论文地址:
《YOLOv3: An Incremental Improvement》
yolov3论文作者比较幽默,论文整体内容中创新点和技术分布较为零散,有兴趣的可以去看看原论文;
yolov3是对于v1、v2的一种改进,相对v2主要的改进有:调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax;在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。
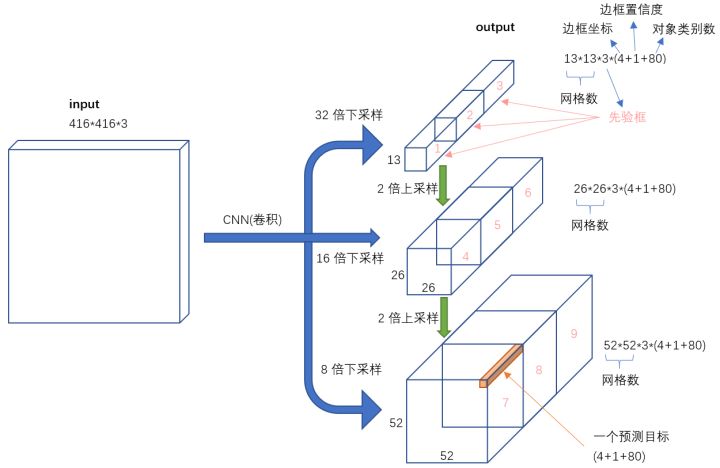
YOLO v3的整体结构如下图所示:
主要亮点在于用3个尺度的特征图来进行对象检测,对检测小物体的效果有所提升。
1. yolo v3详解
yolov3目标检测分两步:
- 确定检测对象位置
- 在检测框内对检测对象进行分类
即在识别图片中各类目标的基础上,还需定位出识别对象的位置,并框出。
确定检测对象位置
即需要在图片中框出检测对象的位置,在图片上框出这个矩形框需要4个参数:分别是矩形框的中心点坐标(x_offset, y_offset),矩形框的宽width,高height;
在检测框内对检测对象进行分类
在yolo v3中,每个grid都有3个bounding box,应该挑选哪个bounding box呢:在训练中选取准则是选择预测的bbox与ground truth box的IOU最大的bbox做为最优的bbox,但在预测中并没有ground truth box,怎么才能挑选最优的bbox呢?这就需要另一个参数--置信度
置信度是每个bbox输出的一个重要参数,作用如下:
(1)代表当前bbox是否有对象的概率,即用来说明当前bbox内只是背景还是有物体;
(2)bbox有对象时,它自己预测的bbox与物体真实的bbox可能的值,注意,这里所说的物体真实的box实际是不存在的,这只是模型表达自己框出了物体的自信程度。
即置信度表示一种自信程度bbox内确实有物体的自信程度和框出的bbox将整个物体的所有特征都包括进来的自信程度,这个bbox里确实框住了某一个物体和该bbox和真实的目标检测框的重合程度的综合度量指标:
。
表示第i个grid cell的第j个bounding box的置信度。
2. yolo v3框架
借用网上的一张图,讲的很清楚:

再来一张流程图: 下图是基于voc数据集的,voc数据集有20个类别,最下面红框中(13,13,75)表示预测结果的shape,实际上是13,13,3×25,表示有13*13的网格,每个网格有3个先验框(又称锚框,anchors),每个先验框有25个参数(20个类别+5个参数),这5个参数分别是x_offset、y_offset、height、width与置信度confidence,用这3个框去试探,试探是否框中有物体,如果有,就会把这个物体给框起来。如果是基于coco的数据集就会有80种类别,最后的维度应该为3x(80+5)=255,上面两个预测结果shape同理。
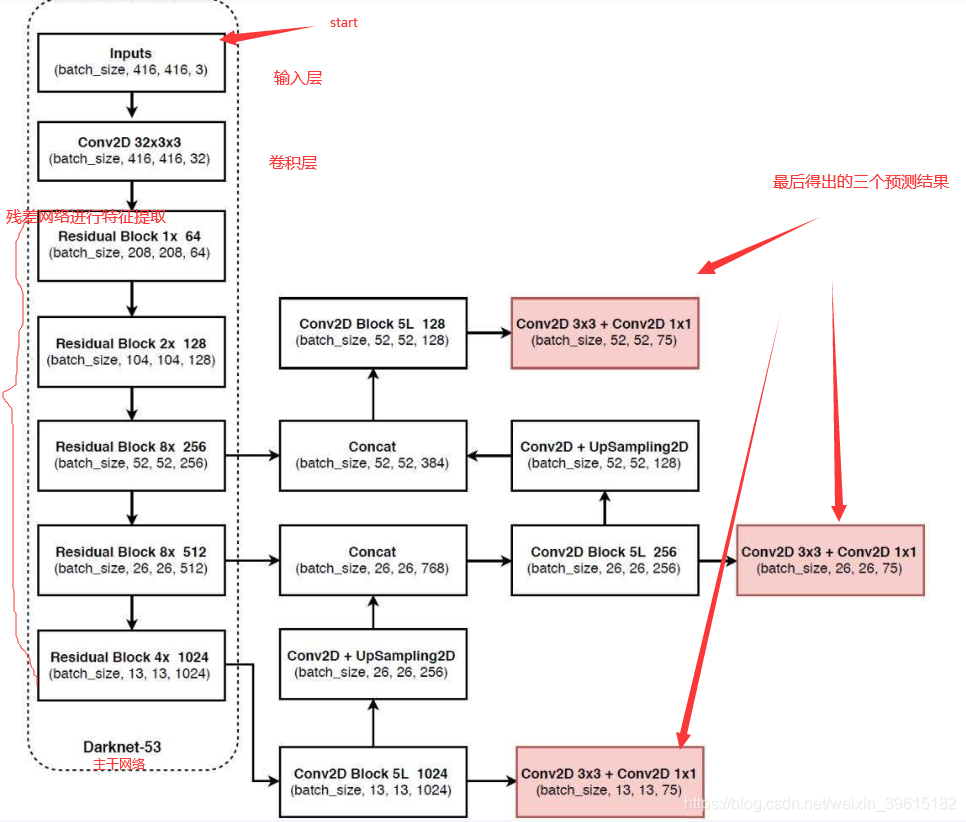
整个框架可划分为3个部分:分别为Darknet-53结构、特征层融合结构(上图concat部分)、以及分类检测结构;
Darknet-53结构、特征层融合结构:
Darknet53为yolo v3的主干特征提取网络,输入的图片首先会在Darknet-53里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合,在主干部分,网络获取了三个特征层进行下一步网络的构建,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024),这三个特征层后面用于与上采样后的其他特征层堆叠拼接(Concat):
第三个特征层(13,13,1024)进行5次卷积处理(特征提取),处理完后一部分用于卷积+上采样UpSampling,另一部分用于输出对应的预测结果(13,13,75),Conv2D 3×3和Conv2D1×1两个卷积起通道调整的作用,调整成输出需要的大小;
卷积+上采样后得到(26,26,256)的特征层,然后与Darknet53网络中的特征层(26,26,512)进行拼接,得到的shape为(26,26,768),再进行5次卷积,处理完后一部分用于卷积上采样,另一部分用于输出对应的预测结果(26,26,75),Conv2D 3×3和Conv2D1×1同上为通道调整;
之后再将3中卷积+上采样的特征层与shape为(52,52,256)的特征层拼接(Concat),再进行卷积得到shape为(52,52,128)的特征层,最后再Conv2D 3×3和Conv2D1×1两个卷积,得到(52,52,75)特征层;
因此最后图中有三个红框原因就是有些物体相对在图中较大,就用13×13检测,物体在图中比较小,就会归为52×52来检测。
分类检测结构:
通过Darknet53和特征层融合,我们已经可以获得三个加强过的有效特征层,他们的shape分别为(52,52,128),(26,26,256),(13,13,512)。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。
3. yolo v3检测流程
step1:数据集导入
导入图片与真实标签,标签中含有图片中的真实框信息——坐标宽高和类别;
step2:图片类型转换
yolo会将其转化为416×416大小的输入,增加灰度条用于防止失真:图片来自大佬博客:https://blog.csdn.net/weixin_39615182/article/details/109752498

step3:生成Anchor
Anchor生成算法:主要思想就是用iou进行K-means聚类;
在 YOLOv3 算法里一共有3种不同尺度预测,每个不同尺度的网格有3个bbox,所以最终为 9 个先验框;
step4: 特征提取
即经过主干网络处理得到的特征层在经过特征金字塔处理得到三个加强过的有效特征层;
step5:预测结果的解码
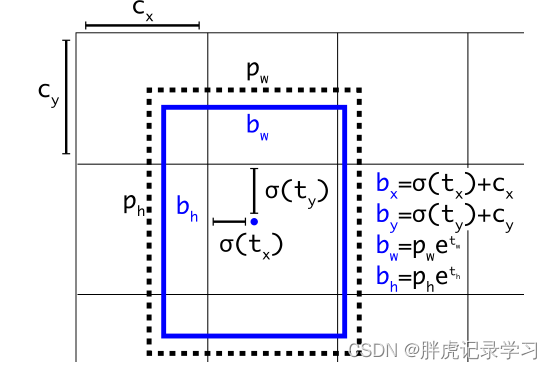
预测结果并不对应着最终的预测框在图片上的位置,yolov3的预测原理是分别将整幅图分为13x13、26x26、52x52的网格,每个网络点负责一个区域的检测,解码过程就是计算得出最后显示的边界框的坐标bx,by,以及宽高bw,bh,这样就得出了边界框的位置

(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
(pw,ph):先验框的边长
(tx,ty):目标中心点相对于该点所在网格左上角的偏移量
(tw,th):预测边框的宽和高
σ:激活函数,论文作者用的是sigmoid函数,[0,1]之间概率,之所以用sigmoid取代之前版本的softmax,原因是softmax会扩大最大类别概率值而抑制其他类别概率值
step6:非极大值抑制(NMS)
将最大概率的框筛选出来:取出每一类得分大于一定阈值的框和得分进行排序;利用框的位置和得分进行非极大抑制;最后可以得出概率最大的边界框,也就是最后显示出的框;
非极大值抑制(non-maximum suppression)的理解
step7:选择预测特征点的先验框
在训练中确定哪个bounding box负责某个ground truth:方法是求出每个grid cell中每个anchor box与ground truth box的IOU(交并比),IOU最大的anchor box对应的bounding box就负责预测该ground truth,也就是对应的对象。真实框的中心落在哪个cell里,就由该cell里的iou最大的那个锚盒进行回归预测。
参考文献: