决策树
决策树在集成学习中的地位

整个集成学习会按照是否有线程的小的模型(g)分为两种。如果我们有g的话我们就会用blending。如果想一边学习g一边融合模型就会用到Bagging或AdaBoost。
①在biending中如果是用平均组合的话可以用平均投票的方式,如果每个g所占的权重不同的时候就可以用线性模型组合这些g(此时这些g可以当做是原始资料的一种特征转换)。如果我们的投票活动与具体的情况有关那么g在这里任然可以当做是特征转换,而且在得到g之后会进行非线性的转换。
②在边学边融合的模型中如果是将所得模型平均的组合可以使用Bagging,其中Bagging的核心是BootStrap。当我们有一堆比较弱的g时我们需要用Adaboosting演算法将g线性融合进而得到非常强大的g。而在边学边融合的而且得到的g需要分情况来融合时我们就用到了决策树模型。
决策树的两种角度
路径角度
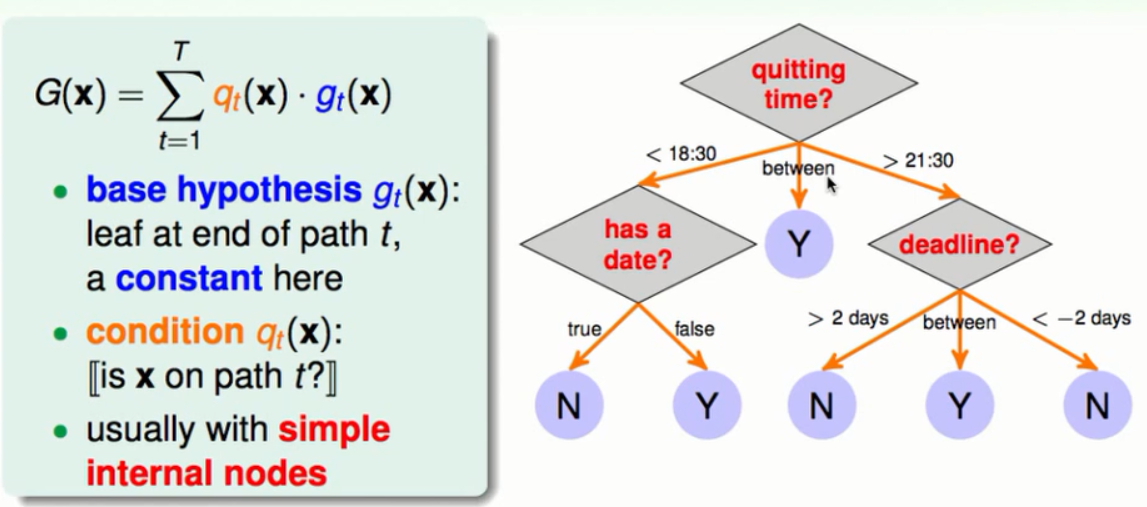
从根节点出发经过一些条件的判断和选择最终到达一个子节点这种角度就是决策树的路径角度,每一条路径最后会到达一个子节点。其中这些子节点就好比是我们要融合的g只不过g在这里可能是一些常量。不同的分支选择就是我们提到的不同条件。所以就会得到上图中的模型。
递归角度
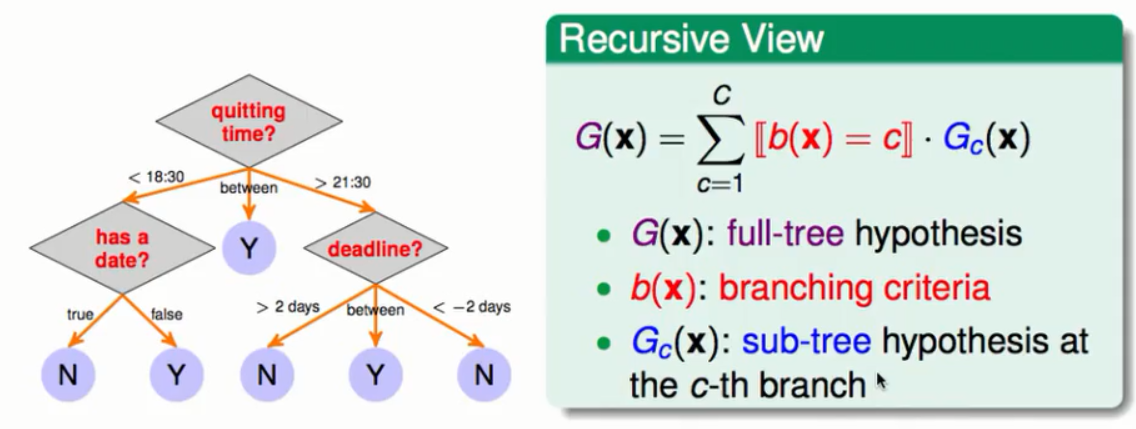
递归角度所讲的就是,从根节点出发进行分支其中每一个分支都会连接一颗子树,而每一颗子树也都会有自己的根节点从这些根节点出发又会有不同的分支些分支又连接了不同的子树,依次类推下去。所以每当选中一个分支时一定会对应一颗子树,也就形成了上图中所展现的递归模型了。
决策树的优缺点
优点:比较符合人类决策的过程,学习起来比较简单。在预测和训练的时候都比较高效。
缺点:缺乏理论上的保证,在设计的时候会用到大量的从业人员的巧思在里面。
CA&T演算法
基本的决策树演算法
一般决策树会分为这几个步骤:
①要将现有的资料怎么分支。
②到底要将手上的资料分为几支。
③在分开的资料上各自学到一个小的模型。
④将小的模型融合成为大的模型。
当然很关键的一步就是要有一个终点什么时候停下来,我们规定当能够返回g的时候(也就是叶子节点的时候停下来)。

