TrustFed: A Framework for Fair and Trustworthy Cross-Device Federated Learning in IIoT
IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS,2021
文章目录
Summary
本文:
- 提出了一个区块链支持的框架——TrustFed,用于一个完全去中心化的CDFL系统,提议框架使用以太坊区块链和智能合约技术来实现去中心化,并在CDFL系统中维护参与者的声誉。
- 提出了一个新的CDFL公平协议,该协议检测出训练分布中的异常值,并在聚合模型更新之前去除它们。
- 使用了一个真实的 IIoT数据集来实现和测试TrustFed提议的协议。
Research Objective(s)
实现一个完全去中心化的CDFL系统,该系统使用IIOT设备作为FL参与者,考虑CDFL训练模型中参与者的分散化、训练配置 以及公平性和信任度的要求,将区块链作为CDFL训练网络中分散的信任实体。
Background / Problem Statement
随着国家数据安全法规的日益完善、各方组织之间的数据孤岛问题愈发严重,以及数据泄露风险的不断增加,人们对数据隐私保护的需求也越来越强。为了做到不泄露数据的情况下,达到完成机器学习的目的:联邦学习技术孕育而生,它使数据不出本地的情况下,有效地利用交互模型中间参数进行模型训练,从而得到较好的模型,主要是解决了不同参与方之间的数据孤岛问题,和数据安全与隐私保护问题。联邦学习也是一种隐私保护的分布式机器学习协议。|
联邦学习训练主要采用两种配置方法:
- 跨数据集(Cross-dataset)联邦学习系统CDSFL(其他文章也叫跨孤岛),该系统将数据集垂直划分到训练网络中的多个参与者;
- 跨设备(Cross-device)系统CDFL,通过该系统数据集被水平划分到训练网络中的所有设备上。
下面是这两种类型的对比:
| 跨孤岛FL | 跨设备FL | |
|---|---|---|
| 数据类型 | 横向/纵向 | 横向 |
| 分布规模 | 2~100个 | 最多1010个 |
| 例子 | 不同机构 | 物联网设备 |
| 节点状态 | 节点几乎稳定运行 | 大部分节点不在线 |
| 主要瓶颈 | 计算瓶颈和通信瓶颈 | 通信成本和被恶意攻击 |
但是CDSFL系统总是依赖集中式服务器来协调参与者之间的训练服务,聚合模型更新,并维护集中式模型的不同版本。这种类型的FL设置总需要一个稳定的通信网络,以确保FL参与者的高可用性。
而在CDFL系统中,设备可以加入或离开训练网络,CDFL去中心化特性也增加了潜在的网络通信成本,进而增加了模型中毒和对抗性攻击的概率。训练网络的解耦增加了底层点对点网络的通信成本,同样这些设备可以通过发起对抗性攻击来串通和污染某些设备上的训练模型,导致不公平地训练出低质量的FL模型。另一方面,跨设备(Cross-device)联邦学习系统CDFL实现了完全去中心化的训练网络,每个参与者可以作为模型所有者和生产者。CDFL系统需要确保网络中所有参与者的公平性、可信度和高质量的模型可用性。
综上,考虑到数据集的去中心化性质,设备的FL系统中的分布,以及训练高质量和人群代表性模型的要求,公平和可信赖性的问题需要特别的关注。
Method(s)
