时间序列分类 自监督对比学习
motivation:cv能取得这么好的效果是因为有数据增强, 而时间序列的表现差的原因是因为数据增强和特征提取器(backbone)不适用于提取时序依赖关系。
innovation:
- 我们提出了一种新的单变量时间序列数据增强方法,称为DTW数据增强,该方法不仅产生相移和幅度变化,而且保留了时间序列的结构和特征信息
- 我们设计了一个特征提取器,它可以以端到端的方式生成单变量时间序列表示,利用当前最先进的基于深度学习的时间序列分类方法InceptionTime的优势
- 结合DTW数据增强和接收时间模型的优点,我们成功地将扩展SimCLR应用于时间序列领域
- 我们进行了多种类型的实验,结果表明了我们方法的有效性和通用性。
总结:
在TimeCLR的基础上,加入DTW数据增强策略,网络用inceptionTime替换。
DTW数据增强:用一个autoencoder来训练增强数据。如图1,训练方式为随机抽取2个时间序列,生成伪标签,伪标签是这2个时间序列的DTW距离。X1和X2输入到encoder得到特征,计算X1_feature和x_2feature的欧式距离与伪标签y的差值(因为我们希望生成的特征能够与dtw的距离越相近),这是L1。L2为时间序列的重构损失之和。
得到的AE然后重新对输入数据进行数据增强,在特征中加入幅度噪声和移动噪声,经过decoder得到数据增强后的数据。
最后,和SimCLR一样,只不过把backbone替换为InceptionTime.
Abstract
Time series are usually rarely or sparsely labeled, which limits the performance of deep learning models. Self-supervised representation learning can reduce the reliance of deep learning models on labeled data by extracting structure and feature information from unlabeled data and improve model performance when labeled data is insufficient. Although SimCLR has achieved impressive success in the computer vision field, direct applying SimCLR to time series field usually performs poorly due to the part of data augmentation and the part of feature extractor not being adapted to the temporal dependencies within the time series data. In order to obtain high-quality time series representations, we propose TimeCLR, a framework which is suitable for univariate time series representation, by combining the advantages of DTW and InceptionTime. Inspired by the DTW-based k-nearest neighbor classifier, we first propose the DTW data augmentation that can generate DTW- targeted phase shift and amplitude change phenomena and retain time series structure and feature information. Inspired by the current state-of-the-art deep learning-based time series classification method, InceptionTime, which has good feature extraction capabilities, we designed a feature extractor capable of generating representations in an end-to-end manner. Finally, combining the advantages of DTW data