文章目录
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、决策树是什么?
1.首先决策树的概念就是:
①它其实就是一种树形结构,其中每个内部节点就表示一个属性上的测试,每个分支代表着一个测试输出,每个叶节点代表着一种类别,
②它其实是一种基本的分类与回归的方法。
③它算法的原则就是让我们的损失函数最小化,其实从训练数据集中归纳出一组分类规则也就是它的本质。
④它的模型具有可读性,并且分类速度快。
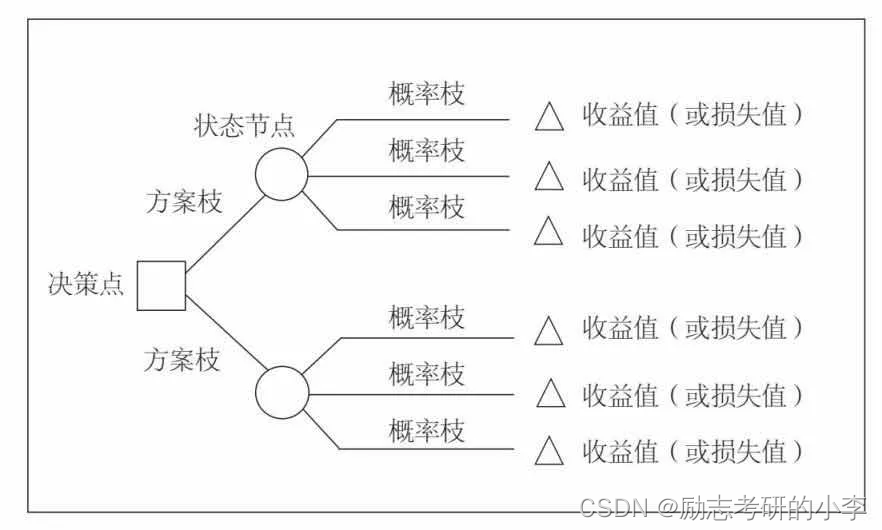
2.大概的主要结构有:
①根节点,也就是第一个被选筛选的条件;
②分支,就是那连接的线;
③分叶子节点,就是说处于中间,还可以再分,做分类的话就输出得票最多的类,做回归的话就输出样本标签的均值;
④叶子节点,就是不可再分了的节点。
二、如何进行去特征选择呢?
1.如何进行去特征选择呢?
一种通过信息增益,另一种通过信息增益率。
2.这个树它长什么时候停呢?
一种是取它信息中增益最大的(把每个特征都走完)就终止了,另一种是划分节点很纯(就是当特征为0的时候,就只剩下1个标签),需要注意的是,这两个终止条件是“并行”的,也就是说同时进行的。
3.这个树怎么长的呢?
首先我们需要先知道,熵是个什么东西,它是物理上的一个概念,表示混乱程度,熵越大表示越混乱,特征的概率越大,熵就越小,不纯度越低。我们确定特征原则方法的时候,也就需要去计算每个特征的信息增益(信息增益=原始熵-划分后的信息熵),我们选择信息增益最大的那个特征。
三、拔高亮点
因为选择参考的指标不同,所以也就有这么几种:ID3、ID4.5算法的决策树以及CART分类树这几种常见的决策树。
- ID3算法的决策树采用的是信息增益(香农熵增益=结点的香农熵 –
子结点香农熵的带权和),可以用来做分类。但是它也有缺点,比如说:①首先没有剪枝策略,容易过拟合;②信息增益偏向于选择取值较多的特征;③只能用于处理离散分布的特征;④没有考虑缺失值。 - ID4.5算法的决策树采用的是信息增益率(香农熵增益比=参数 x
香农熵增益),可以用来做分类。信息增益率=信息增益/自身的熵值,即使信息增益变大,除以一个自身熵值也就抵消了。同样它也是有缺点的,比如:①用的是多叉树,但是二叉树的效率高;②就只能用来做分类。 - CART分类树采用的是基尼系数(基尼指数增益=结点的基尼指数 – 子结点的基尼指数的带权和),它可以既用来做分类、也可以做回归。
四、总结
不论是什么决策树,我们都需要进行剪枝操作,因为如果不剪枝的话容易发生过拟合,大概分为两种方式,一种是预剪枝,因为层数越多,越容易过拟合,常用:直接设定层类、叶结点个数等,并且在训练前。优点吧就是性能开销小、速度快,缺点吧就是可能会欠拟合,错过最优解。另一种是后剪枝,就是说在训练后,自底向上地,如果删除该划分能提高泛化性能就删除,优点吧就是欠拟合风险小,缺点吧就是性能开销大、速度慢。
更多详情视频可参考:b站详情解说视频