前言
本文主要用pytorch对线性函数进行拟合,主要用到底层原理中的梯度下降与反向传播,原理可见该博文
前馈神经网络,感知机,BP神经网络
正文
代码相关知识(下面是自己写的注意点,可能有些大家一知半解,可以看视频讲解):
1、requires_grad表示变量后面是否需要计算梯度,正常情况下是False
2、反向传播能得到梯度,而x.grad可以获取某个导数值,也就是梯度
注:一般我们用损失函数进行反向传播,并且w.grad当required_grad=True时需要再加.data获取数据,最好在想获取数据时加一个data,这样的话保险
3、在每次反向传播之前,梯度要置为0是因为这样就没有累加,每次都是当前的梯度,没有加上之前的梯度,我们反向传播更新w与b减去的梯度就要是当前的梯度
4、tensor.numpy()在required_grad=True时不能直接转换,需要用tensor.detach().numpy()
detach()可以理解成将数据抽离出来,numpy()表示转化为numpy数组
代码有不懂的可以点该链接看讲解:
https://www.bilibili.com/video/BV1fA411e7ad?p=13
# pytorch实现一个简单线性回归
import torch
import matplotlib.pyplot as plt
learning_rate = 0.01
# 1、准备数据
x = torch.rand([500, 1])
y_true = x * 3 + 1.0 # 线性回归函数,后面需要拟合与该函数十分相近的w,b
# 2、计算预测值
w = torch.rand([1, 1], requires_grad=True) # 随机初始一个w,然后后面让这个w逼近真实的函数
b = torch.tensor(0, requires_grad=True, dtype = torch.float32) # 0阶张量b,即常量b
# 3、循环(进行训练迭代),并梯度下降,反向传播更新参数
for i in range(2000):
# 计算loss
y_predict = torch.matmul(x, w) + b # 矩阵乘法
loss = (y_true - y_predict).pow(2).mean() # 均方误差
if w.grad is not None:
w.grad.data.zero_() # 反向传播前需将梯度置0
if b.grad is not None:
b.grad.data.zero_()
loss.backward()
w.data = w.data - learning_rate * w.grad # 张量计算要获取data,数值计算
b.data = b.data - learning_rate * b.grad
# 打印显示
if i % 50 == 0:
print("Epochs=", i, ",w = ", w.item(), ",b = ", b.item(), ",loss = ", loss.item()) # item表示取张量中的唯一值
# 作图
plt.figure(figsize=(20, 8)) # 新建画布
plt.scatter(x.numpy().reshape(-1), y_true.numpy().reshape(-1)) # 真实数据得出的散点(蓝色曲线)
y_predict = torch.matmul(x, w) + b # 获取最后预测张量
plt.plot(x.numpy().reshape(-1), y_predict.detach().numpy().reshape(-1), color='red') # 拟合出的曲线(红色)
plt.show()
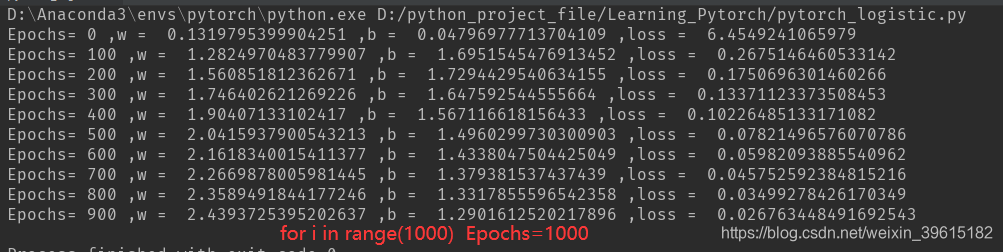
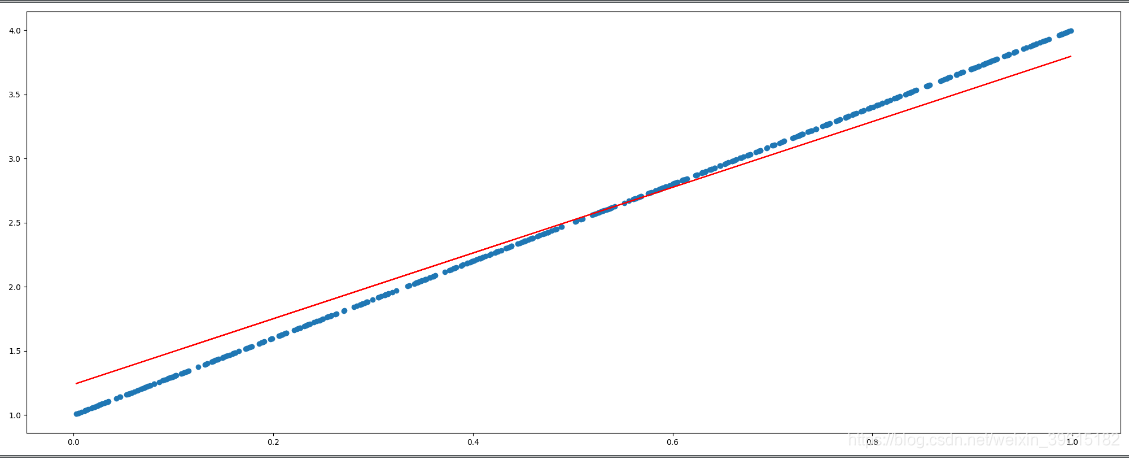
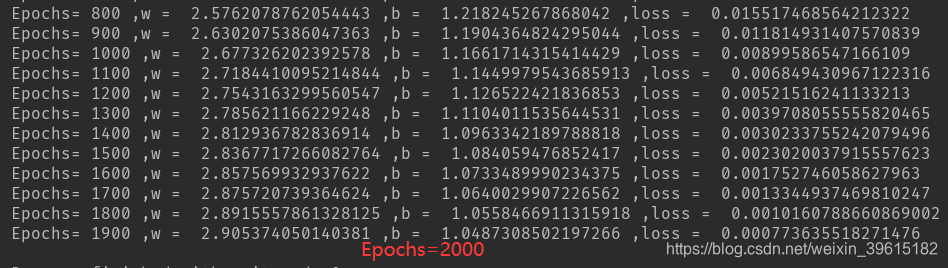
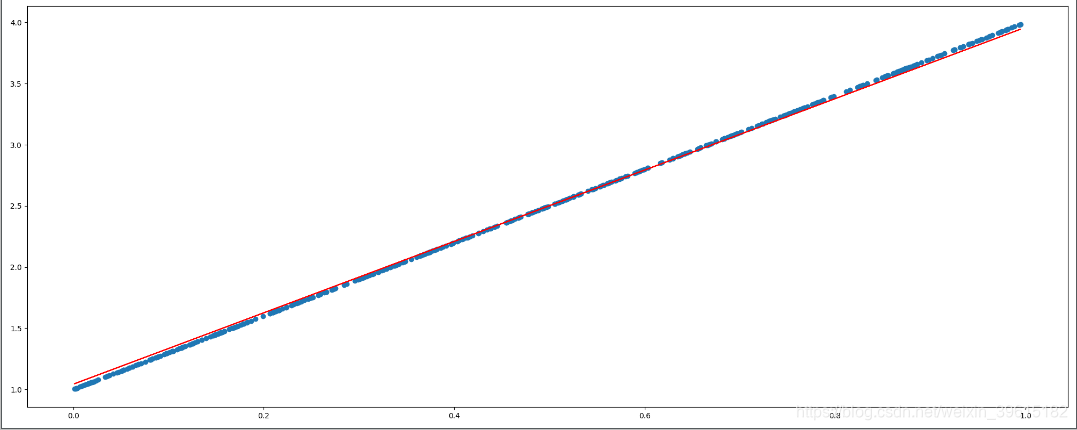
可以看到迭代次数(循环次数)越高,拟合最后的w,b越准确,从而拟合出的直线更接近原y=3x+1曲线,红色为预测的曲线,2000次时,就基本一致了。