augmentation and InceptionTime, our proposed TimeCLR method successfully extends SimCLR and applies it to the time series field. We designed a variety of experiments and performed careful ablation studies. Experimental results show that our proposed TimeCLR method can not only achieve comparable performance to supervised InceptionTime on multiple tasks, but also produce better performance than supervised learning models in the case of insufficient labeled data, and can be flexibly applied to univariate time series data from different domains.
时间序列通常很少或很少标记,这限制了深度学习模型的性能。自监督表示学习通过从未标记数据中提取结构和特征信息,减少深度学习模型对标记数据的依赖,并在标记数据不足时提高模型性能。尽管SimCLR在计算机视觉领域取得了令人瞩目的成功,但直接将SimCLR应用于时间序列领域通常表现不佳,这是因为数据扩充部分和特征提取部分不能适应时间序列数据中的时间依赖性。为了获得高质量的时间序列表示,我们结合DTW和InceptionTime的优点,提出了一种适用于单变量时间序列表示的框架TimeCLR。受基于DTW的k-最近邻分类器的启发,我们首先提出了DTW数据增强,它可以生成DTW目标相移和幅度变化现象,并保留时间序列结构和特征信息。受当前最先进的基于深度学习的时间序列分类方法InceptionTime具有良好的特征提取能力的启发,我们设计了一个能够以端到端的方式生成表示的特征提取器。最后,结合DTW数据增强和接收时间的优点,我们提出的TimeCLR方法成功地扩展了SimCLR并将其应用于时间序列领域。我们设计了多种实验并进行了仔细的消融研究。实验结果表明,我们提出的TimeCLR方法不仅可以在多个任务上获得与监督接收时间相当的性能,而且在标记数据不足的情况下,其性能优于监督学习模型,并且可以灵活地应用于不同领域的单变量时间序列数据。
Introduction
时间序列数据每天从医疗、金融、工业和其他领域的传感器中逐步收集,其主要特点是数据中具有很强的时间依赖性。深度学习已成为时间序列分析领域中广泛使用的方法,并已成功应用于不同领域的时间序列[1,2](介绍背景)。然而,时间序列数据很少或很少标记。与图像和文本数据不同,真实世界的时间序列是高维和复杂的,通常没有人类可以直接识别的特征,或者只有特定领域的专家可以识别的特征,这使得无法直接标记时间序列,或者标记时间序列数据的成本非常高。虽然深度学习是一种数据驱动的方法,但缺少标记数据限制了深度学习模型的性能(引出当前背景下还有什么问题)。一种解决这个问题的方法是从未标记的时间序列中学习结构和特征信息以组成表示,从而减少对昂贵的手动标记的依赖(当前这种问题的解决方案,为后面铺垫衔接)。
自监督表示学习通过自生成信号从未标记数据中提取下游任务的有效表示。在计算机视觉领域,自监督表征学习近年来受到了广泛的关注。在这一领域,自我监督表示学习可以产生与监督训练模型相当的性能[4,5]。自我生成的信号来自图像上的不同借口任务[6,7]。成功的借口任务之一是使用对比学习从不同的增强图像视图中学习不变表示[8,9,4],其中使用最广泛的方法是SimCLR(这段引出SimCLR,因为此篇论文是将SimCLR引入到时间序列之中的,为了和后面的衔接,必须先介绍一下SimCLR)。
时间序列自监督表示学习的一种启发式方法是将SimCLR直接应用于时间序列领域。不幸的是,这种方法在时间序列数据上不能很好地工作。首先,时间序列数据具有很强的时间依赖性,传统的时间序列数据增强可能会破坏数据中的时间依赖性,从而损害结构和时间序列特征信息。其次,一些能够在图像上产生良好结果的数据增强操作并不能很好地拟合时间序列(个人觉得这里需要在对这句话继续解释)。第三,对图像性能优异的特征抽取器不能很好地提取时间序列的结构和特征信息。Mohsenvand等人[10]将扩展SimCLR应用于EEG时间序列,但该方法是针对特定应用场景设计的,不能推广到其他时间序列领域。(这段说明SimCLR的一些不足)
