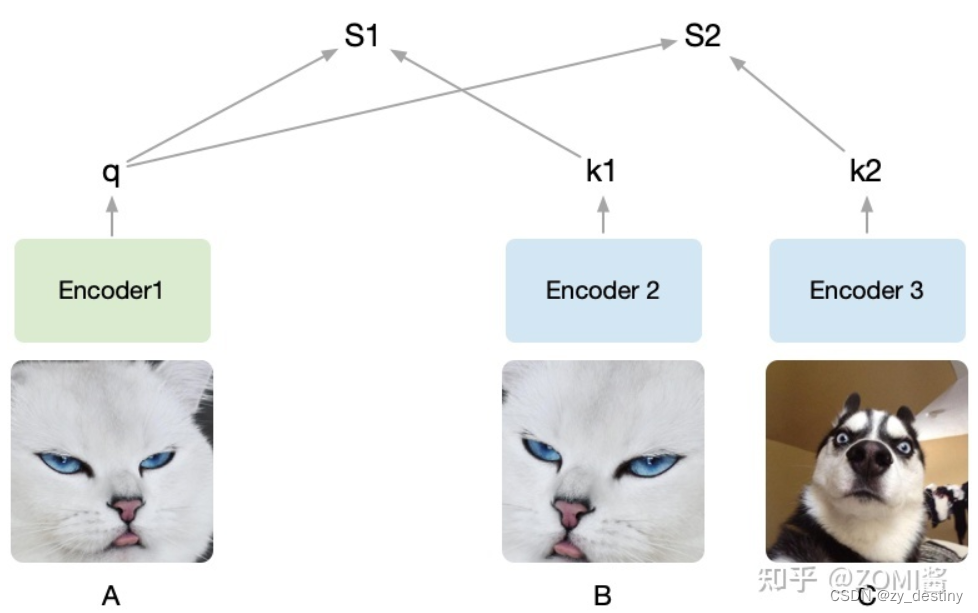
随机裁剪了A,B, C三个图,将A设为被预测的对象,然后A通过encoder1编码为向量q,接着B、C经过encoder2编码为k1和k2。q和k1算相似度得到S1,q和k2算相似度得到S2。我们的目的是想要让机器学出来A和B是一类(关联性强),而A和C其它不是(关联性弱)。
由于提前知道A和B是同一张图截出来的,而C不是,因此希望S1(A和B的相似度)尽可能高而S2(A和C的相似度)尽可能低。把B打上是正类的标签,把C打上是负类的标签,即同一张图片截出来的patch彼此为正类,不同的图片截出来的记为负类,由于这种方式只需要设定一个规则,然后让机器自动去打上标签,基于这些自动打上的标签去学习,所以也叫做自监督学习,MoCo就是通过不需要借助手工标注去学习视觉表征。
2.contrastive loss
2.1三种对比损失机制
原始的自监督学习方法里面的这一批负样本就相当于是有个字典 (Dictionary),字典的key就是负样本,字典的value就是负样本通过 Encoder 之后得到的特征向量。这一批负样本的大小就是 batch size。

以上是三种不同的对比损失机制:
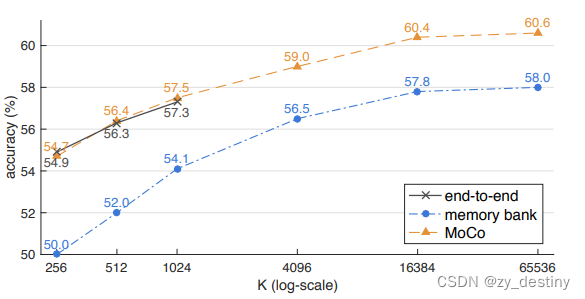
- end-to-end:该网络利用当前的mini-batch data去更新参数,由于当前batch data输入encoder之后得到的encoded keys 字典都是由一套参数的encoder得到的,所以能够很好地保持一致性,但是也正因为如此,导致负样本数量,也就是batch size不能给的太大,在SimCLR中被证明过自学习的负样本数量越大越好的。因此端到端网络能获取一致性较好的特征,却不能给到较大的batch size。
- memory bank:采用一个较大的memory bank存储字典:对于给定的一个样本 ,选择一个正样本 (经过data augmentation的图像)。采用一个较大的 memory bank 存储字典,这个 memory bank 具体存储的是所有样本的表征 representation(涵盖所有的样本,比如样本一共有60000个,那么memory bank大小就是60000,字典大小也是60000)。采样其中的一部分负样本 ,然后使用Contrastive loss将 q 与正样本之间的距离拉近,负样本之间的距离推开。这次只更新 Encoder 的参数,和采样的key值 。因为这时候没有了 Encoder 的反向传播,所以支持memory bank容量很大。但是,这一个step更新的是 Encoder 的参数,和几个采样的key值 ,下个step更新时会有部分encoder参数和key值未更新,也就是某一个 key 可能很多个step才被采样到更新一次,而且一个epoch只会更新一次。这就出现了一个问题:每个step编码器都会进行更新,这样最新的 query 采样得到的 key 可能是好多个step之前的编码器编码得到的 key,因此丧失了一致性。
端到端自监督学习方法的一致性最好,但是受限于batchsize的影响。而memory bank方法采用一个memory bank存储较大的字典,一致性却较差。基于以上两种限制,就有了MoCo方法。
- MoCo:右边的 Encoder 是不直接通过反向传播来训练的,而是优化器产生的动量更新,更新的表达式如下:

θ_k 是右边 Encoder 的参数,m默认设为0.999,θ_q 是左边编码 query 的 Encoder,θ_q 通过反向传播来更新,θ_k 则是通过 θ_q 动量更新。MoCo以动量的方法更新的,不涉及反向传播,所以输入的负样本的数量可以很多,具体就是队列的大小可以比较大(原文取队列长度为65536),也就是负样本的数量越多越好。而且 Momentum Encoder 的更新极其缓慢,但是每个step都会更新 Momentum Encoder,这样 Encoder 和 Momentum Encoder 每个step 都有更新,也就解决了一致性的问题。同时解决负样本尽可能多和一致性的问题。
2.2MoCo伪代码:

2.3损失函数
对比学习关注的是能不能区别出同类和非同类的样本,Contrastive loss有很多不同的形式,MoCo使用的是InfoNCE:

本文通过点积来计算 q 和 k 的相似度,k+ 是指正样本经过momentum encoder编码成的向量,注意的是里面对照样本里面只有一个正样本,其余K个都是负样本,至于分母 τ 就是softmax的温控参数,用来控制概率分布的尖锐和平滑。
3.队列思想
其实之前有提及到,MoCo 是通过队列方式储存特征向量的,避免在训练过程中输入大 batch size,减少了硬件资源的需求和训练时间。而且由于队列的长度较大(本文为 65536),可以提供大量的负样本进行对比学习;且队列先进先出的原则,可以及时更新特征向量,删除过于老旧的特征向量,一定程度上保证队列的一致性和训练的稳定性。
MoCo v1在前向计算最后,需要将本次计算的 k 送入队列,若队列已满,则最旧的特征向量出列。在反向计算时,q_encoder 通过梯度反向传播进行更新,但 k_encoder 则是根据 q_encoder 采用动量更新参数的模式进行更新,以此来保证模型一致性。
4.效果对比
4.1三种对比损失机制精度对比
4.2在ImageNet分类任务精度对比

4.3在PASCAL VOC目标检测任务中精度对比