Framework for trustworthy FL
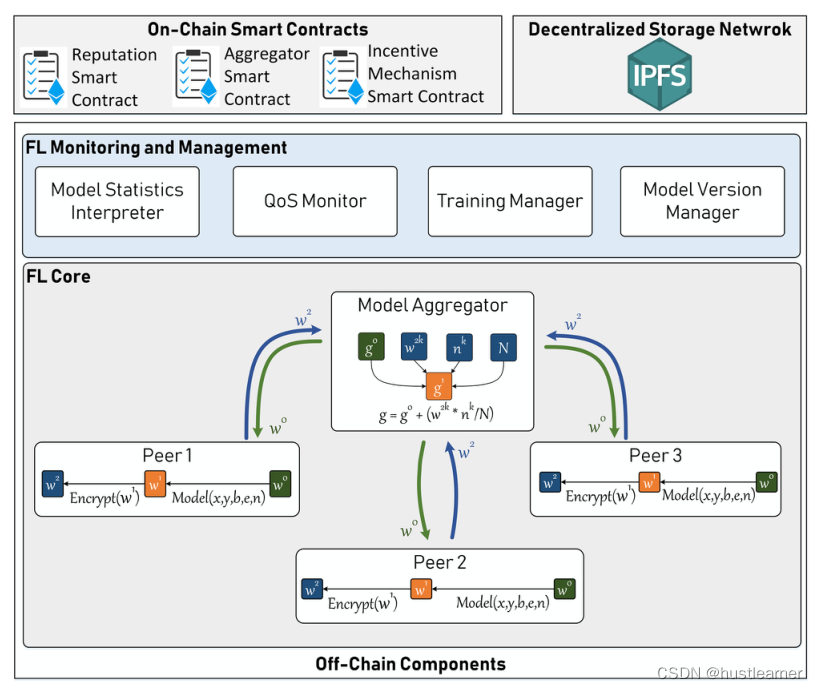
该框架支持链上和链下FL应用组件之间的交互,以实现FL环境;监控FL进程,收集相关统计数据,并达到承诺的QoS要求;部署公共区块链技术,利用信誉和激励机制智能合约进行链上FL模型聚合,确保公平和可信。
Off-Chain FL Components
QoS(Quality of Service)管理者:去中心化系统中过多的异构设备和系统引起了质量问题,如一些设备的延迟报告可能导致一些重要的模型更新或某些设备上NON-IID数据集的丢失,从而导致模型过度拟合。同样,异步设置也会导致梯度优化延迟,导致模型收敛性差。QoS管理器发布每个参与者的质量需求和激励承诺,并根据它们在区块链网络上的声誉选择最有前途的设备。
训练管理者:随机选取一些信誉好的设备(通过λ平均信誉分判断,在每轮训练结束时生成模型性能统计数据),并分为两个子轮训练。
总结为如下流程图:
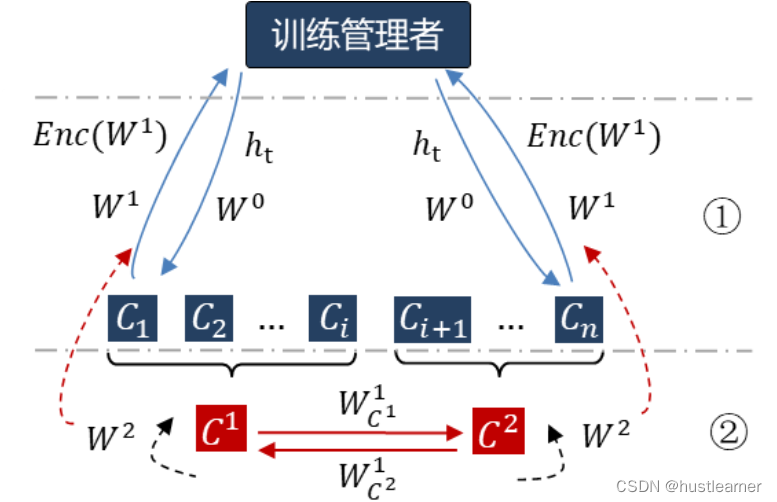
S i : 服 务 器 W i : 设 备 工 作 者 P i : 参 与 者 W i : 权 重 C : 信 誉 好 的 设 备 h t : 全 局 模 型 超 参 数 S_{i}:服务器~~~~~W_{i}:设备工作者~~~~~P_{i}:参与者~~~~~W^{i}:权重~~~~~C:信誉好的设备~~~~~h_{t}:全局模型超参数 Si:服务器 Wi:设备工作者 Pi:参与者 Wi:权重 C:信誉好的设备 ht:全局模型超参数
- 首轮:发送 h t h_{t} ht和权值 W 0 W^{0} W0给每个 C C C, C C C对模型进行训练后生成新的 W 1 W^{1} W1和 E n c ( W 1 ) Enc(W^{1}) Enc(W1)并发回给训练管理者。
- 次轮:将 C C C分为两组,收敛贡献度小于等于平均值的被归类为 C 1 C^{1} C1,其余为 C 2 C^{2} C2.对模型更新进行交叉验证,即 W C 2 1 → C 1 , W C 1 1 → C 2 W^{1}_{C^{2}} \rightarrow C^{1},W^{1}_{C^{1}} \rightarrow C^{2} WC21→C1,WC11→C2再次训练生成新的 W 2 W^{2} W2。
模型统计解释器:维护模型统计数据分布,以检测 C i C_{i} Ci模型的性能,并根据每次训练子轮的变化,将新的声誉分数分配给每个 C i C_{i} Ci。
模型版本管理者:交叉检测模型性能,并与初始模型性能相比较。将模型存储在去中心化的IPFS系统中,并将模型更新给所有FL参与者。
FL核心组件:主要包括模型聚合器和Peers。
- 模型聚合器:聚合收到的 W 2 W^{2} W2,将更新后的模型权值存储在IPFS上。通过智能合约发起新的区块链交易,以更新网络上所有的FL参与者。
- Peers:进行本地训练,与P2P网络上的参与者P_{i} 通信,并为模型聚合器收集权重 W i W^{i} Wi。
On-Chain FL Components
主要包括三个智能合约,分别为信誉智能合约、聚合器智能合约和激励机制智能合约。