为了解决上述问题并将SimCLR应用于时间序列领域,我们提出了一种单变量时间序列自监督对比学习表示框架(TimeCLR)。首先,作为比较单变量时间序列之间相似性的一种经验证的方法,动态时间扭曲(DTW)以时间序列的相移(phase shifts)和振幅(amplitude changes)变化为目标,使时间序列以非线性方式扭曲以相互匹配[11,12]。基于DTWB的k-最近邻算法在时间序列分类问题上产生的更好性能[13–15]表明,对于同一类别的时间序列,可能存在相移和振幅移。受此启发,我们提出了一种新的单变量时间序列数据增强方法DTW数据增强方法,该方法具有一个特殊的自监督训练自动编码器。其中,编码器可以将一元时间序列映射到欧氏特征空间中的嵌入向量,嵌入向量的移动可以引起时间序列的相移和幅度变化,解码器可以将嵌入向量重构回时间序列。DTW数据增强不仅可以产生相移和幅度变化,而且可以保留时间序列的结构和特征信息(个人觉得这里应该分段,整段太长了,前面对应了SimCLR应用在时间序列的第一个drawback)。其次,我们提出的自监督对比学习框架使特征提取器能够在两次单独的数据扩充操作后,通过最小化同一样本中两个视图的相似度,学习两个视图中的不变结构和特征信息,从而生成高质量的表示。InceptionTime作为时间序列分类问题的最新监督深度学习方法[16],表明它对时间序列数据具有良好的结构和特征信息提取能力,受此启发,我们结合InceptionTime的优点,在TimeCLR中设计了特征提取器。第三,我们在监督学习、半监督学习、迁移学习和聚类任务上的多次实验表明,TimeCLR可以达到与监督接收时间相当的性能,并且可以在不同的时间序列域上推广。我们还设计了各种烧蚀实验,以验证TimeCLR各个组件的重要作用。(个人认为这段写的不是很好)
- 我们提出了一种新的单变量时间序列数据增强方法,称为DTW数据增强,该方法不仅产生相移和幅度变化,而且保留了时间序列的结构和特征信息
- 我们设计了一个特征提取器,它可以以端到端的方式生成单变量时间序列表示,利用当前最先进的基于深度学习的时间序列分类方法InceptionTime的优势
- 结合DTW数据增强和接收时间模型的优点,我们成功地将扩展SimCLR应用于时间序列领域
- 我们进行了多种类型的实验,结果表明了我们方法的有效性和通用性。
related work(分别从3个角度说明相关工作,时间序列建模,数据增强,自监督方法)
time series modeling
基于Shapelets的方法是时间序列分类方法的一个重要类别。这些方法从训练集中提取有区别的子序列,并将其输入现成的分类器中[17–19]。虽然提取形状元素的训练复杂度太大,无法应用于更大的数据集,但这类方法的成功表明,时间序列建模的关键是从时间序列中提取结构和特征信息。基于距离的方法依赖于基于欧氏距离或DTW的k-最近邻分类器进行分类[11,20]。基于DTW的k-最近邻算法的成功表明,在同一类时间序列数据中存在相移和振幅变化。Cai等人[21]利用DTW设计了一种新的神经网络组件,以获得更好的特征提取,表明DTW有利于改进神经网络的特征提取。最近,基于深度学习的方法受到了广泛关注,这些方法使用深度神经网络以端到端的方式对时间序列建模[22,14,1]。常用的时间序列建模神经网络结构可分为基于多层感知器的神经网络、基于CNN的神经网络和基于RNN的神经网络。总的来说,CNN比RNN和MLP产生更好的结果,InceptionTime是当前最先进的模型,ResNet是次优模型。 (这段写的不好,在introduction中介绍的都是DL的方法,这里又写到了shapelet-based和Distance-based方法,和主题其实不相干。不如多介绍一些DL的方法)
data augmentation for time series
数据扩充的目的是提供新的时间序列样本。传统的时间序列数据增强方法包括抖动、缩放、磁扭曲、时间扭曲、排列、反转和旋转[23]。其中,旋转只能应用于特定领域传感器生成的时间序列数据。在文献中,许多数据扩充方法都集中于一个域的时间序列。为了扩充ECG和EEG数据集,Haradal等人【24】使用生成对抗网络来生成和识别合成生物信号。Ramponi等人【25】使用具有不规则采样的条件生成对抗性网络对噪声时间序列进行数据增强。Cao等人[26]使用不同类别的样本对电信号记录进行了数据扩充。此外,一些研究通过两个数据的插值生成新的时间序列样本。由于时间尺度上频繁的非线性变换,插值非常困难【27】。DeVries等人[28]表明,深层特征空间中的插值优于时间序列的直接插值。这种方法不适合我们的对比学习框架,因为生成一个数据需要两个样本。我们的方法需要时间序列数据扩充,这些扩充能够保留关于时间序列结构和特征的信息,并且可以推广到不同的领域。
