摘要
本文介绍了一种能够生成高质量自然图像样本的生成参数模型。作者的方法在拉普拉斯金字塔框架内使用级联卷积网络,以粗略到精细的方式生成图像。在金字塔的每个层,使用生成对抗网络(GAN)[11]的方法训练单独的生成性连接模型。从该模型中抽取的样本质量明显高于其他方法。在人类评估员的主观评估中,CIFAR10样本有大约40%被评估员认为是真实图像,而从GAN的baseline模型中抽取的样本则只有10%。作者还展示了在LSUN场景数据集的高分辨率图像上训练的模型的样本。
1 引言
建立良好的自然图像生成模型一直是计算机视觉中的一个基础的问题。然而,由于图像的结构复杂且尺寸很大,对图像建立良好的模型是很困难的。考虑到以高分辨率对整个场景进行建模的困难,大多数现有方法是生成图像块。相比之下,作者提出了一种方法,能够在 和 的尺度下,生成看似合理的图像。为此,作者利用自然图像的多尺度结构,构建一系列生成模型,每个模型都利用拉普拉斯金字塔[1]捕获不同尺度的图像结构。该策略将原始问题分解为一系列更易于解决的子问题。在每个尺度上,作者使用Goodfellow等人的Generative Adversarial Networks(GAN)[11]方法训练基于卷积网络的生成模型。生成的样本以从粗到细的方式被绘制,从低频残留图像开始。第二级金字塔采用带通结构,以采样残差为条件。后续级的金字塔继续此过程,始终调整先前比例的输出,直到达到最后一层金字塔。因此,绘制样本是一种有效且简单的过程:将随机向量作为输入并通过级联的深度卷积网络(convnets)向前运行以产生生成图像。
事实证明,深度学习方法在视觉中的判别任务中非常有效,例如目标分类[4]。然而,尽管做了很多努力[14,26,30],生成任务还没有取得同样的成功。在这种背景下,作者提出的方法取得了重大进展,因为它可以直接进行训练和采样,结果样本显示出令人惊讶的视觉保真度。
1.1 相关工作
图像生成模型的研究很多,主要分为两种方法:非参数方法和参数方法。前人从训练图像中复制图像块以执行例如纹理合成[7],或超分辨率[9]。更雄心勃勃的是,如果给定足够大的训练数据量,图像的整个部分可以进行绘制[13]。 早期的参数方法解决了例如纹理合成[3,33,22]之类的简单问题(Portilla和Simoncelli[22]利用可操纵的金字塔小波表示[27],类似于这里对拉普拉斯金字塔的使用)。对于图像处理任务,基于图像梯度的边缘分布模型是有
效的[20,25],但这仅用于图像恢复而不是真正的概率密度模型(因此不能对实际图像样本进行生成)。也可以使用非常大的高斯混合模型[34]和图像块的稀疏编码模型[31],但是这些工作都面临着同样的问题。
很多深度学习方法涉及生成参数模型。受限Boltzmann机[14,18,21,23],深度Boltzmann机[26,8],去噪自动编码器[30]都有一个生成解码器,可以从潜在表示中重建图像。变分自动编码器[16,24]提供了便于采样的概率解释。 然而,对于所有这些方法,令人信服的实验仅在诸如MNIST和NORB的简单数据集上被展示过,可能是由于训练复杂性限制了它们对更大和更逼真的图像的适用性。
最近几篇论文提出了新的生成模型。Dosovitskiy等[6]展示了一个卷积网络如何能够绘制出具有不同形状和视角下的椅子。作者的模型也使用了convnet,它能够对一般场景和对象进行采样。Gregor等人的DRAW模型[12]使用具有RNN的注意机制通过图像块的轨迹生成图像,并给予MNIST和CIFAR10图像样本进行了样本生成。Sohl-Dickstein等[28]使
用基于扩散的过程进行深度无监督学习,得到的模型能够生成合理的CIFAR10样本。Theis和Bethge[29]采用LSTM来捕捉空间依赖性并展示令人信服的自然纹理修复效果。
作者的工作建立在Goodfellow等的GAN[11]的基础之上。原始的GAN适用于较小的图像(例如MNIST)但不能处理大图像。与作者的方法最相关的是Mirza和Osindero[19]以及Gauthier[10]的初步工作,他们都提出了GAN模型的有条件版本。前者基于MNIST样本,而后者仅关注正面的人脸图像。作者的方法也使用了几种形式的条件GAN模型,但其应用范围更加激进。
2 方法
作者方法的基本构建是Goodfellow等人的生成对抗网络(GAN)[11]。在回顾了这一点之后,作者介绍了自己的LAPGAN模型,该模型将条件形式的GAN模型集成到拉普拉斯金字塔的框架中。
GAN方法[11]是一个训练生成模型的框架,本节在图像数据的背景下进行了简要解释。 该方法使两个网络彼此对抗:捕获数据分布的生成模型
,和区分
绘制的样本与训练数据的图像的辨别模型
。在本文的方法中,
和
都是卷积网络。前者以从噪声分布
中提取的噪声矢量
作为输入,并输出图像
。辨别网络
将
(
生成的图像)或者
(来自训练数据分布
的图像)作为随机选择(具有相等概率)的输入,
的输出是标量概率,如果输入为真实样本,则概率较高,如果从G生成,则概率较低。最后使用minimax目标将两个模型训练在一起:
这鼓励
拟合
以便用其生成的样本"欺骗"
。在以上的式子中,
和
都是通过反向传播方程中的损失来训练的两个模型来更新参数。
条件生成对抗网络(CGAN)是GAN的扩展,其中网络
和
都接收
作为输入的附加信息向量。这可能包含有关训练样本
的类别的信息。 因此损失函数变为
其中
是类别的先验分布。该模型允许生成模型的输出由调节变量
控制。Mirza和Osindero [19]以及Gauthier [10]都使用
作为类指示器,通过在MNIST和人脸数据集上的实验来探索这个模型。在本文的方法中,
是从另一个CGAN模型生成的图像。
2.2 拉普拉斯金字塔
拉普拉斯金字塔[1]是线性可逆图像表示,由一组带通图像组成,在空间上相隔八个像素,另加上低频残差。 形式上,令 是下采样操作,它可以模糊和抽取一个 图像 ,生成一个 的新图像 。另外,令 是一个上采样运算符,它图像 将平滑和扩展为两倍大小,因此 是一个大小为2j 2j的新图像。 要建立一个拉普拉斯金字塔,首先建立一个高斯金字塔 ,其中 , 是重复应用 到图像 上的运算结果。例如, 。k是所选择的的金字塔的级别数,在本文中,金字塔的最后一层具有非常小的空间范围( 像素)。
