书接上回,何老师的MoCo被SimCLR偷袭了,上来就是7个点的提升
SimCLR整的什么活儿?
SimCLR
基本流程如下,不赘述了

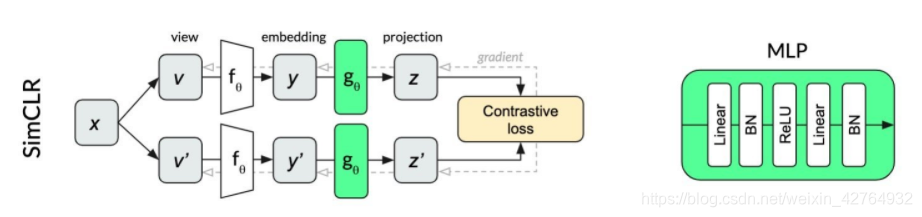
不同于MOCO的两个编码器,SimCLR还是沿用了一个encoder(本文用的是ResNet-50)的传统方法,不过提出了几个创新点。
1. 创新点一
选取最优的数据增强组合方式,
random (crop + flip + color jitter + grayscale).合起来增强
Data augmentation对于训练好unsupervised contrastive learning的模型非常的关键。以下是一张来自论文的图表,可以看出来一些强力的augmentation技巧可以大幅提升SimCLR。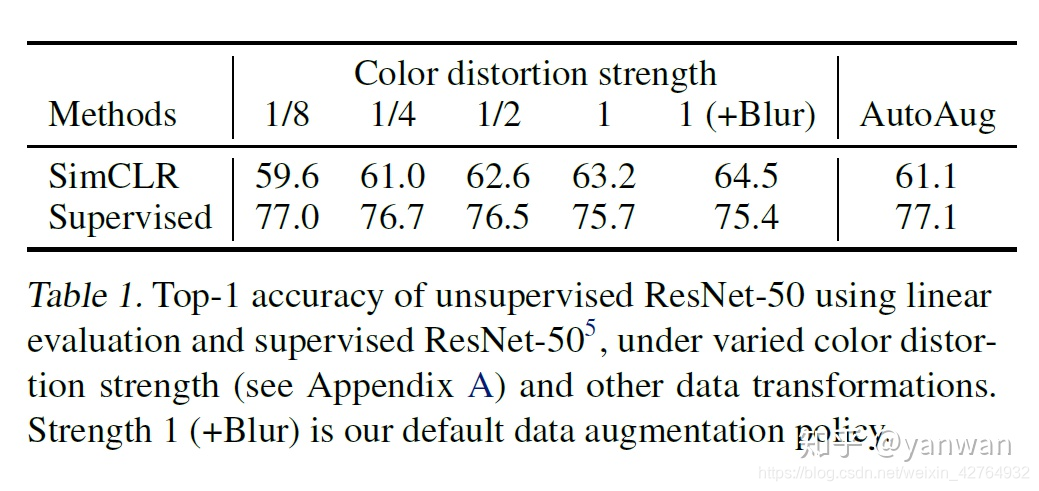
但对于原本supervised的方法却不见得有帮助。
论文中提到一个细节:单纯使用random crop其实没什麽效果,要加上color distortion后才会有显著的效果。这是因为原本的 random crop 切出来的图片 在pixel value的分布其实相差不大,主要是在scale与offset上的不同,相当不利于CNN的CL,而这两种加上color distortion后的 pixel value的分布就会有明显的变化,使得适合作为CL的学习对象
2. Projection Head
在encoder之后增加了一个非线性映射 g ( h i ) = W ( 2 ) R e L U ( W ( 1 ) h i ) ) g(h_{i})=W^{(2)}ReLU(W^{(1)}h_{i})) g(hi)=W(2)ReLU(W(1)hi))
研究发现encoder编码后的 h h h 会保留和数据增强变换相关的信息,而非线性层的作用就是去掉这些信息,让表示回归数据的本质。避免计算 similarity 的 loss function在训练时丢掉一些重要的feature。注意非线性层只在无监督训练时用,在迁移到其他任务时不使用。
“在personreid等metric learning的task里面,有时候总是在加一个non-linear projection head,在head之前用ID loss训练,在head之后用metric learning loss训练。head之前和head之后的embedding空间到底哪个更适合retrieve任务,本质有何不同?“”-------来自知乎,我自己也好奇
head中的L2 normalization去掉之后,会让contrastive task精度变高,但会导致representation的结果变差,加入L2约束本质是降低head的复杂度,使得head不会为所欲为,也就变相减少了head处理信息的能力,其前的空间保留的信息就多了,或者说整个网络会更稳定一些了,泛化性改善了。
3. Contrastive Loss Function
这是普通的对比学习的损失
L y = − log e x p ( y ⋅ y ′ / τ ) ∑ i = 0 N e x p ( y ⋅ y ′ / τ ) L_{y}=- \log \frac{exp(y \cdot y^{\prime}/ \tau)}{\sum _{i=0}^{N}exp(y \cdot y^{\prime}/ \tau)} Ly=−log∑i=0Nexp(y⋅y′/τ)exp(y⋅y′/τ)
而文章在算contrastive loss时使用在NT-Xent (the normalized temperature-scaled cross entropy loss),并证明效果会比较好。
重点在于normalized embedding与appropriately adjusted temperature parameter,公式如下,可以把它当成一种算similarity的延伸方法就好。
- 首先求除以模的互信息,就是用normalized embedding求互信息
s i m ( u , v ) = u T v / ∣ ∣ u ∣ ∣ ∣ ∣ v ∣ ∣ sim(u,v)=u^{T}v/||u||||v|| sim(u,v)=uTv/∣∣u∣∣∣∣v∣∣ - 然后再算损失 c i , j = − log e x p ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N l [ k ≠ i ] e x p ( s i m m ( z i , z k ) / τ ) c_{i,j}=- \log \frac{exp(sim(z_{i},z_{j})/ \tau)}{\sum _{k=1}^{2N}l_{\left[k \neq i \right]}exp(sim m(z_{i},z_{k})/ \tau)} ci,j=−log∑k=12Nl[k=i]exp(simm(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中, z i z_i zi 和 z j z_j zj 是从Projection Head获得的输出矢量
4. 加点负例
计算loss时多加了负例。
以前都是拿右侧数据的N-1个作为负例,SimCLR将左侧的N-1个也加入了进来,总计2(N-1)个负例。
另外SImCLR不采用memory bank,而是用更大的batch size,最多的时候batch size为8192,有16382个负例。。。。。。。
这他妈真牛*,这篇文章告诉大家,只要有钱,batch size往大里造就完事了,每个batch中除了positive以外的都当negatives就已经足够了。有钱人不屑于奇技淫巧。。。
实验结果
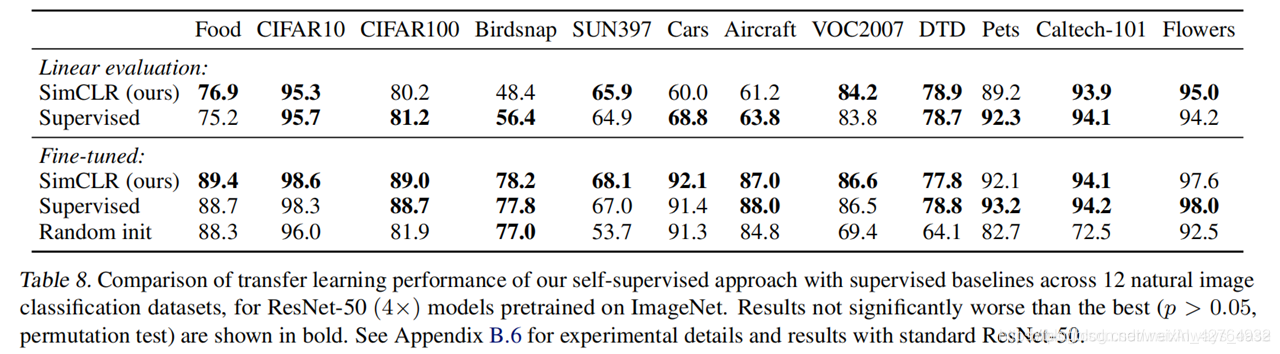
无话可说,就是强
下游任务
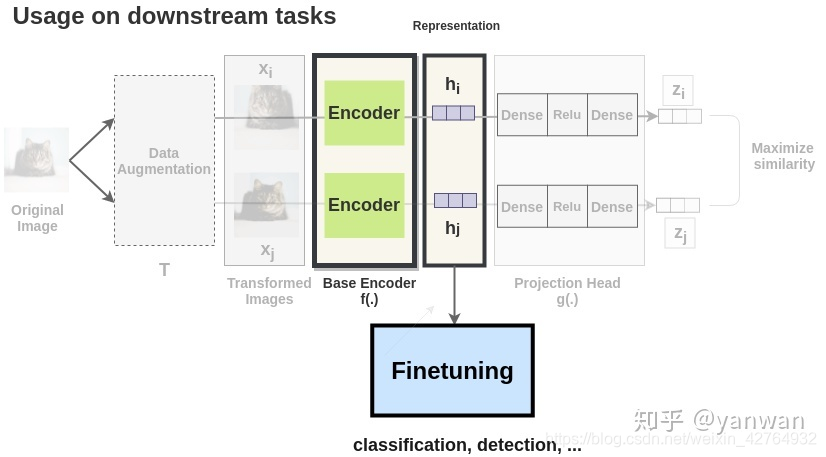
预训练后,使用encoder的representation,不用Projection Head
几个实验现象
- 没有一个单一的变换足以学习好的表示
- 色彩失真是拼接裁剪的关键
- 数据增强虽然不能为监督学习带来准确性方面的好处,但仍然对对比学习有相当大的帮助
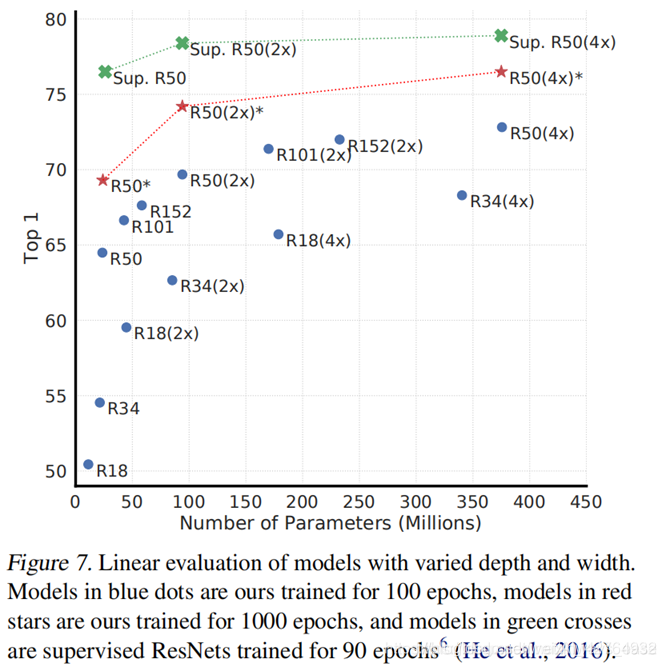
。 - 无监督对比学习从大型模型中获益(更多)
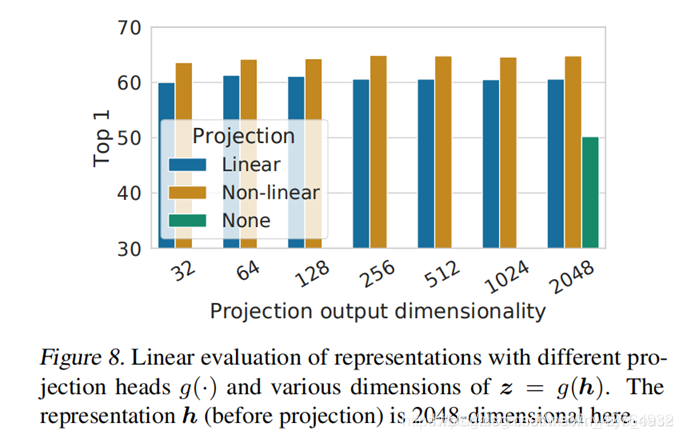
- Projection Head 非线性投影比线性投影好
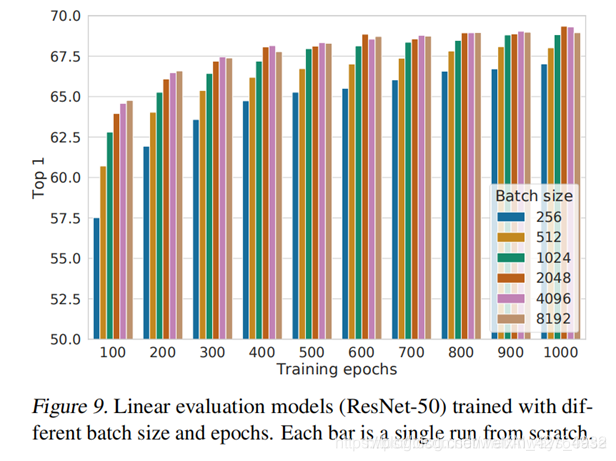
- 对比学习从更大的batch和更长的train中获益(更多)
膜拜下一作大佬
该论文的第一作者 Ting Chen 现就职于谷歌大脑,他 2013 年本科毕业于北京邮电大学,从 2013 年到 2019 年在美国东北大学和加州大学洛杉矶分校攻读计算机科学博士学位。2019 年 5 月,他正式入职谷歌大脑,成为研究科学家。此前他在谷歌有过两年的实习经历。

何凯明和Chen Xinlei同学不服气
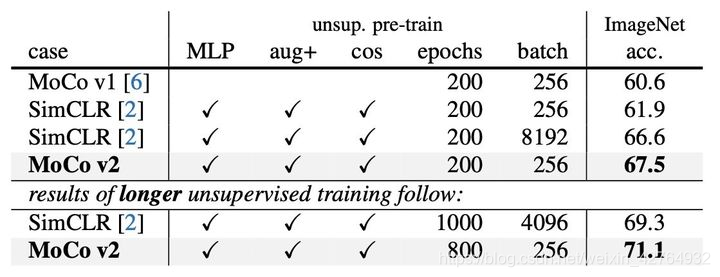
师夷长技以制夷,梅开二度,三阳开泰,我唱着歌让你裸绞