前段时间将yolov1和yolov2学习了一下,这段时间一直在看yolov3的论文和源代码,yolov2速度和精度还算可以但是不足以用于工业上,但是yolov3的精度和速度都有很好的提升,并且得到很广泛的应用,现如今也有非常多的工业仍然在使用yolov3,可见其重要性。接下来谈谈我对yolov3这篇论文的理解。
参考资料:yolov1论文笔记_crlearning的博客-CSDN博客
YOLOv2论文笔记_crlearning的博客-CSDN博客
论文地址:https://pan.baidu.com/s/14azVbNgRpYn_uIG00DO8mQ 提取码: 6666
源码地址:https://pjreddie.com/yolo/
目录
1、摘要
yolov3这篇论文与v1v2是同一个作者,但由于实时监测技术的快速提高,大多用于军工类导致更多的战争,作者表明并不是其本意并表示yolov3是其最后更新的一次。所以在这篇论文当中作者仅仅写了5面的内容,其中很多没有讲的很详细,很多细节需要大家从源码当中去了解。
yolov3在原来的基础上做出一些改进,使用了更大的模型,让yolov3能够与其他高精度的检测模型达到相同精度,但是速度快三倍,如SSD。

2、创新点
2.1、边界框预测
在yolov2当中提到预测边界框使用了聚类anchors,并预测偏移量而不是yolov1当中整个坐标值,yolov3论文再一次提到了该预测计算方式,其中还提到对每个bbox进行评分,如果bbox与真实框(有些博文称为GT,ground truth)的重叠率是最大的,则分数为一,若不是最大,且没有超过一定的阈值,则抛弃该bbox,这样不会导致坐标的损失。
2.2、类别预测
yolov3抛弃了使用softmox作为多分类器,使用logistic classifiers,计算损失时使用二分类交叉熵损失函数,主要原因是因为在大数据集上,一种物体的种类可能是重叠的,比如哈士奇它是一只狗,但他属于狼狗。而softmax要求每个种类相互独立分布,所以在大数据集上并不适用,作者使用二分类来处理。