Classification and Reression Tree(CA&T)
这个树的特点:
①这棵树是一颗二叉树
②它的基本的叶子节点是常数。
如果是二元分类的话那么我们就认为最好的预测就是表现相同的最多的那个。如果是线性回归并且使用平方错误作为错误衡量的时候最好的预测就是当前资料的平均值。
Cart与纯度
在进行分支(二分)的时候我们通常使用decision stump(根据资料的其中一个特点来切分资料)。至于它切的怎么样或者是如何切分资料才是最好的,我们用纯度来横量。总的来说是当切分完资料之后每一部分的资料的纯度越高那么我们就说这种分支的方式就越好。所以我们通常就是用decision stump的方式来分割用纯度来作为衡量最后选择最好的那个decision stump。
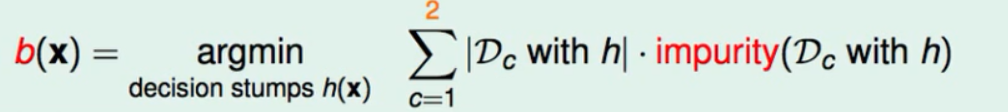
不纯度的衡量
不纯度是一种错误衡量的方式,越不纯说明分割资料的误差就越大。
在平方错误的回归问题中不纯度就是每一个资料点的表现值与平均表现值的方差之和。而在分类问题中不纯度往往会是与最多的那种资料不同的资料数目之和的平均值。但是这种判断方式不能够将所有的资料都考虑进来,实务上我们会使用每种资料所占的比例的平方和来作为纯度的衡量标准,同时这种衡量标准也被称为是Gini系数。

CA&T的终点
①当当前资料上资料的表现都相同的时候也就是不纯度为0的时候我们就会停下来,因为再分割下去没有任何意义。
②当所有的资料点都相同时候(比如说只有一个点的时候),我们做没法做descisionstump也就没办法分割。
这种被迫停下来的树被称为完全长成树,它的叶子节点是常量,分支的时候是二分的分支的衡量就是让资料越纯越好。
决策树的正则化与其它特质
决策树的正则化
在完全长成树中如果起始值输入的值不同那么就会出现损失函数(Ein)的值为0的情况。但是对于我们来说Ein为0并不是一件好的事情因为此时的模型复杂度会很高而且它容易出现过拟合的危险。所以我们要对它进行正则化。
直观的来看切得刀数越多的树在每一个节点上的资料会越来越少,所以这棵树的树叶越多的也就分割的颗粒越少同时也伴随着模型复杂度的提高。所以我们想要的是叶子节点不多但是表现还不错的一棵树。这样使用减少叶子的做法(决策树剪枝)可能达到正则化的效果。
我们可能的一种做法就是列出所有可能的树然后选择一棵综合素质最好的树(Ein(G)+λΩ(G)最低)也就是在正则化的条件下最好的树,但是这样太费力气。实务上我们通常是从一个完全长成的树开始,然后分别拿掉每一片叶子看看拿掉哪一片叶子的时候这棵树表现的最好,这样接下来再以相同的方式拿掉第二片叶子以此类推。这样我们的剪枝过程就比以前轻松许多,以前是列出了所有的树在所有的树中做选择,而现在是列出了一些高品质的树在高品质的树中做选择。

至于如何选择参数λ我们可以使用validation。
从数字特性到类别特性
一般情况我们可能会遇到数字上的特性我们在做分支的时候就是去做decisionstump不如在某个维度上大于某个阈值的走左边,小于某个阈值的走右边。而在非数字特征的问题上我们没有阈值的概念所以我们的分支依靠的是决策子集合,我们要从所有的子集合的分类中选择一个最好的分配方式。

决策树的代理特性
决策树的核心就是切割而且切割通常是依赖于一个物体的特性。比如说大于50公斤的走左边,小于等于50公斤的走右边。我们是依靠体重这个维度来进行分割的,要是现在来了一个没有量过体重的人怎么办(假设这个人的体重无法测量)。我们就可以找一个替代的特征,比如说身高在155cm以上的人通常都会大于50公斤,这时我们就可以拿着身高来代替体重的特征了。
总结决策树会有以下的特性:
①它的决策过程与人类做决策的过程非常类似。
②能够很轻易的处理多元分类问题。
③能够处理类别特征的问题。
④能够进行特征替代。
⑤能够做出非线性的边界。