拉普拉斯金字塔
的每个级别
处的参数
通过取高斯金字塔中的相邻级别之间的差异来构造,用
对较小的级别进行上采样,使得它们在大小是兼容的:
直观地说,每个级别捕获以特定比例呈现的图像结构。最后的拉普拉斯金字塔
不是差异图像,而是等于最终高斯金字塔层级之间的低频残差,即
。从拉普拉斯金字塔系数
重建图像的方式是由后向前的进行如下迭代:
以
开始,重建图像为
。换言之,从最粗糙的级别开始进行重复上采样,并将差异图像
添加到下一个更精细的级别,直到能够重建全分辨率的原始图像。
2.3 拉普拉斯生成对抗网络(LAPGAN)
作者提出的方法将条件GAN模型与拉普拉斯金字塔表示相结合。这个模型可以通过首先考虑采样程序的方式被最好地解释。经过训练,可以得到一套生成性的卷积网络模型
,每个模型捕获拉普拉斯金字塔的不同级别的自然图像系数
的分布。对图像进行采样的过程类似于 公式(4) 中的重建过程,只不过生成模型被用于生成
:
该递归过程中,初始化
并使用最后一层的
去生成一个残差图
,其中
是噪声矢量。要注意的是,最后一层之外的所有级别的模型都是条件生成模型,除了噪声向量
之外还采用当前图像
的上采样版本作为条件变量。 图1 展示了
的金字塔使用4个生成模型对
图像进行采样的过程。
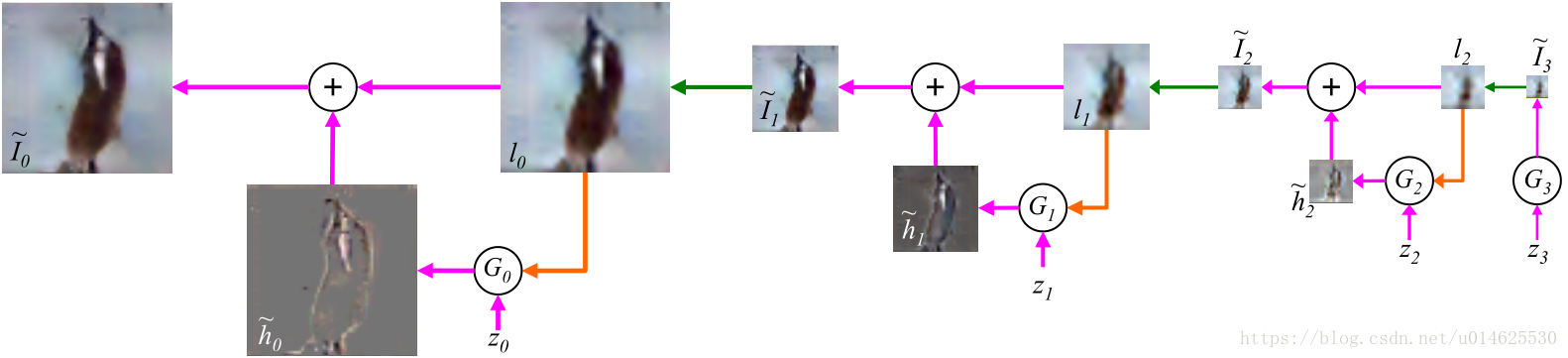
图1: LAPGAN生成样本的过程。从噪声样本
(最右侧)开始,并使用生成模型
生成
。
被上采样(绿色箭头),然后用作下一级生成模型
的条件变量(橙色箭头)
。
与另一个噪声样本
一起用于生成差分图像
,然后被加到
上以创建
。 之后两步重复这个过程,以产生最终的全分辨率生成图像
。
生成模型
在金字塔的每个级别都使用CGAN的方法进行训练。具体而言,从每个训练图像
构建拉普拉斯金字塔。在金字塔的每一级,做出随机选择(具有相等的概率):要么使用来自 公式3 的标准过程来构造系数
,或者使用
生成它们:
要注意的是,
是使用粗尺度图像
以及噪声向量
作为输入的卷积网络。
将
或
与低通图像
(在第一卷积层之前添加到
或
)一起作为输入,并预测图像是真实样本还是生成样本。在金字塔的最后一层,低频残差足够小,可以用标准GAN直接建模:
。此时
也只有
或
作为输入。该网络的框架如 图2 所示。
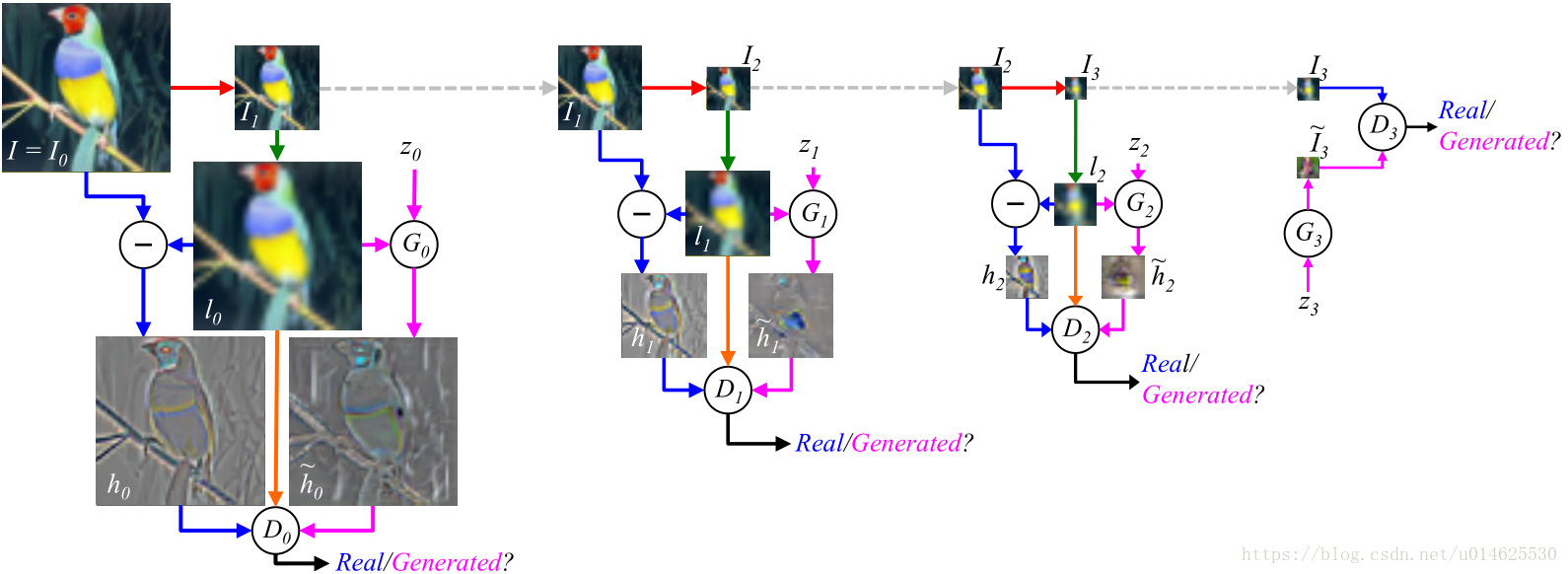
图2: LAPGAN模型的训练过程。训练步骤从训练集(左上角)中的
输入图像
开始:
(i)令
,并将其下采样模糊两倍(红色箭头)以产生
;
(ii)将
上采样两倍(绿色箭头),得到
的低通版本
;
(iii)以相同的概率使用
来为判别模型
创建一个真实的样本或生成的样本。
以真实样本为例(蓝色箭头),令高通信号
输入到判别器