2.3、多尺度预测
yolov3中的anchor使用3个不同的尺度,系统从这些尺度中提取特征,采用FPN(特征金字塔网络)概念,网络模型如下图:
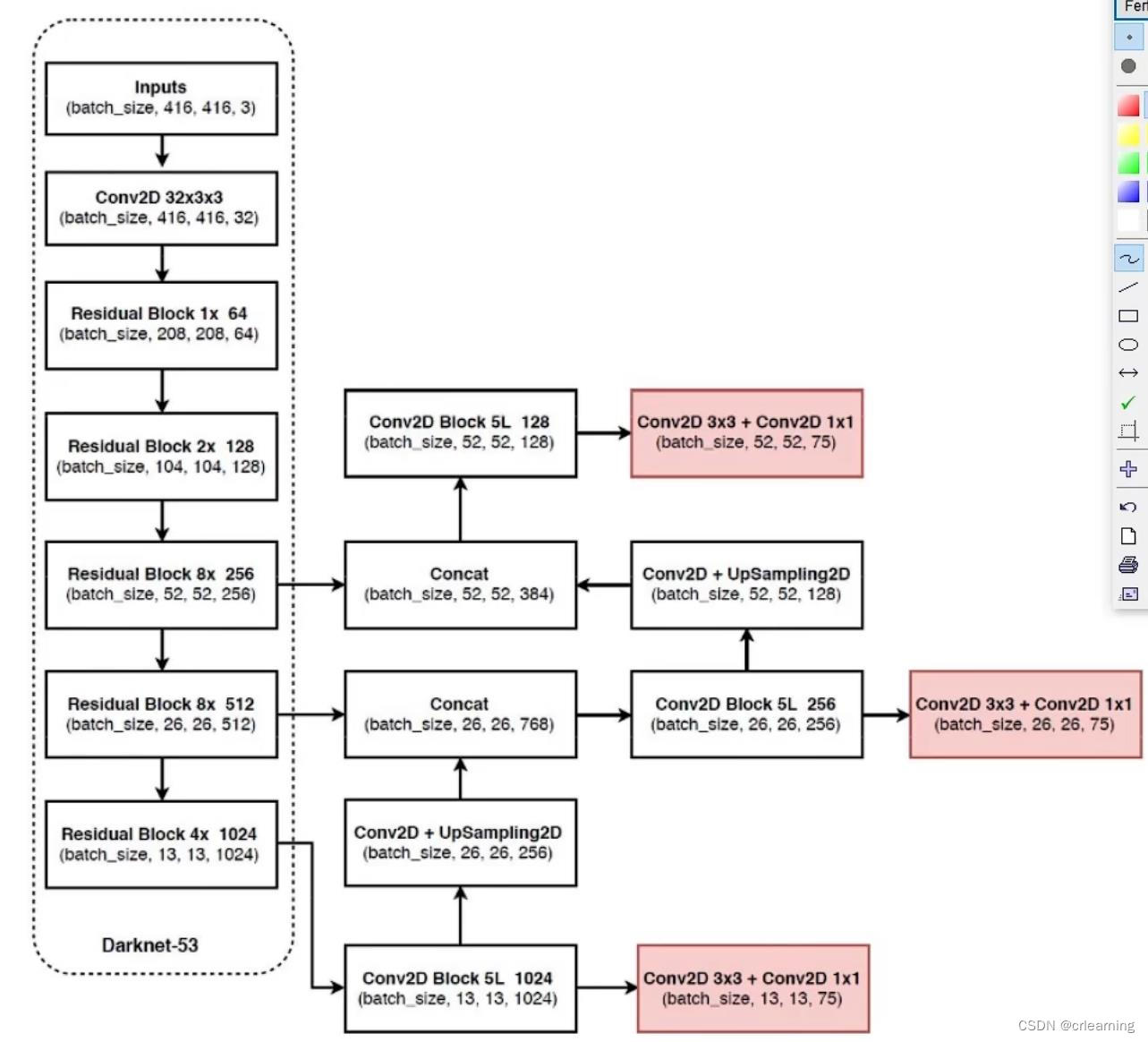
三个红色预测头的对应三个维度的输出,在yolov2当中,输出只有一个13 x 13的维度,在yolov3中,作者提出多尺度预测,就是分别针对大中小物体使用不同的输出,在yolov2中提到,卷积越深,信息丢失可能越多,所以使用FPN的方式,进行上采样concat原来的数据 能够大幅度保留细小的信息,这也方便对小目标进行预测。
yolov2中使用的5个anchor,yolov3使用聚类出9个anchor分别为:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116 × 90),(156 × 198),(373 × 326)。
2.4、特征提取器
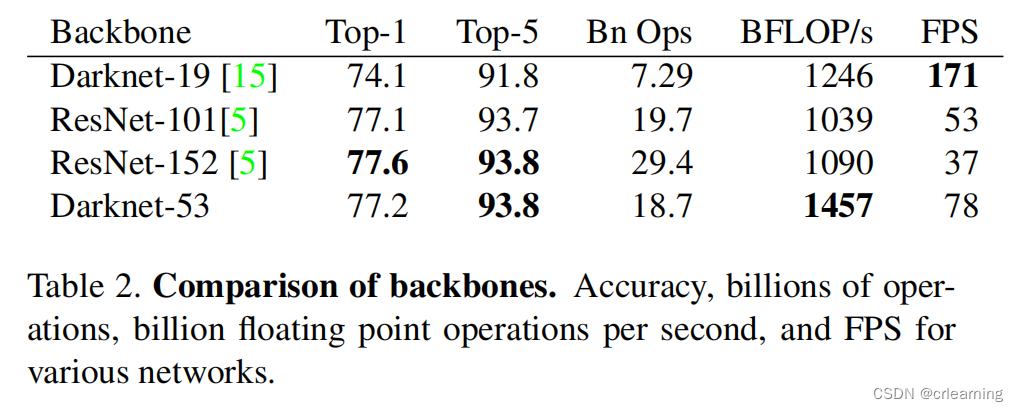
主干网络采用Darknet53,包含53层卷积,与yolov2中的darknet19对比,darknet53步幅为2的卷积层替代池化层进行特征图的降采样操作,这样可以有效阻止由于池化层导致的低层级特征的损失。对比其他网络,Darknet53对比其他网络有非常高的精度并且也有相对高的速度。
3、实验结果
作者在实验中表示,如果将IOU提升到一定阈值后,继续增加导致性能显著下降,这说明yolov3很难使得box与对象完全对齐,并且yolov3使用多尺度预测后对小目标的ap提高了很多,但是对中等和较大目标的性能相对较差。
作者也是用了一些技巧但是模型并没有得到相应的提高,第一,使用线性模型直接预测x,y偏移量而不是使用logistic,这会使得map降低。第二,使用focal loss也会使得map降低。
