写在前面
Linear Regression:是回归问题的基础
线性回归的目的:线性回归要做的是就是找到一个数学公式能相对较完美地把所有自变量组合(加减乘除)起来,得到的结果和目标接近
实现的大体步骤
实现步骤:
1.构造数据集
2.读取数据集
3.构建模型
建立网络
建立损失函数
建立优化器
4.训练
初始化参数
前向传播
后向传播
梯度清零
参数优化
1.构造数据集
特征的维度:2 特征的数量:1000 预设模型w的值: [1.5,2.6] 预测模型b的值: -3.6 那么上述过程就等价于如下公式
y = 1.5 x 1 + 2.6 x 2 − 3.6 y=1.5 x_{1}+2.6 x_{2}-3.6 y=1.5x1+2.6x2−3.6
为了让训练时尽可能避免过拟合,为结果加上一个均值为0,方差为0.01的白噪声e,即最终模型可写为
y = 1.5 x 1 + 2.6 x 2 − 3.6 + ϵ y=1.5 x_{1}+2.6 x_{2}-3.6+\epsilon y=1.5x1+2.6x2−3.6+ϵ
import torch
def original_model(x):
return 1.5 * x[:, ] + 2.6 * x[:, 1] - 3.6
def generator_data(dim, num):
x_set = torch.normal(0,1, (num, dim))
y = torch.matmul(x_set, torch.tensor([1.5,2.6])) + torch.tensor(-3.6)
# y = original_model(x set)#
epsilon = torch.normal(0,0.01,y.shape)
return x_set,y + epsilon
features,labels = generator_data(2,1000)
features.shape,labels.shape, features[0],labels[0]
可以看到构造数据

2、读取数据
数据读取就是每次读取一个小批量的数据,其涉及的超参是batch_size
import random
def data_iter(x, y, batch_size):
num = len(y)
data_list = list(range(num))
random. shuffle(data_list)
for i in range(0,num,batch_size):
batch_index = torch.LongTensor(data_list[i: min(i + batch_size,num)])
batch_features = torch.index_select(x,dim=0,index=batch_index)
batch_labels = torch.index_select(y,dim=0,index=batch_index)
yield batch_features, batch_labels
for feature,label in data_iter(features,labels, 10):
print(feature.shape,label.shape)
break

3.构建模型
定义模型
#定义模型
def linear_regression(x,w,b):
out = torch.matmul(x, w)
out = out + b
return out
损失函数
def squared_loss(pred_y, y):
return (pred_y - y.view(pred_y.shape))**2 / 2
定义优化算法
SGD算法
def sgd(params,lr, batch_size):
with torch.no_grad( ):
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
训练模型
#初始化参数
w = torch.normal(0,0.01,size=(2, 1), requires_grad=True)
b = torch.zeros ( 1,requires_grad=True)
#定义超参数
lr = 0.021
num_epochs = 13
batch_size = 20
net = linear_regression
loss = squared_loss
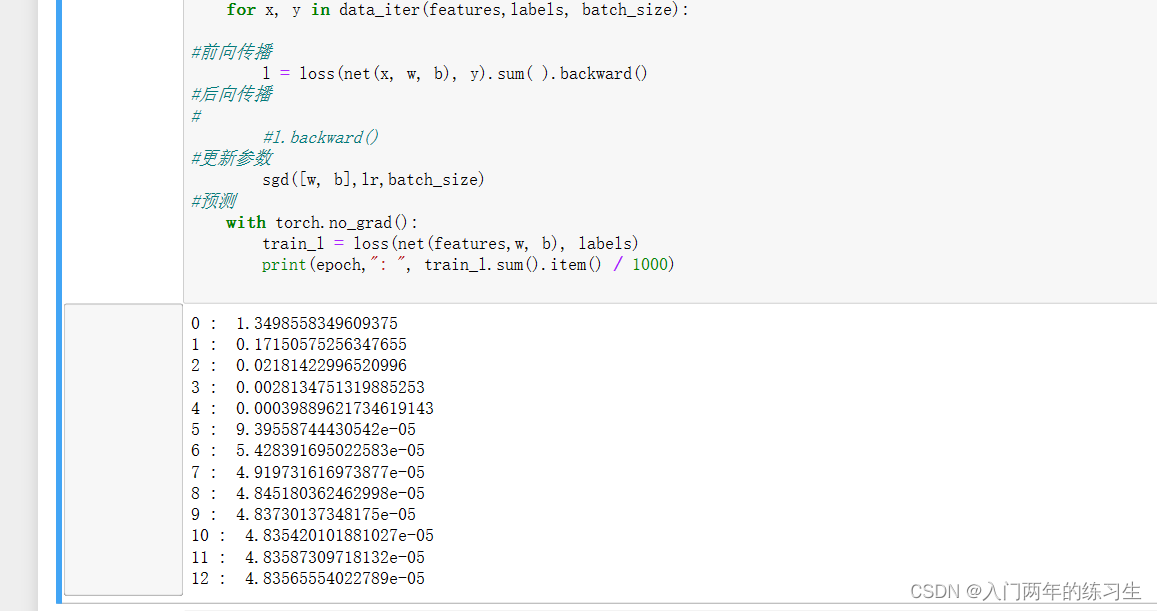
for epoch in range(num_epochs):
for x, y in data_iter(features,labels, batch_size):
#前向传播
l = loss(net(x, w, b), y).sum( ).backward()
#后向传播
#
#l.backward()
#更新参数
sgd([w, b],lr,batch_size)
#预测
with torch.no_grad():
train_l = loss(net(features,w, b), labels)
print(epoch,": ", train_l.sum().item() / 1000)
预测结果: