学习的视频来自:yolov3理论讲解_哔哩哔哩_bilibili
简介:
mAP中的对比参数指标

论文地址:YOLO1
YOLO v.s Faster R-CNN
1.统一网络:YOLO没有显示求取region proposal的过程。Faster R-CNN中尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络.相对于R-CNN系列的"看两眼"(候选框提取与分类),YOLO只需要Look Once.
2. YOLO统一为一个回归问题,而R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
YOLO1
论文名:You Only Look Once: Unified, Real-Time Object Detection
在2016 CVPR 数据集上 图片规格为45FPS 448x448 只有63.4mAP,速度比Faster R-CNN快,但是准确率没有Faster R-CNN高。
论文思想
1) 将一幅图像分成SxS个网格(grid cell), 如果某个object的中心落在这个网格 中,则这个网格就负责预测这个object。如狗肚子部位的一个网格

2)每个网格要预测B个bounding box,每个bounding box 除了要预测位置之外,还要附带预测一个confidence值。 每个网格还要预测C个类别的分数。

用下面一幅图加深理解:

左侧是一个7*7*30的特征矩阵,将沿着深度方向一行拎出来,这个列向量有30 个数值;每个网格需要预测两个bounding box,每个bounding box要预测5个数值,这5个值中包含4个目标的坐标信息,以及一个confidence;如上图有两组bounding box;然后针对这个网格预测C个类别分数。

(x,y)是在所选网格之中的,长和宽也是相对真个图像而言的。

confidence可以简单的理解为预测的目标和真实目标的交并比IOU, Pr是0或1,即网格中有目标就为1,没目标就为0
网络结构

损失函数
采用误差平方和(sum-squared error)的方法进行计算
上图中黄色框使用根号的原因:因为可以使small bbox和big bbox的误差更小,如下图所示

YOLO1存在的问题

1.有很多小目标聚集在一起时,预测效果很差
2.目标有了新的位置时预测效果不准确
YOLO2
论文名: YOLO9000: Better, Faster, Stronger
因为所能检测的目标种类个数超过9000
文章中给出的性能对比

YOLO2在YOLO1的基础上做了哪些尝试:在原文中的Better章节

Batch Normalization

减少了所需的一系列正则化处理,相比没有使用BN前,在mAP上提升了2%,而且使用BN后可以不在使用dropout
High Resolution Classifier

提高图片分辨率, 比之前有4%的提升
Convolutional With Anchor Boxes.

不使用anchor时mAP是69.5,召回率是81%
使用anchor时mAP是69.2,召回率是88%
更高的召回率意味着模型的提升空间更大。
Dimension Clusters.


采用了k-means聚类的方法。
Direct location prediction

在使用anchor时,会很不稳定,主要原因是中心的(x,y)预测不准导致的,因为这个公式是没有受到限制的,所以基于anchor预测的目标可能会出现在任意位置,因此作者想了一个办法来解决这个问题。下面结合一幅图来说明:
将anchor设置在每个grid cell的左上角,通过网络的预测后,会得到一个有关x,y的回归参数,由于公式并没有限制 和
的值,那么将anchor的中心坐标加上预测的回归参数后,它可能会出现在图像的任意一个地方,因此很不稳定

作者采用另外一种方法

用函数sigmoid限制 和
,将输入映射到0-1之间,这样就对预测的中心坐标的偏移量进行了限制,这样就可以让每个anchor去负责预测目标中心落在某个grid cell区域内的目标
Fine-Grained Features


