PASCAL VOC 数据集:https://blog.csdn.net/baidu_27643275/article/details/82754902
yolov1阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82789212
yolov1源码解析:https://blog.csdn.net/baidu_27643275/article/details/82794559
yolov2阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82859273
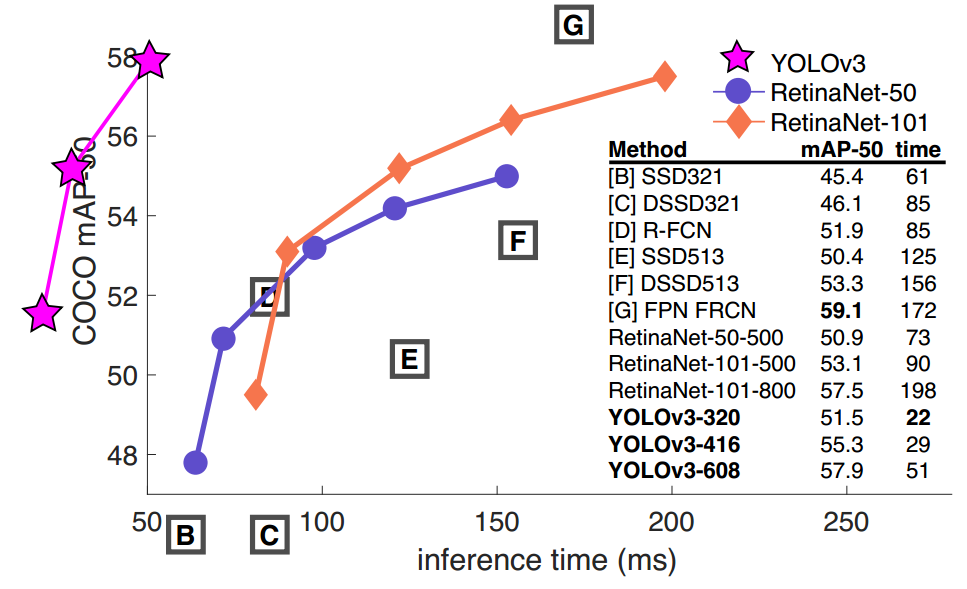
yolov3在yolov2基础上主要做了两大改进:FPN和ResNet,性能极佳。
yolov3改进策略:
1、Class Prediciton
用Sigmoid代替Softmax,这个改进主要是用于多标签分类。Softmax可以用于多分类问题,但是类别之间必须互斥,也就是一个目标只有一个标签。但实际应用中,标签可能重叠(如:人和女人),一个物体有多个标签。所以使用Sigmoid代替,训练时loss函数使用binary cross-entropy loss