,并计算它是真实样本/生成样本的概率。在生成样本的情况(品红色箭头)中,生成网络
接收随机噪声矢量
和低通信号
作为输入。它输出生成的高通图像
到
。 在实际样本/生成样本两种情况下,
也接收
(橙色箭头),并按照 公式2 的方式优化。
学习生成与低通图像
一致的真实高频结构
。在金字塔的后面两级,对
和
重复这个过程。值得注意的是,金字塔上每个级别的模型都是独立训练的。 在第3级,
是
图像,简单到足以直接用标准GAN的
和
建模。
将生成的结果不断改进是这项工作的关键思想。本文放弃了任何全局保真度的概念,从未尝试通过训练网络来区分级联和真实图像的输出,而是专注于使每一步都合理。此外,独立训练每层金字塔具有以下优点:模型难以记住训练示例(这是当使用高容量深度网络时存在的一个缺点)。
如上所述,本文的模型以无监督的方式进行训练。但是,作者之后还会探索利用类标签的变体。这项工作是通过添加one-hot 向量 作为 和 作为用于表示类别的条件变量来完成的。
3 模型架构与训练
作者将LAPGAN应用于三个数据集:
(i) CIFAR10 [17] ——10个不同类别的
彩色图像,100k个训练样本;
(ii) STL10 [2]——10个不同类别的
彩色图像,100k个训练样本(使用未标记的数据);
(iii) LSUN [32]——10种不同自然场景类型的10M张图像,下采样到64×64像素。
对于每个数据集,作者探索了
的各种架构。使用视觉检查和基于像素空间中的
误差的启发式的组合来对模型进行选择。启发式方法计算了金字塔中
级给定验证图像的误差为
其中
是从噪声分布
中提取的噪声向量集合。换句话说,启发式问题就是,“有没有生成的残差图像接近ground truth?”。Torch下的训练和评估代码可以从这个链接中找到:http://soumith.ch/eyescream/。对于所有模型,噪声向量
是从均匀的
分布中提取的。
3.1 CIFAR10和STL10
初始尺度: 以8×8分辨率运行,将密集连接的网络用于 和 ,具有2个隐藏层并使用ReLU非线性激活函数。 使用Dropout,并且每层有600个单元。 每层有1200个单元。 是100维度的向量。
后续层的尺度: 对于CIFAR10,作者通过从原始图像中采集四个 的切片来增加训练集的体量。因此金字塔的两个后续级别是8→14和14→28。对于STL,金字塔中有4个级别:8→16→32→64→96。对于这两个数据集, 和 分别是3层和2层的卷积网络(见[5])。被输入至 的噪声 被表示为低通 的第4个“颜色平面“,因此其维度随金字塔等级而变化。对于CIFAR10,作者还探索了模型的条件类别版本,用向量 对标签进行编码。通过将其输出重新在单个线性层上重构,将其集成到 和 中的平面特征图,然后与第一层的特征图连接。损失以 公式2 的方式被定义,并使用SGD训练,初始学习率被设定为为0.02,在每个训练周期的减少因子为 。 Momentum的设定从0.5开始,在每个训练周期增加0.0008,最大值为0.8。 训练时间取决于模型的大小和金字塔等级,在作者的计算机上,较小的模型需要数小时的训练,较大的模型需要一天的时间。
3.2 LSUN
该数据集有较大的体量,这允许作者为每个场景类训练单独的LAPGAN模型。随后的金字塔各级的尺度为4→8→16→32→64。在金字塔的每个级别使用
和
的通用架构。
是一个5层的网络,具有尺寸为
的特征图和一个线性输出层。每个隐藏层使用
的滤波器,ReLU,批量标准化[15],和
Dropout。
有3个隐藏层,特征图尺寸为
,加上Sigmoid输出。详细信息,请参见[5]。值得注意的是,由于这个数据集的体量比较大,
和
的特征图尺寸明显大于用于CIFAR10和STL的尺寸。
4 实验
作者使用3种不同的手段评估文中的方法:
(i)在图像数据集上计算对数似然;
(ii)从模型中抽取样本图像
(iii)比较(a)生成的样本,(b)baseline方法,和(c)真实的图像。
4.1 对数似然的评估
跟Goodfellow等类似[11],作者不得不使用Gaussian Parzen窗口估计器来计算对数似然,因为没有使用直接计算它的方法。 表1 在50k个样本上比较了LAPGAN模型和标准GAN的对数似然概率(高斯宽度σ也在验证集上调整)。本文的方法的效果比GAN略微增加。LAPGAN模型的多尺度结构可以改进基础估算技术。这种新方法计算拉普拉斯金字塔每个尺度的概率,并将它们组合起来以得出整体图像的概率(详见附录A,附录未翻译)。多尺度Parzen窗估计方法比传统估算器有很大的改进,如 表1 所示。
表1: 标准GAN和提出的LAPGAN模型在CI-FAR10和STL10数据集上的对数似然估计。表中给出了平均值和标准差。第1行和第2行在全分辨率下使用Parzen窗口估计,而第3行使用的是多尺度Parzen窗口估计。

在被应用到CIFAR-10训练集时,与简单的高斯相比,两种估计器的缺点很明显。即使增加了噪声,最终的高斯模型也可以获得比GAN或LAPGAN模型或其他已发布模型高得多的对数似然。更一般地,由于对所使用的精确表示的敏感性,对数似然作为性能度量是有问题的。图像的缩放,噪声和分辨率的微小变化(从RGB到YUV的微小变化,或输入表示中的微小变化)导致得分差异很大,使得与其他方法的公平比较变得困难。
4.2 模型生成的样本
本节展示了在CIFAR10,STL10和LSUN数据集上训练的模型的生成样本。其他样品可以在补充材料中找到[5]。 图3 显示了在CIFAR10上训练的模型的样本。来自有条件LAPGAN类的样本被按类别组织。作者对标准GAN模型[11]的重新实现产生的图像比原始文件中显示的图像略微清晰。作者将此改进归因于数据增强的引入。LAPGAN的样本改进了标准GAN的样本:它们看起来更像物体,边缘更明确。基于类别的条件方法可以改进生成模型,这通过条件LAPGAN样本中的清晰对象结构被证明。这些生成样本的质量优于Gregor等人的DRAW模型[12]还有Sohl-Dickstein等人的模型[28]。每个图像的最右列显示相邻样本的最近训练示例(在 像素空间中)。这表明本文的模型不是简单的复制输入的训练样本。
图4(a) 显示了作者在STL10上训练的LAPGAN模型的样本。在这里,物体失去了清晰的形状,但生成的样本仍然清晰。 图4(b) 显示了随机STL10样本的生成过程。
图5 显示了在三种LSUN类别(塔楼,卧室,教堂前方)训练的LAPGAN模型的样本。据作者所知,没有其他生成模型能够生成这种复杂性的样本。与CIFAR10和STL10样品相比质量的显着提高可能是由于更大的训练LSUN训练集使作者能够训练更大更深的模型。在补充材料中,作者展示了探测模型的其他实验,例如使用相同的固定
图像绘制多个样本,这是一种LAPGAN模型的变种。
图3: CIFAR10样本:类条件CC-LAPGAN模型,LAPGAN模型,和Goodfellow的标准GAN模型[11]的效果。黄色列显示相邻列中样本的最近邻的训练数据。
图4: STL10的生成样本:(a)来自LAPGAN模型的随机96x96样本。 (b)从粗到细的生成过程。
图5: 来自三个不同LSUN LAPGAN模型的
样本(上面是塔,中间是卧室,下面是教堂主视图)。



4.3 人类对样本的评价
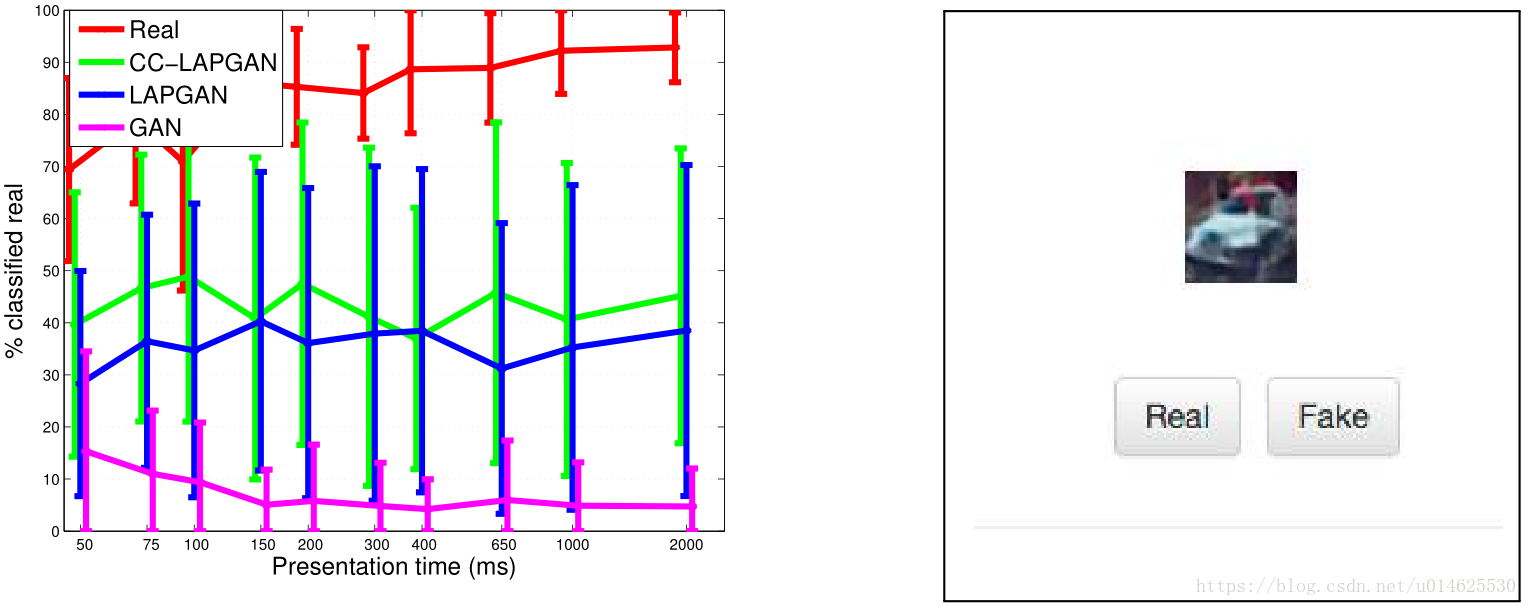
为了获得样品质量的定量测量,作者邀请了15名志愿者参与实验,看看他们是否可以将样本与真实图像区分开来。 向受试者呈现 图6(右) 所示的用户界面,并随机显示四种不同类型的图像:从在CIFAR10上训练的三种不同GAN模型中抽取的样本((i)LAPGAN,(ii)类条件LAPGAN和( iii)标准GAN [11])以及真实的CIFAR10图像。在呈现图像之后,志愿者点击适当的按钮以指示他们是否认为图像是真实的或生成的。由于精度是观看时间的函数,作者从15ms到2000ms之间的11个持续时间之一中随机选择呈现时间,之后显示灰色掩模图像。在实验开始之前,展示给志愿者来自CIFAR10的真实图像的例子。在从志愿者收集样本之后,作者在 图6 中绘制了四个不同数据源被认为是真实的图像的分数,是呈现时间的函数。曲线显示LPGAN模型产生的样本比标准GAN [11]更真实。
图6: 左:志愿者对真实CIFAR10图像(红色)和来自Goodfellow等的图像[11](洋红色),作者的LAPGAN(蓝色)和类条件LAPGAN(绿色)的的评估。误差条表示受试者间的不同,量化为
。类条件LAPGAN模型生成的样本中大约有40%是真实的,足以令人们认为它们是真实的图像。这与来自标准GAN模型[11]的10%的图像相比很好,但仍然比实际图像的>90%的比例低很多。 右:用户界面。
5 讨论
通过修改[11]中的方法以更好地表示图像结构,作者提出了一种概念上简单的生成模型,能够生成高质量的样本图像,其质量优于其他深度生成建模方法。虽然它们表现出合理的多样性,但本文中无法确定它们是否涵盖了完整的数据分布。因此,本文的模型可能会在自然图像上为流形的某些部分分配低概率。量化这一点很困难,但可能通过人类主观的实验来完成。本工作的一个关键点是放弃任何“全局”保真度的概念,而是将其打破成合理的连续改进。注意到许多其他信号模型具有多尺度结构,可以从类似的方法中受益。
致谢
感谢匿名审稿人的深刻见解和建设性意见。 还要感谢Andrew Tulloch,Wojciech Zaremba和FAIR基础设施团队的有益讨论和支持。Emily Denton得到了NSERC奖学金的支持。
参考文献
[1] P. J. Burt, Edward, and E. H. Adelson. The laplacian pyramid as a compact image code. IEEE Transactions on Communications, 31:532–540, 1983.
[2] A. Coates, H. Lee, and A. Y. Ng. An analysis of single layer networks in unsupervised feature learning. In AISTATS, 2011.
[3] J. S. De Bonet. Multiresolution sampling procedure for analysis and synthesis of texture images. In Proceedings of the 24th annual conference on Computer graphics and interactive techniques, pages 361–368. ACM Press/Addison-Wesley Publishing Co., 1997.
[4] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255. IEEE, 2009.
[5] E. Denton, S. Chintala, A. Szlam, and R. Fergus. Deep generative image models using a laplacian pyramid of adversarial networks: Supplementary material. http://soumith.ch/eyescream.
[6] A. Dosovitskiy, J. T. Springenberg, and T. Brox. Learning to generate chairs with convolutional neural networks. arXiv preprint arXiv:1411.5928, 2014.
[7] A. A. Efros and T. K. Leung. Texture synthesis by non-parametric sampling. In ICCV, volume 2, pages 1033–1038. IEEE, 1999.
[8] S. A. Eslami, N. Heess, C. K. Williams, and J. Winn. The shape boltzmann machine: a strong model of object shape. International Journal of Computer Vision, 107(2):155–176, 2014.
[9] W. T. Freeman, T. R. Jones, and E. C. Pasztor. Example-based super-resolution. Computer Graphics and Applications, IEEE, 22(2):56–65, 2002.
[10] J. Gauthier. Conditional generative adversarial nets for convolutional face generation. Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter semester 2014 2014.
[11] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, pages 2672–2680. 2014.
[12] K. Gregor, I. Danihelka, A. Graves, and D. Wierstra. DRAW: A recurrent neural network for image generation. CoRR, abs/1502.04623, 2015.
[13] J. Hays and A. A. Efros. Scene completion using millions of photographs. ACM Transactions on Graphics (TOG), 26(3):4, 2007.
[14] G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006.
[15] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167v3, 2015.
[16] D. P. Kingma and M. Welling. Auto-encoding variational bayes. ICLR, 2014.
[17] A. Krizhevsky. Learning multiple layers of features from tiny images. Masters Thesis, Deptartment of Computer Science, University of Toronto, 2009.
[18] A. Krizhevsky, G. E. Hinton, et al. Factored 3-way restricted boltzmann machines for modeling natural images. In AISTATS, pages 621–628, 2010.
[19] M. Mirza and S. Osindero. Conditional generative adversarial nets. CoRR, abs/1411.1784, 2014.
[20] B. A. Olshausen and D. J. Field. Sparse coding with an overcomplete basis set: A strategy employed by v1? Vision research, 37(23):3311–3325, 1997.
[21] S. Osindero and G. E. Hinton. Modeling image patches with a directed hierarchy of markov random fields. In J. Platt, D. Koller, Y. Singer, and S. Roweis, editors, NIPS, pages 1121–1128. 2008.
[22] J. Portilla and E. P. Simoncelli. A parametric texture model based on joint statistics of complex wavelet coefficients. International Journal of Computer Vision, 40(1):49–70, 2000.
[23] M. Ranzato, V. Mnih, J. M. Susskind, and G. E. Hinton. Modeling natural images using gated MRFs. IEEE Transactions on Pattern Analysis & Machine Intelligence, (9):2206–2222, 2013.
[24] D. J. Rezende, S. Mohamed, and D. Wierstra. Stochastic backpropagation and variational inference in deep latent gaussian models. arXiv preprint arXiv:1401.4082, 2014.
[25] S. Roth and M. J. Black. Fields of experts: A framework for learning image priors. In In CVPR, pages 860–867, 2005.
[26] R. Salakhutdinov and G. E. Hinton. Deep boltzmann machines. In AISTATS, pages 448–455, 2009.
[27] E. P. Simoncelli, W. T. Freeman, E. H. Adelson, and D. J. Heeger. Shiftable multiscale transforms. Information Theory, IEEE Transactions on, 38(2):587–607, 1992.
[28] J.Sohl-Dickstein, E.A.Weiss, N.Maheswaranathan, andS.Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585, 2015.
[29] L. Theis and M. Bethge. Generative image modeling using spatial LSTMs. Dec 2015.
[30] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol. Extracting and composing robust features with denoising autoencoders. In ICML, pages 1096–1103, 2008.
[31] J. Wright, Y. Ma, J. Mairal, G. Sapiro, T. S. Huang, and S. Yan. Sparse representation for computer vision and pattern recognition. Proceedings of the IEEE, 98(6):1031–1044, 2010.
[32] Y. Zhang, F. Yu, S. Song, P. Xu, A. Seff, and J. Xiao. Large-scale scene understanding challenge. In CVPR Workshop, 2015.
[33] S. C. Zhu, Y. Wu, and D. Mumford. Filters, random fields and maximum entropy (frame): Towards a unified theory for texture modeling. International Journal of Computer Vision, 27(2):107–126, 1998.
[34] D. Zoran and Y. Weiss. From learning models of natural image patches to whole image restoration. In ICCV, 2011.