self-supervised representation learning for time series
自监督表征学习因其在计算机视觉领域的巨大成功而受到越来越多的关注[6,29,30]。最受关注的是Chen等人提出的SimCLR。近年来,时间序列的自监督表示学习越来越流行。Hyvarinen等人提出的方法通过使用对比损失来预测时间序列的段ID来提取表示[31]。Franceschi等人提出的方法使用基于时间关系和三重态丢失的负采样来提取时间序列的可伸缩表示[32]。Jawed等人提出的方法利用预测任务作为借口任务来生成表征【33】。Tonekaboni等人[34]利用时间邻域关系学习非平稳时间序列的广义表示。Fan等人【35】通过探索时间序列样本间关系和时间内关系来学习表征。Eldele等人【36】通过时间和上下文对比学习时间序列表示。这些时间序列自监督表示学习方法取得的最佳结果与相应的监督模型相当。此外,Anand等人[37]使用视觉感知和无监督三损失训练生成时间序列的表示,这种表示主要用于聚类。Autowarp[38]还可以在时间序列度量的无监督学习过程中生成潜在表示,但此类表示主要用于获得高质量度量。对于特定领域的时间序列表示也有一些研究。SSL-ECG通过对数据集应用六种转换来学习ECG时间序列表示[39]。SEQCLR设计了与EEG相关的数据增强,并将SimCLR扩展到EEG时间序列[10],但其数据增强操作可能会破坏时间序列内的时间相关性,并且仅限于应用于EEG数据。我们提出的TimeCLR不仅具有与最先进的有监督深度学习模型InceptionTime相当的性能,而且还可以应用于不同领域的时间序列数据。
preliminaries and notations
time series
介绍时间序列的定义
Dynamic time warping
介绍DTW。
methodlogy
在本节中,我们将介绍我们提出的TimeCLR框架。我们首先介绍了DTW数据增强,它利用一种特殊的自监督训练自动编码器,可以生成时间序列数据的相移和振幅变化。然后,我们提出了时间序列数据自监督对比表征学习的训练框架。DTW数据扩充和框架使特征提取器能够生成高质量的表示。
DTW data augmentation
基于DTW的k-最近邻分类器在时间序列分类问题上取得了较好的结果,这启发我们,DTW所针对的相移和幅度变化现象可能存在于同一类时间序列中,产生这种现象的数据扩充可以保留时间序列的结构和特征信息。
很难直接对时间序列的观测值进行操作,以反映相移和振幅变化。为了解决这个问题,我们提出了DTW数据增强,它使用一个特殊的自监督训练编码器将时间序列映射到欧几里德特征空间。嵌入向量在欧氏特征空间中的移动会产生相移和振幅变化。

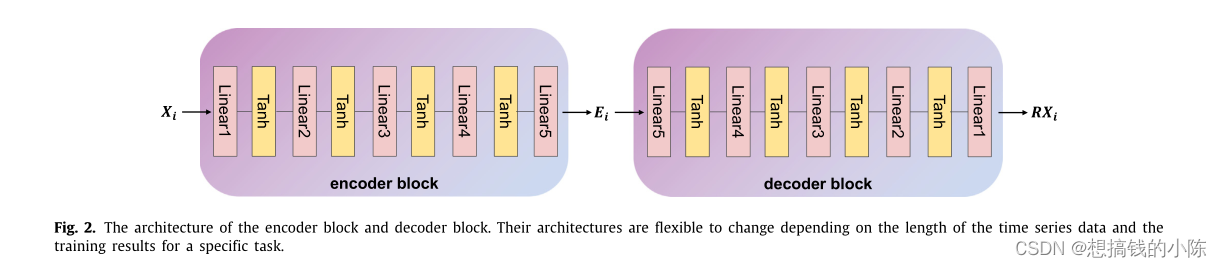
如图1所示,自动编码器的编码器是具有两个编码器块的暹罗神经网络,两个编码器块具有相同的结构并共享权重。编码器块将时间序列投影到高维欧几里德特征空间,形成保留所有信息的嵌入向量。自动编码器的解码器也是一个带有两个解码器块的暹罗神经网络,两个解码器块具有相同的结构和共享权重。解码块用于将欧氏特征空间的嵌入向量重构为时间序列,其结构与编码器块对称。图2示出了我们使用的编码器块和解码器块的体系结构。请注意,它们的体系结构可以根据时间序列数据的长度和特定任务的培训结果灵活更改。下面,我们将详细描述我们的特殊自我监督训练方法。
我们为autoencoder的自监督训练构建了一个特殊的数据集![]() 。总共有N(N-1)/2个样本,就是从样本集里面抽出2个随机组合。yi是这两个时间序列的DTW(?)。如果时间序列的长度是L,那么构建这个数据集的时间复杂度达到O(N2L2),但Mueen et.al 提出的方法可以达到O(N2L)。值得注意的是,由于D中的时间序列不需要人工标记,因此在现有样本不足的情况下,我们可以很容易地向D中添加更多样本。由于自动编码器的自监督训练是为了学习不同距离之间的映射关系,因此可以添加属于其他域但长度相同的时间序列。当可用样本足够时,我们还可以考虑去除D的一些元素,以加快自动编码器的自监督训练。
。总共有N(N-1)/2个样本,就是从样本集里面抽出2个随机组合。yi是这两个时间序列的DTW(?)。如果时间序列的长度是L,那么构建这个数据集的时间复杂度达到O(N2L2),但Mueen et.al 提出的方法可以达到O(N2L)。值得注意的是,由于D中的时间序列不需要人工标记,因此在现有样本不足的情况下,我们可以很容易地向D中添加更多样本。由于自动编码器的自监督训练是为了学习不同距离之间的映射关系,因此可以添加属于其他域但长度相同的时间序列。当可用样本足够时,我们还可以考虑去除D的一些元素,以加快自动编码器的自监督训练。
暂时写到这儿。