经典的有关本方向的GAN网络文章
引入CGAN去执行一个附加的约束,derain图像必须更加接近ground-truth
提出了GAN的对抗LOSS和新型的LOSS函数
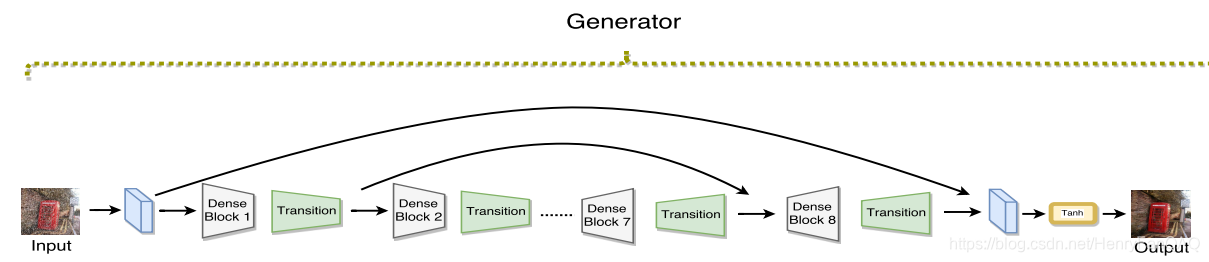
生成器子网络利用密集连接网络(dense network)
鉴别器是利用全局和局部信息来判断图像的真伪。
contribution
- 不需要post-processing的一个传统的条件GAN;
- 专门为单幅图像去雨设计的密集连接生成器;
- 多尺度鉴别器; leverage both local and global information;
We aim to directly learn a mapping from an input rainy image to
a de-rained (background) image by constructing a conditional
GAN-based deep network called ID-CGAN.
生成器应该在不丢失背景细节的情况下尽可能的删除rain streak
由于现有的方法都是对称的结构(adopted a symmetric (encoding-decoding) structure)所以该作者也在生成器中使用对称结构。用密集块去代替现存GAN生成器中使用的U-net和残差块。密集块能够产生strong梯度流和result in improved parameter efficiency。
第j个稠dense block Dj:
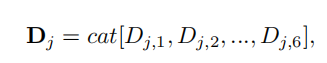
每一个密集块后跟着一个过渡块T: Tu上采样;Td下采样;
Tn不进行采样;
生成器网络如下
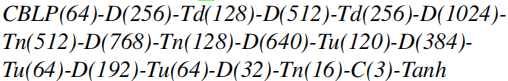
其中CBLP 为 卷积层-batch normalization-leak Relu-池化层

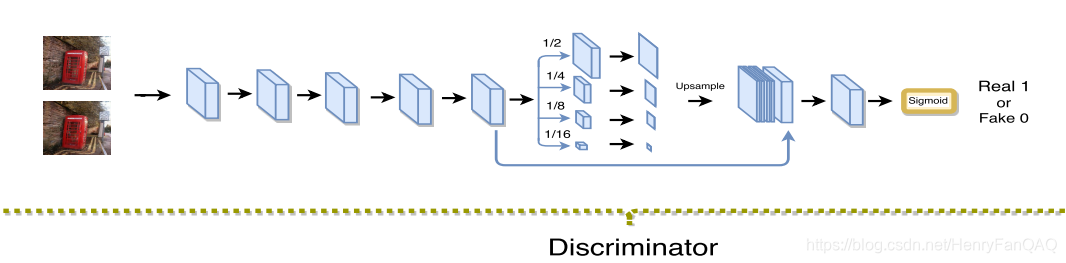
PatchGAN由朱俊彦的一文中提出使用[https://openaccess.thecvf.com/content_cvpr_2017/papers/Isola_Image-To-Image_Translation_With_CVPR_2017_paper.pdf]
也是比较经典的Pix2PixGAN
之前的GAN鉴别器,是输入图片,输出一个神经元,判别图片是真还是假,我们可以称为Image GAN
如果鉴别器输入图片,输出的是w×H×1,针对每个像素的真假进行了预测,我们称为Pixel GAN
patchGAN是在两者之间,输出一个30×30×1,每个神经元对应的感受野大小是70×70,我们称为Patch GAN(70x70)。文章中默认经过三次卷积网络得到输出。文章中说测试了70在他的实验中表现的好,性能超过Image GAN和Pixel GAN
注意,文章中鉴别器默认使用了三次卷积网络,同时他是一个域转换的条件GAN,需要同时feed进去input和output的图片,也就是concate到一起输入D.

作者解释了为什么用于图像去雨这种像素级别任务的GAN
是不稳定而且通过条件引导的生成器容易产生噪声和incomprehensible 的结果。
这是由于新的输入may 不服从训练样本的distribution
如何解决? 网络中引入新的感知损失 perceptual loss
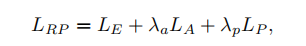
LA代表对抗损失;LP代表感知损失;LE代表每像素的损失(欧几里得损失)λa λp如果都为0,则网络变成一个简单的CNN,主要目的就是最小化groundturth与derain result的欧几里得损失;如果λp为0 则网络变为一个简单的GAN;如果λa为0,则变成论文 “Perceptual losses for real-time style transfer and super-resolution”中的损失函数
λa = 6.6 × 10^-3
and λp = 1