学习视频:yolov3spp理论讲解(包括CIoU以及Focal Loss)_哔哩哔哩_bilibili
简介:
下图为U版的yolov3-spp文论中的,U版比普通yolov3 的mAP高了近10个点,本文将按左侧4个部分开始讲解

Mosaic图像增强
将多张图片拼接在一起输入网络进行训练的过程,论文中默认4张图片拼接

优点:增加数据的多样性
增加目标个数
BN能一次性统计多张图片的参数:训练网络是batch size要尽量设置的大一点,因为BN层主要就是求每一个特征层的均值和方差,如果batch size越大,所求的均值和方差就约接近整个数据集的均值和方差,效果就会越好,但是有时候由于设备受限,GPU显存不能一次性训练那么多张图片,这里将多张图片拼接在一起输入网络,这样就变相的增加了输入网络的batch size
SPP模块
注意:这里的SPP和SPPnet中的SPP结构不一样 ,这里只是借鉴了SPP-Net的SPP结构。
网络结构图:相比之前的yolov3的结构图,只是在conv set中间增加了一个spp结构,其他部分没有变化。
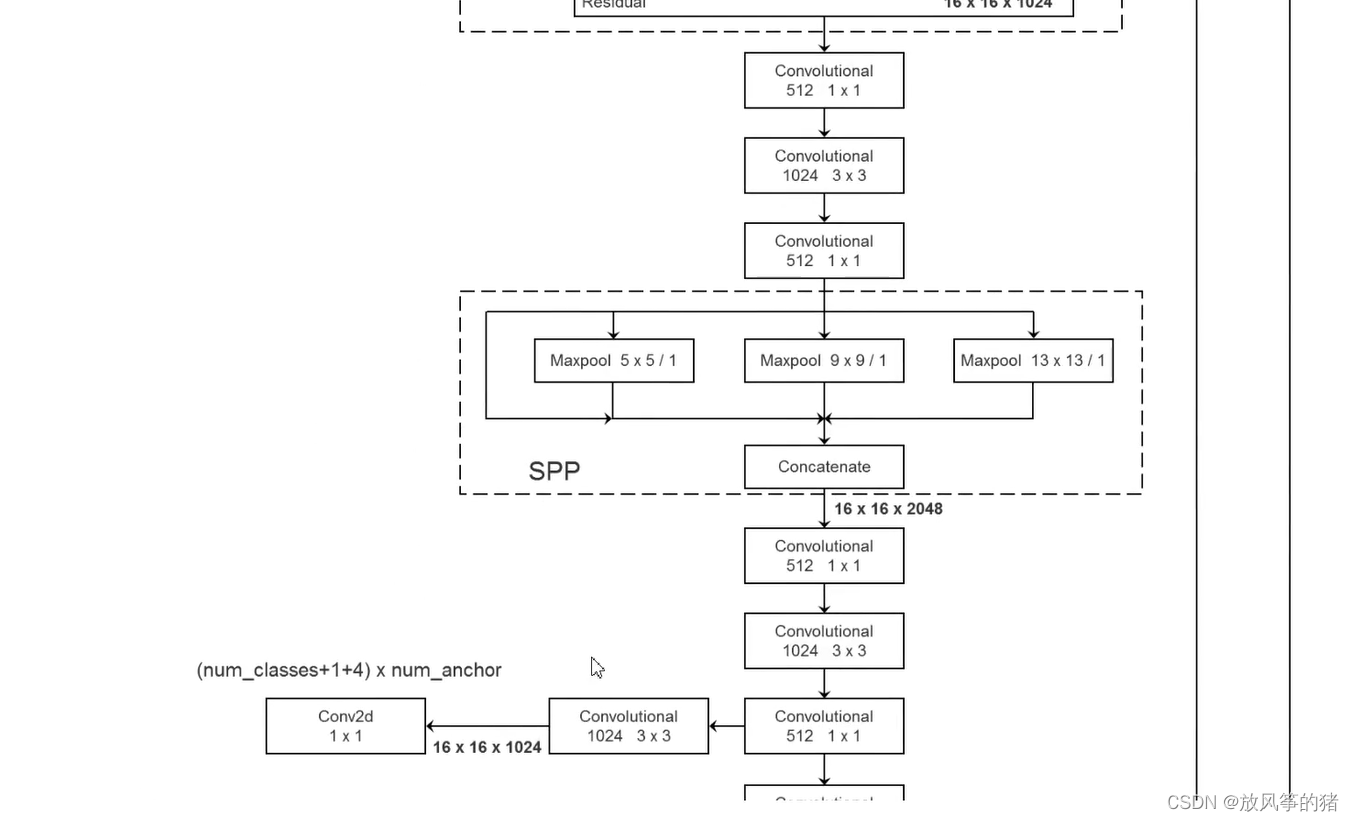
yolov3和 YOLOv3 SPP的结构图对比

spp模块:实现了不同尺度 的特征融合

第一个分支:直接从输入接到了输出
第二个分支:池化合大小为5*5的最大池化下采样
第三个分支:池化合大小为9*9的最大池化下采样
第四个分支:池化合大小为13*13的最大池化下采样
这里的步距都为1,这意味着做池化之前会对特征矩阵进行padding填充,填充之后,再进行最大池化下采样所得到的特征图的高和宽是没有发生任何变化的,所以这四个分支输出的高,宽和深度是一样的,最后再进行concatenate拼接
为什么只在第一个conv set中间加了spp模块?
可以在第二个,第三个conv set中间加spp模块吗?当然是可以的
如下图:橙色的线代表YOLOV3-SPP1:即只加一个spp模块
浅绿色的线代表YOLOV3-SPP3:即加3个spp模块
可以看到,当输入网络的尺度比较小时,YOLOV3-SPP1的性能好一点,当输入网络的尺度变大时,YOLOV3-SPP3的效果就会优于YOLOV3-SPP1,这样看来效果变化不是很明显

CIoU Loss
发展过程如下
DIoU Loss 和 CIoU Loss 是在一篇论文中提出来的

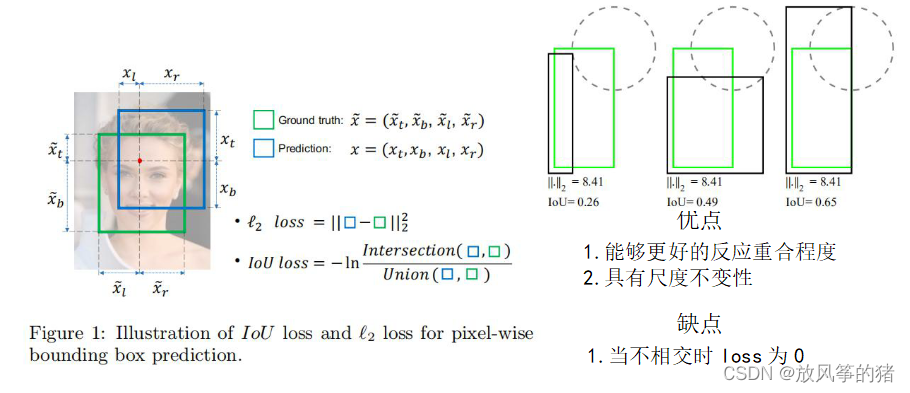
IoU Loss
如下图右侧:展示的是3组重合的实例,可以发现最后一个矩形框的预测结果是相对较好的
但3 组中 ll2 loss 都是相同的,表明 ll2 loss并不能很好的反应两个边界框的重合程度,所以在这篇论文中作者引入了 IoU Loss
下图中为 IoU Loss 的计算公式,优点以及缺点。
GIoU Loss:Generalized IoU

上图中绿色的边界框代表真实的边界框,红色的边界框为网络最终预测的边界框,蓝色的框就是用最小的矩形将两个边界框框起来,蓝色边界框的面积为 ,u为两个边界框的并集,当两个边界框完美重合的时候 GIoU = IoU
GIoU 的上限为1
当两个边界框离的很远不重合的时候,当趋近于无穷大的时候,后面的一项趋近于1,此时IoU为0,GIoU 就为-1
GIoU 的loss在0-2之间
GIoU退化IoU
当两个边界框水平或垂直对齐的时候

DIoU Loss
下图黑色框中提出了问题,之前的损失收敛速度慢且不是很准确
这篇论文针对这两个问题展开

GIoU的效果

上图黑色的边界框代表anchor,绿色代表真实的边界框,可以看到迭代400次才达到比较好的效果
DIoU 的效果

只迭代120次就可以达到非常好的效果

上图表明:IoU和GIoU不能很好的预测两个边界框的位置关系,而DIoU 可以
计算公式:

代表 b 和
之间的欧式距离
b为预测目标中心点的坐标,上图中的黑色框 是真实目标边界框中心点的坐标, 公式中的
就是这两个中心点距离的平方
c为这两个边界框最小外接矩形的距离
DIoU 的范围任然是-1到1,DIoU 的loss任然在0 -2之间
DIoU损失能够直接最小 化两个boxes之间的距 离,因此收敛速度更快。
CIoU Loss
一个优秀的回归定位损失应该考虑到3种几何参数: 重叠面积 中心点距离 长宽比 ,分别和下图中的对应,是CIoU 中新加的


论文中给出的3个案例

Focal loss
大家对这部分褒贬不一
在YOLOV3原文中作者使用的Focal loss后mAP降了两个2点

Focal loss 原文中给出的参数

为0时代表不使用 Focal loss,下面使用后最高可以提升3个点
在论文中作者说 Focal loss 主要是针对One-stage object detection model,如之前的SSD,YOLO,这些模型都会面临正负样本不平衡的问题

一张图像中能够匹配到目标的候选框(正样本)个数一般只有十几个或几十个,而没匹配到的候选框(负样本)大概有10^4-10^5个
在这10^4-10^5个未匹配到目标的候选框中大部分 都是简单易分的负样本(对训练网络起不到什么 作用,但由于数量太多会淹没掉少量但有助于 训练的样本)。
假如
有50个正样本,每个正样本提供的损失为3,则它 的总贡献为 50x3=150
对于那些易分的负样本来说,每个损失为0.1,但因为数量很多,总损失就很大了100,000x0.1=10,000

如上图所示最下面一行是使用Focal loss后的结果,效果提升了很多