一.熵的相关知识
1.熵,也称信息熵
是表示随机变量不确定性的度量,不确定性越大,熵越大,定义如下:

来理解一下,如果X的取值为固定某个值,这时不确定性最小,H(X)=-1*log1=0;
如果X服从均匀分布,这时不确定性最大,H(X)=log n,
所以H(X)的范围为 0<=H(X)<=log n
2.条件熵的定义:

3.信息增益:
表示得知特征X的信息而使得类Y的信息的熵减小的程度。

我们希望决策树的分类确定性越强,这样损失就越小,也就是说决策树的分支节点所包含的样本尽可能属于同一类,这样结点的熵就越小,而信息增益表示特征A来分类使得样本D的熵减小的程度,所以我们选择信息增益最大的特征来作为切分点。
看看g(D,A)的定义,H(D)表示数据集D的熵,H(D|A)表示在特征A给定的条件下的熵,g(D,A)是他们的差,就表示由于特征A是的数据集D的熵减小的程度。
计算方式如下:
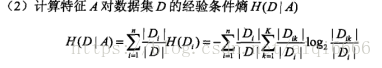
ID3决策树就是信息增益为准则选择划分属性。
二.信息增益率:
前面的信息增益准则对可能取值数目教=较多的属性有所偏好,为减少这种偏好带来的不利影响,C4.5算法采用信息增益率来选择最优划分特征:
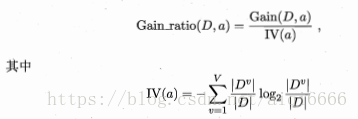
V表示属性a取值的个数,Dv表示每个取值的个数。
同理,增益率对取值较少的属性偏好,所以C4.5的选取方式为:

注意,ID3和C4.5构造决策树时每用一个属性就舍弃掉一个。
三.剪枝的问题:
决策树的剪枝是根据损失函数来的,损失函数定义为:
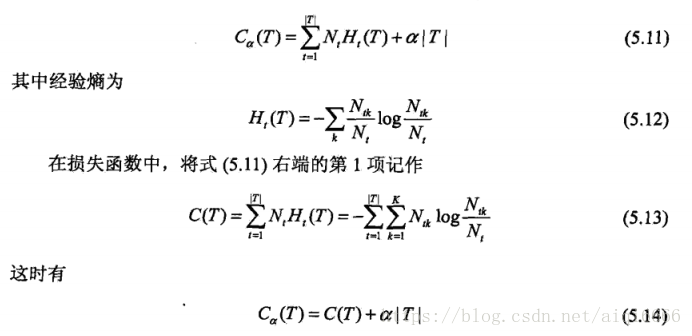
在ID3/C4.5中,是在给定α的条件下,从叶节点往根节点的方向回溯,如果在回溯的过程中,下级的结点相比上级的结点损失函数反而增加了,说明下级没有存在的必要,于是就被剪掉了。
四.CART决策树:
CART成为分类回归树,是一颗二叉树,只有左右叶子节点
1.CART分类树:
基尼指数:

在特征A的条件下,D的基尼指数:

Gini(D,A)表示经A=a分割后集合D的不确定性,所以选择基尼指数最小的切分点。
2.CART回归树:


3.CART剪枝:两步
- 通过剪枝形成一个子树序列(自下而上)
问题来了,一棵树,应该剪掉哪一个结点?
- 在剪枝得到的子序列T0,T1,…Tn中通过交叉验证选取最有子树Tα
具体是利用一个独立的验证数据集来测试选择



五.决策树对缺失值的处理:
问题1:如何在属性缺失值的情况下进行划分属性选择?
注意,样本的初始权重都为1


问题2:给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?

六.决策树对连续值的处理:
对于连续属性a,我们可以考察包含n-1个元素的候选点划分的集合:

需要注意的是,若当前节点的划分为连续属性时,该属性还可作为其后代节点的划分属性。