SpectFormer: Frequency and Attention is what you need in a Vision Transformer, arXiv2023
论文:https://arxiv.org/abs/2304.06446
代码:https://badripatro.github.io/SpectFormers/
简介
ViT已成功应用于图像识别任务。在文本模型中,既有类似于原始工作的基于多头自我注意的(ViT,DeIT),也有最近基于光谱层的(Fnet,GFNet,AFNO)。受光谱和层次Transformer相关工作的启发,论文观察到光谱和多头注意力层的结合能提供更好的Transformer架构,因此提出SpectFormer,使用傅立叶变换实现的光谱层来捕捉架构初始层中的相关特征。此外,在网络的深层使用多头自我注意。SpectFormer架构简单,它将图像标记转换到傅立叶域,然后使用可学习的权重参数应用门控技术,最后进行傅立叶逆变换以获取信号。SpectFormer结合了光谱注意力和多头注意力。
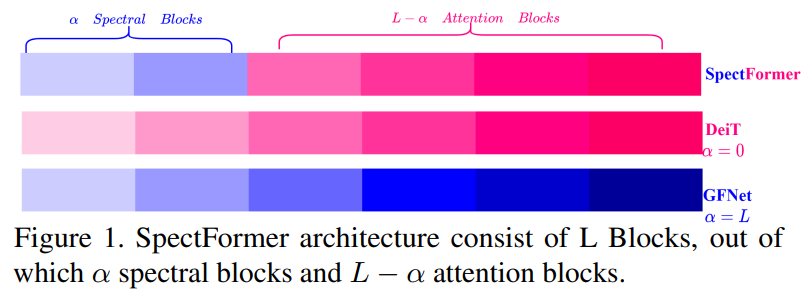
SpectFormer 结构

SpectFormer架构包括贴片嵌入层,后面是位置嵌入层,然后是变换器块,然后是分类头。Transformer块包括一系列光谱层,后面是关注层。图像被分割成一系列补丁,得到使用线性投影层的贴片嵌入。其中,位置嵌入使用标准的位置编码层。
Spectral Block
光谱层的目的是捕捉图像的不同频率分量,以理解局部频率。这可以使用频谱门控网络来实现,该频谱门控网络包括快速傅立叶变换(FFT)层,然后是加权门控,然后是逆FFT层。频谱层使用FFT将物理空间转换为频谱空间。使用可学习的权重参数来确定每个频率分量的权重,以便适当地捕捉图像的线条和边缘。频谱层使用快速傅立叶逆变换(IFFT)将频谱空间带回物理空间。在IFFT之后,频谱层具有用于信道混合的层归一化和多层感知器(MLP)块,而令牌混合使用spectral门控技术来完成。
Attention Block
SpectFormer的注意力层是一个标准的注意力层,包括层规范化,然后是多头自注意(MHSA),然后是层规范化和MLP。MHSA架构与DeIT注意力架构的相似之处在于,MHSA用于注意力层中的令牌混合,MLP用于信道混合。
SpectFormer Block

SpectFormer块如图1所示,处于分阶段体系结构中。在SpectFormer块中引入了一个因子,它控制光谱层和注意力层的数量。如果α=0,SpectFormer包括所有注意力层,类似于DeIT-s,而当α值为12时,SpectFormer变得类似于GFNet,具有所有光谱层。必须注意的是,所有注意力层都具有无法准确捕捉局部特征的缺点。类似地,所有光谱层都具有全局图像属性或语义特征无法准确处理的缺点。SpectFormer提供了改变光谱和注意力层数量的灵活性,这有助于准确捕捉全局属性和局部特征。SpectFormer考虑了局部特征,这有助于捕获初始层中的局部频率以及更深层中的全局特征.
网络细节


实验








关键代码
Attention block:
# https://github.com/badripatro/SpectFormers/blob/main/hierarchical_architecture/spectformer.py
class SpectralGatingNetwork(nn.Module):
def __init__(self, dim):
super().__init__()
# this weights are valid for h=14 and w=8
if dim == 64: #96 for large model, 64 for small and base model
self.h = 56 #H
self.w = 29 #(W/2)+1
self.complex_weight = nn.Parameter(torch.randn(self.h, self.w, dim, 2, dtype=torch.float32) * 0.02)
if dim ==128:
self.h = 28 #H
self.w = 15 #(W/2)+1, this is due to rfft2
self.complex_weight = nn.Parameter(torch.randn(self.h, self.w, dim, 2, dtype=torch.float32) * 0.02)
if dim == 96: #96 for large model, 64 for small and base model
self.h = 56 #H
self.w = 29 #(W/2)+1
self.complex_weight = nn.Parameter(torch.randn(self.h, self.w, dim, 2, dtype=torch.float32) * 0.02)
if dim ==192:
self.h = 28 #H
self.w = 15 #(W/2)+1, this is due to rfft2
self.complex_weight = nn.Parameter(torch.randn(self.h, self.w, dim, 2, dtype=torch.float32) * 0.02)
def forward(self, x, H, W):
# print('wno',x.shape) #CIFAR100 image :[128, 196, 384]
B, N, C = x.shape
# print('wno B, N, C',B, N, C) #CIFAR100 image : 128 196 384
x = x.view(B, H, W, C)
# B, H, W, C=x.shape
x = x.to(torch.float32)
# print(x.dtype)
# Add above for this error, RuntimeError: Input type (torch.cuda.HalfTensor) and weight type (torch.cuda.FloatTensor) should be the same
x = torch.fft.rfft2(x, dim=(1, 2), norm='ortho')
# print('wno',x.shape)
weight = torch.view_as_complex(self.complex_weight)
# print('weight',weight.shape)
x = x * weight
x = torch.fft.irfft2(x, s=(H, W), dim=(1, 2), norm='ortho')
# print('wno',x.shape)
x = x.reshape(B, N, C)# permute is not same as reshape or view
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.q = nn.Linear(dim, dim)
self.kv = nn.Linear(dim, dim * 2)
self.proj = nn.Linear(dim, dim)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x
Transformer block:
# https://github.com/badripatro/SpectFormers/blob/main/hierarchical_architecture/spectformer.py
class Block(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio,
drop_path=0.,
norm_layer=nn.LayerNorm,
sr_ratio=1,
block_type = 'wave'
):
super().__init__()
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
if block_type == 'std_att':
self.attn = Attention(dim, num_heads)
else:
self.attn = SpectralGatingNetwork (dim)
self.mlp = PVT2FFN(in_features=dim, hidden_features=int(dim * mlp_ratio))
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x