**信誉智能合约:**设备需要信誉分数来找更信任的服务器,而服务器也需要根据信誉分找潜在的模型贡献者。
- 委托人 T u T_{u} Tu:为可信用户和可信来源,受托人的信誉分公开给所有者。
- 受托人 T p T_{p} Tp:为可信提供者或可信destination与系统交互,只有参与设备才能更新 T p T_{p} Tp的destination信任值。
- 链下操作:由多个 T u T_{u} Tu执行计算复杂的迭代函数的信任值积累,链下计算包括统计方法、AI模型、预测方案、处理信任值等。
- 链上声誉聚合:每个 T p T_{p} Tp基于共识的信任值聚合,并执行算法1(主要分三步,计算信誉设备数量、找出信誉分高的设备和输出相应的信誉分)。合约归 T p T_{p} Tp所有,执行算法2中的公平FL协议后,再计算设备的信誉。
聚合器智能合约:
- 对模型权重进行链上聚合,并更新模型的新版本
- 生成更新后的权重矩阵和相应模型的统一哈希值,并在链上聚合,以及更新权重链。
激励机制智能合约:
- 所有设备被认为自愿参与训练过程。
- 使得所有参与设备公布其QoS参数(如最低可接受精度、训练预算、训练时间和其他参数等)。
- 并使用加密货币进行支付奖励。(如以太坊的ERC-20)
公平FL协议算法:
- 每个 S I S_{I} SI 输入QoS参数,将设备划分为两类,trainers( C 1 C^{1} C1)和validators( C 2 C^{2} C2)。
- trainers逐个训练模型。
- trainers发送模型给validators验证。
- 互换角色,重复前面的训练和验证过程。
- 计算异常值和平均精度。
- 判断平均精度是否满足QoS参数中的精度要求。
Evaluation
实验环境:Python语言、PyTorch框架、涡扇发动机退化仿真数据集NASA。
在FL训练网络中,有和没有异常值的数据在设备间公平分布/随机分布的聚合模型损失:

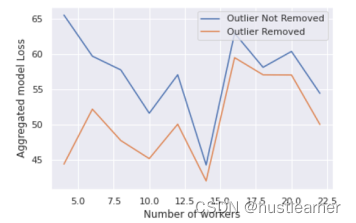
无论设备数量如何,本方案在损失较低方面表现出更好的结果。
在数据公平分布/随机分布的跨设备设置中测试每个工作模型时的模型丢失:
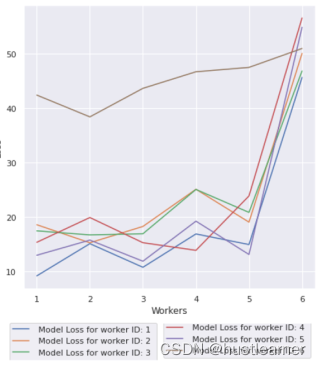
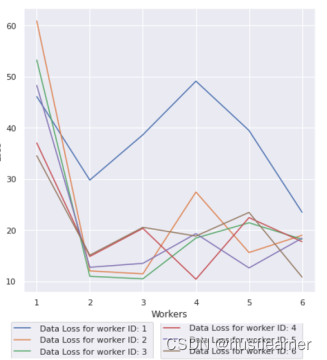
根据损失值的异常,可以检测出恶意设备。
在FL训练网络(100名工人)的设备间随机数据分布中,有和没有异常值的聚合模型损失:
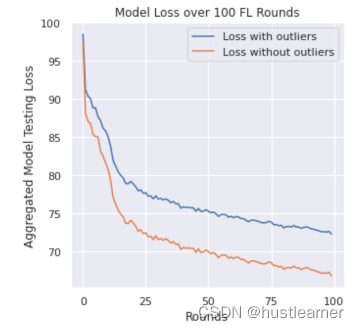
无异常值比有异常值模型聚合时的损失更小。
验证其他不同组别工人的总时间:
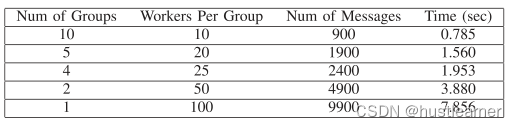
与异常值的预期数量相比,分组数量不应太小。
Conclusion
本文主要有以下四个贡献:
- 使用勒以太坊区块链和智能合约实现去中心化的CDFL系统——TrustFed。
- 提出了一个新的CDFL协议,该协议检测出训练分布中的异常值。(一次异常就剔除,略牵强)
- 使用了一个真实的IIoT数据集实现和测试TrustFed(感觉训练的设备数量为100个,可能不够?)
- 将结果与最新的标准方法进行了比较与评估。(好像并没有比较)
Notes
开源。项目地址:
| 原项目 | 补充 |
References
参考:论文笔记