将相对底层的特征图和高层的特征图进行融合,提升检测小目标的效果
如下图蓝色框框选的位置,就是将特征图融合的过程,在深度方向进行拼接

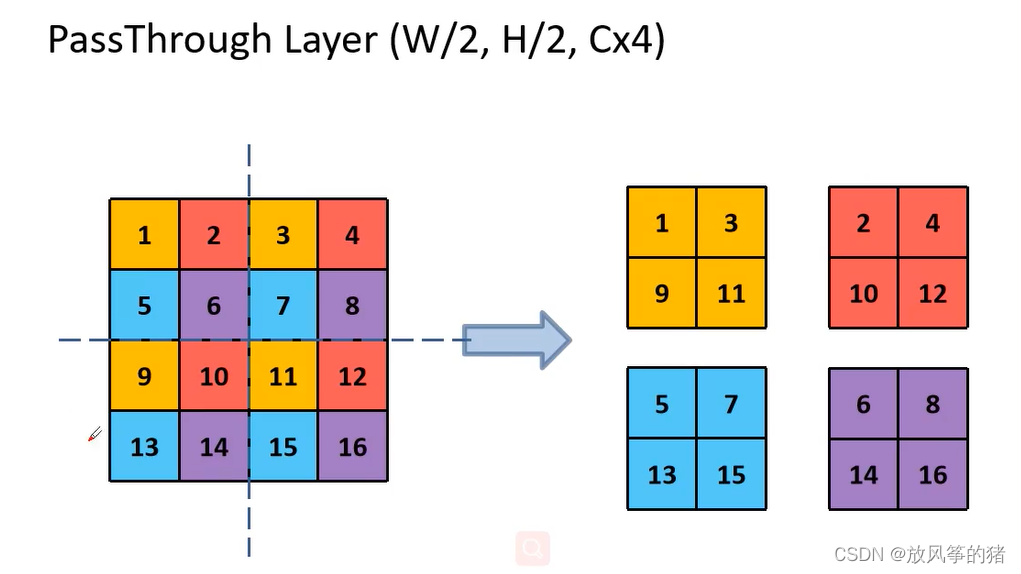
用下面的例子来进行理解:
这里有4*4的特征矩阵,将同一种颜色的特征矩阵拼接到一起,就得到了4个2*2 的特征矩阵,长宽变为原来的一半,通道变成了4倍
Multi-Scale Training

每训练10个batches就随机调整图像的尺寸,采用的一系列大小都是32 的整数倍
BackBone: Darknet-19
Darknet-19(224x224) only requires 5.58 billion operations to process an image yet achieves 72.9% top-1 accuracy and 91.2% top-5 accuracy on ImageNet.

YOLO3
论文名:YOLOv3: An Incremental Improvement
做大做强,再创辉煌
文章整合了一些比较好的内容,创新点较少
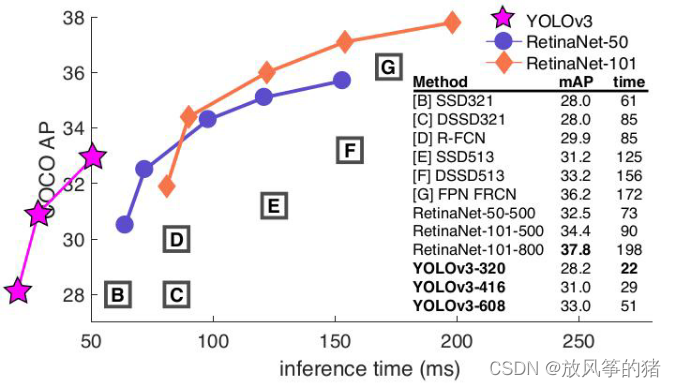
在COCO AP上速度快但准确率不高
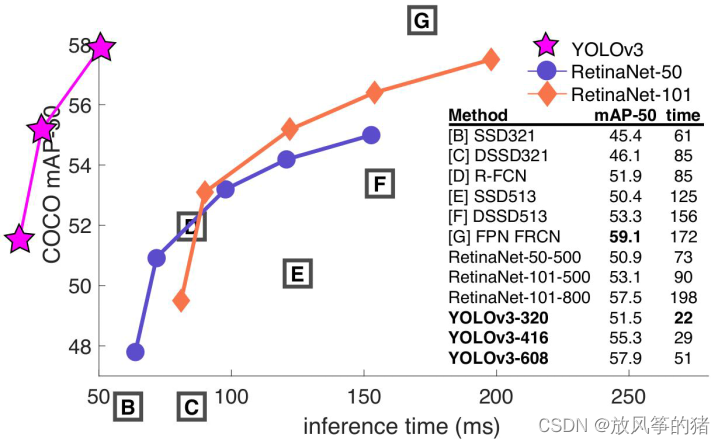
但是COCO AP IOU=0.5 时,正确率高了很多
BackBone: Darknet-53
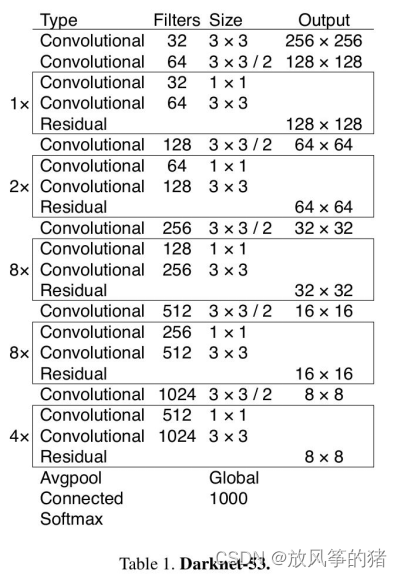
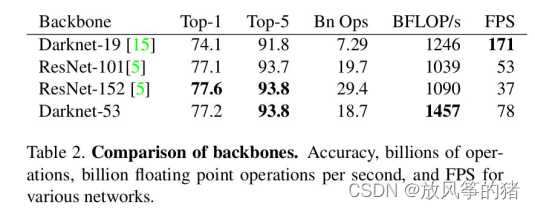
层数:

可能时因为层数比resnet少以及去掉了全连接层才使性能变好。
网络结构
下图绿色部分conv是由三部分组成的,分别为:conv,BN(没有偏置参数),leakyReLU
蓝色框中是一个残差结构:主分支为一个1*1卷积和一个3*3的卷积,再将捷径分支直接从输入引过来与输出相加;

通过第一个conv set(将5个conv堆叠在一起)后
一条分支通向预测输出1,先通过一个3*3的conv,大小为13*13,再使用一个卷积核大小为1*1的预测器再预测特征层上进行预测
另外一个是接着往后走,先通过一个1*1的卷积层,再通过一个上采样层,高和宽扩大为原来的两倍,即26*26,此时会和darknet-53中的一部分输出再深度方向进行拼接
接着在经过一个conv set,一个分支通向预测输出2,另一只经过上采样变为52*52,再和darknet-53中的一部分输出再深度方向进行拼接
再通过一个conv set得到预测输出3
在预测特征层1上预测较大的目标,在预测特征层2上预测中等的目标,在预测特征层3上预测较小的目标
YOLO V3 model structure

在3个预测特征层上进行预测,每个预测特征层上使用3种尺度,原文中使用k-means聚类的算法得到
每个特征层上会预测N*N*[3*(4+1+80)]个参数
N是预测特征层的大小,每个sell会预测3个尺度,每种尺度会预测4+1+80个参数,分别为4个偏移参数,1个confidences ,coco数据集有80个分类
目标边界框的预测
yolov3使用的anchor机制和ssd,faster-rcnn是不一样的:
ssd,faster-rcnn中预测的关于目标中心点的回归参数是相对于anchor而言的
yolov3中目标中心点的回归参数并不是相对于anchor而言的,而是相对于当前这个sell的左上角点的
假设下图是某一个预测特征层,当1*1的卷积层滑动到中间红色部位的时候,他会针对每一个anchor模板都会预测4个回归参数,一个confidence,以及每个类别的分数
4个回归参数分别为 图中 的虚线框对应的是anchor,现在只需要关注
就可以了,图中蓝色的框是预测的最终目标的位置和大小
是当前这个gril sell左上角的坐标
通过下面的公式就可以算出最终预测中心点x,y的坐标

sigmoid函数算出的值在0-1之间

正负样本的匹配
原文如下:

按原文所说的正样本的数量会非常少,不好训练
代码中样本的匹配准则:
将GT和anchor模板计算得到iou,接着设置一个阈值,只要iou大于这个阈值都设置为正样本
再将GT映射到特征层上,GT 的中心点落在哪个cell中,则该cell中的AT 2 就作为正样本,如果这3个anchor和GT 的iou都大于阈值,就同时将GT分配给3个anchor,这样就可以扩充正样本

损失的计算

置信度损失
二值交叉熵损失


例子:

使用二值交叉熵损失,经过sigmoid函数处理,每个预测结果之间互不干扰,相互独立,