2、Prediction Across Scales
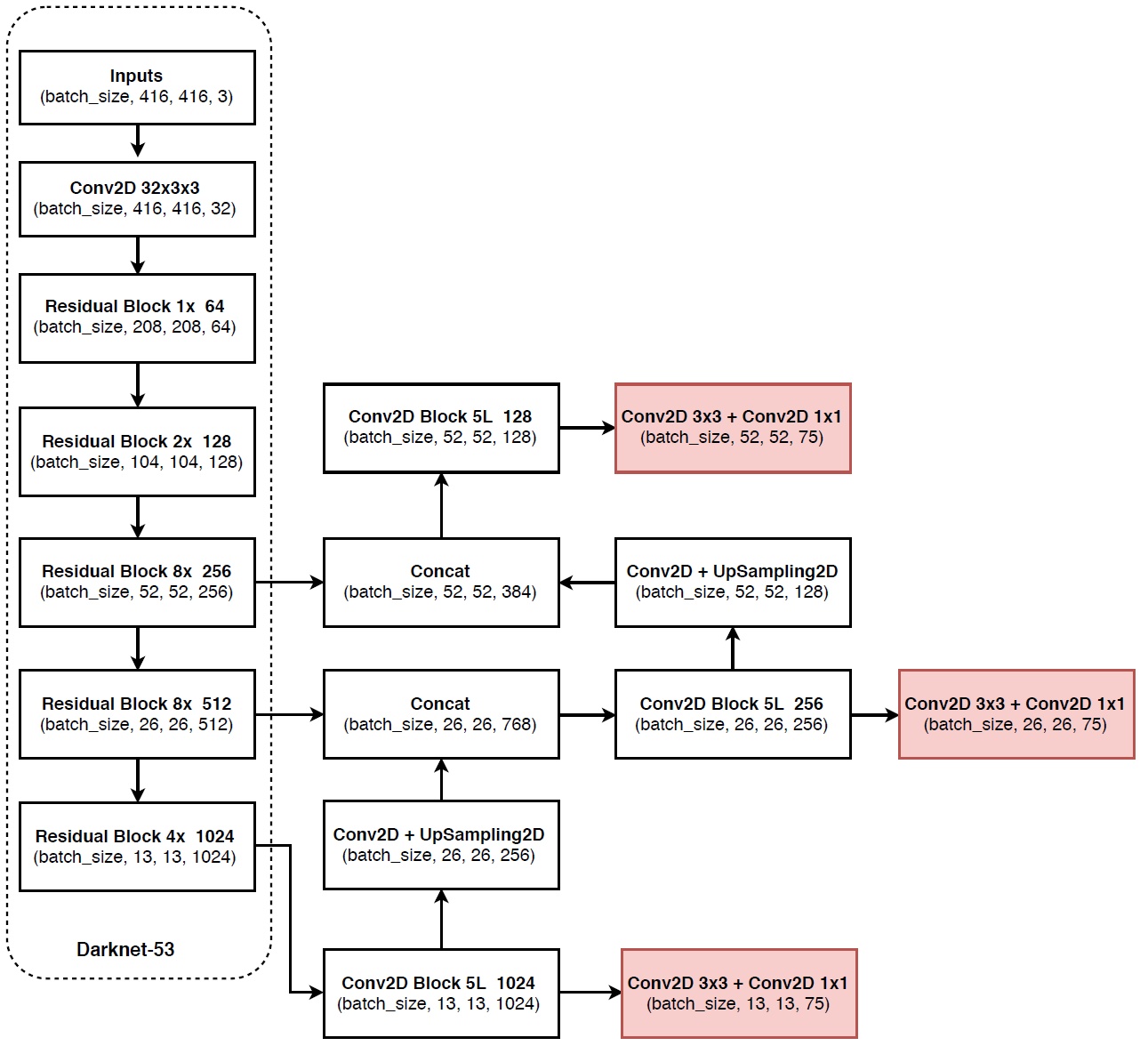
(1)检测网络部分,作者参考了FPN(feature pyramid networks)的思想。用非线性插值方法上采样了两次,获得了3个不同大小的feature maps,每个feature map预测3个anchor boxes。
(2) 由深层、语义特征丰富的负责预测大物体(分配大anchor);浅层、几何特征丰富的负责预测小物体(分配小anchor)。
(3)yolov3在小物体识别上性能很好,可是在大物体和中等物体上性能相对较差。
(就目前来说这种策略对检测小物体已经做到头了,想要再改进,可能要换思路了,如果一味地增大输入尺寸显然是不合理的)
3、Feature Extractor
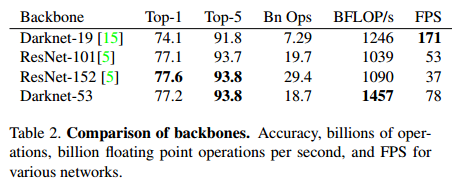
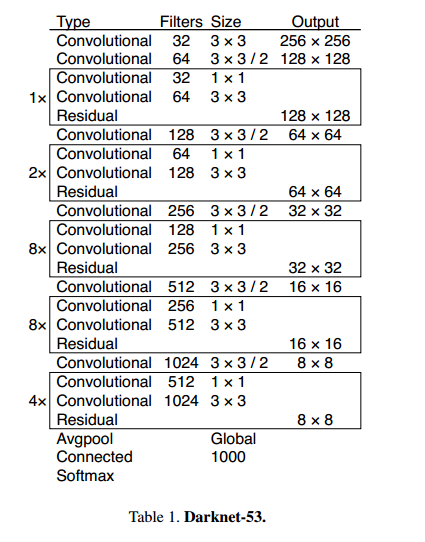
(1)yolov3使用darknet-53来提取特征,网络中使用3×3和1×1的卷积以及residual块;
(2)darknet-53中没有pooling层,而是用步长为2的卷积层代替,避免了信息丢失;
(3)网络有53层,获得的信息更加丰富,网络性能更好。