线性回归
线性回归模型为:
X为输入样本的特征值, 为预测输出,W为权重参数,B为偏置参数,各参数均可以是矩阵形式,即多维特征,其中W、B一般统称作超参数 。
模型的评估函数使用均方误差,即损失函数使用:
其中Y为输入样本的真实值。
模型通过梯度下降法来实现对数据的学习:
模型的学习过程实际上就是给定一组初始超参数 ,然后通过不断的迭代计算,得到一组最优超参数 使得 最小。
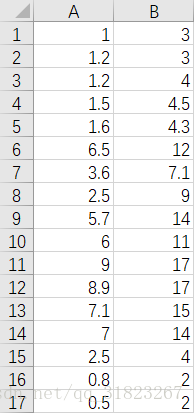
随便捏造一组近似线性的一维数据,以CSV格式保存:
Python实现
导入库
import numpy as np
import matplotlib.pyplot as plt载入数据
X、Y均为一维数据。
#载入CSV数据
def LoadData(csv_path):
data=np.loadtxt(csv_path,delimiter=',')
X=data[:,0]
Y=data[:,1]
return X,Y参数初始化
#初始化参数,dim为输入维度
def InitializeParameters(dim):
para={
'w':np.random.randn(dim,1)*0.01,
'b':np.random.randn(dim,1)*0.01
}
return para
#test
# parameters=InitializeParameters(1)
# print(parameters)梯度下降法
def GradientDescent(para,X,Y,num_iter,learning_rate):
assert(len(X)==len(Y))
m=len(X)
w=para['w']
b=para['b']
for i in range(num_iter):
dw=(2/m)*X*(w*X+b-Y)
dw=np.sum(dw,axis=1)
db=(2/m)*(w*X+b-Y)
db=np.sum(db,axis=1)
w=w-learning_rate*dw
b=b-learning_rate*db
# if i%100==0:
# print(w,b)
para={
'w':w,
'b':b
}
return para线性模型整合
def LinearRegression(X,Y,num_iter,learning_rate=0.001):
#初始化参数
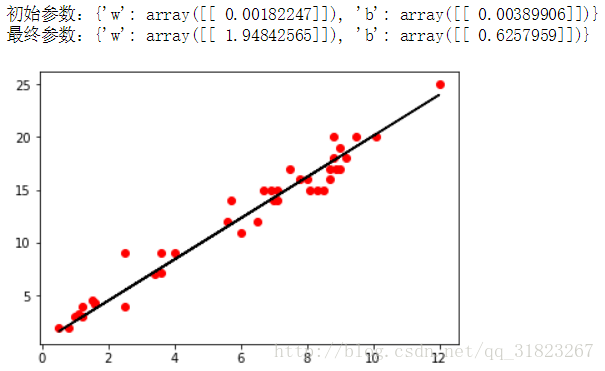
parameters=InitializeParameters(1)
print("初始参数:{}".format(parameters))
#梯度下降法优化参数
parameters=GradientDescent(parameters,X,Y,num_iter,learning_rate)
print("最终参数:{}".format(parameters))
w=parameters['w'][0]
b=parameters['b'][0]
Y_pred=w*X+b
return Y_pred运行
X,Y=LoadData("data.csv")
Y_pred=LinearRegression(X,Y,1000)
plt.plot(X,Y,'ro')
plt.plot(X,Y_pred,'k-')
plt.show()