Photo Enhancer Using Generative Adversarial Networks
最近看了几篇用 GAN 做 photo enhancer 的论文,在这儿总结一下。
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
主要贡献:
这篇文章是在CVPR 2018上看见的。主要贡献如下:
- WESPE: 提供了一种从原图像到DSLR图像的一种通用的方法;
- 提出了一种 CNN-GAN 过渡的结构,结合了最先进的损失和施加在输入图片上的内容损失,使之适合做图像增强和图像风格转换;
方法:
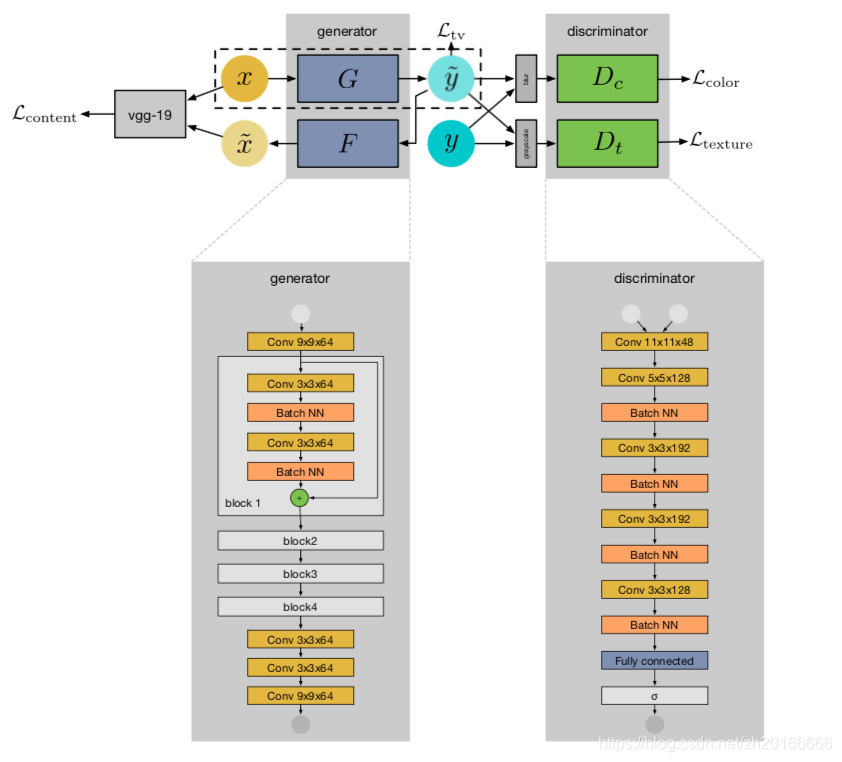
网络结构:
- 两个生成器: 和 ,这两个生成器是为了测量输入图像 和生成图像 之间内容的一致性。有一个基于 VGG-19 提取特征的输入图像 和重建图像 之间的内容损失。
- 两个判别器:
和
分别用来判别生成图像的颜色(color)和纹理(texcture)
损失函数:
- Content consistency loss:
公式中 表示 VGG-19 网络中第 层卷积层的 feature map, , , 分别表示feature map的channel数,高度和宽度。 - Adversarial color loss:
表示生成图像经过了高斯模糊的处理。 - Adversarial texture loss:
表示生成图像经过了灰度化处理。 - TV (total variation) loss:
总的损失函数如下:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
虽然这篇文章主要目的不是photo enhancer,但是网络结构却是很相似的。
主要贡献:
- 提出了使用 Cycle-consistency loss 来实现弱监督的学习
网络结构:
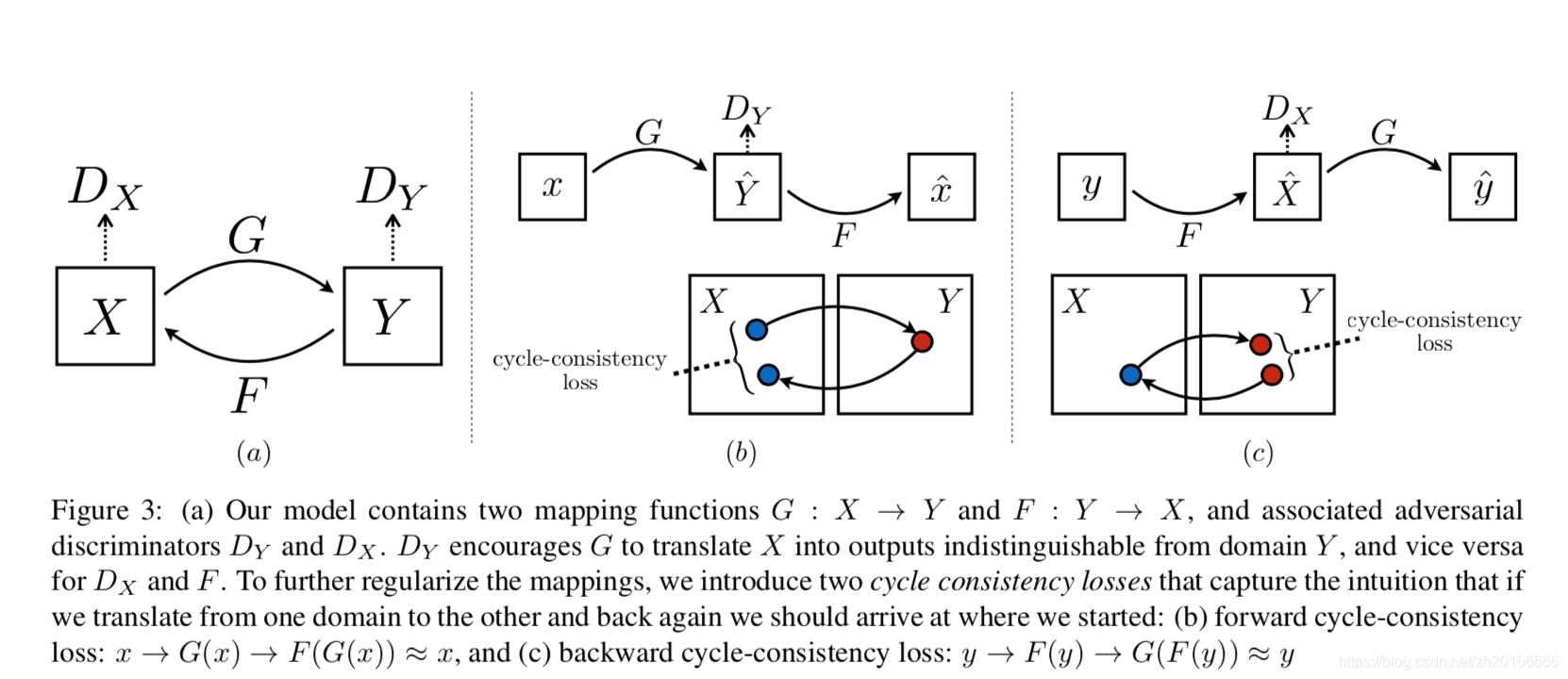
CycleGAN有两个映射函数:
,
. 而且每个生成器都有一个对应的判别器
,
. 除了来自判别器的损失,CycleGAN还有一个cycle-consistency loss: forward cycle-consistency loss:
, backward cycle-consistency loss:
.
Cycle Consistency Loss
所以总的目标函数就是:
至于为什么要使用cycle consistency loss,论文中有这样两个地方提到不使用cycle consistency loss会出现的一些问题:
However, such a translation does not guarantee that an individual input x and output y are paired up in a meaningful way – there are infinitely many mappings G that will induce the same distribution over y. Moreover, in practice, we have found it difficult to optimize the adversarial objective in isolation: standard procedures often lead to the well known problem of mode collapse, where all input images map to the same output image and the optimization fails to make progress.
However, with large enough capacity, a network can map the same set of input images to any random permutation of images in the target domain, where any of the learned mappings can induce an output distribution that matches the target distribution.
总结来说就是如果不使用 cycle consistency loss 不能保证生成的图片和原来的图片在内容上是有关联的,甚至可能会出现生成的图片和原来的图片完全没有关系的现象,而且在实验的时候还会出现 model collapse 的问题。
Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs
主要贡献:
- 全局特征 (global feature)与 U-Net 结合的生成器结构;
- 自适应的GP (gradient penalty);
- 对同类型的生成器使用独自的BN (individual batch normalization);
网络结构:
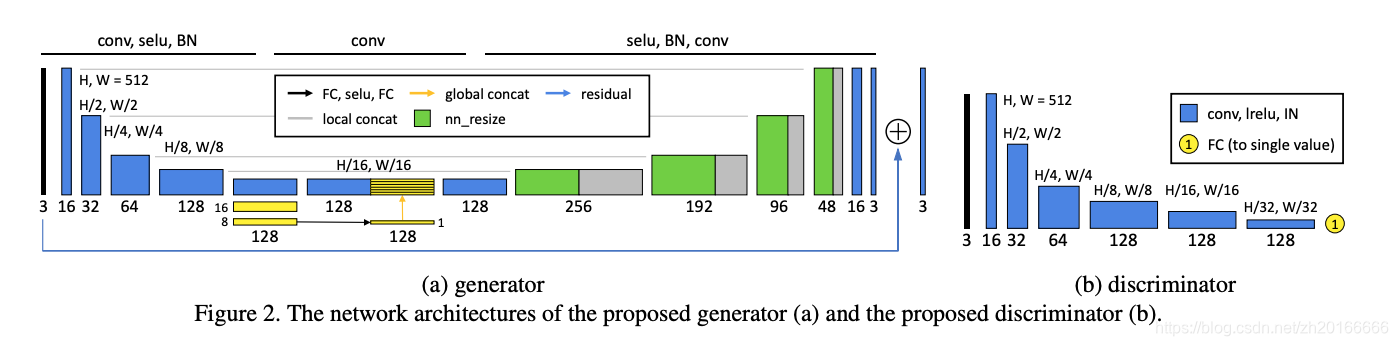
从生成器的结构可以看出生成器使用了U-Net的结构,而且只学习残差。
Global feature
图中黄色部分使用了global feature,将encoder得到的feature map提取出11128的global feature,然后拷贝32*32份拼接到原来的feature map后面进行decode.
Individual batch normalization
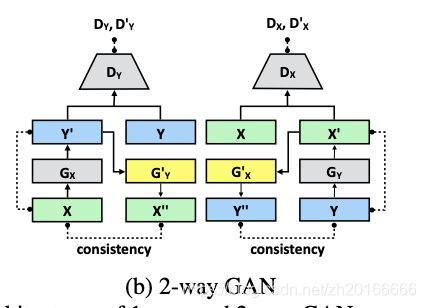
一般的2-way GAN中
和
,
和
是同一个生成器。在这篇文章中作者认为这两组生成器的数据来源不一样(一个来自真是图片,一个是生成的图片),因此不应该使用同一个网络,所以作者就提出了一种individual batch normalization,即
和
所有层都共享参数,除了BN层(对
和
一样)。
Adaptive weighting scheme
作者认为WGAN-GP过分依赖于权重惩罚项的权重 ,如果 太小就不能保证Lipschitz约束;如果 太大可能会使收敛变得很慢。所以作者提出了一种自适应的GP。首先作者将权重惩罚项由 改成 。作者想让这个梯度维持在一个范围,比如[1.001, 1.05]. 做法是如果梯度的移动平均大于上界,意味着当前的 太小,因此将 加倍。另一方面,如果梯度的移动平均小于下界,意味着 太大,则将 减半。
