1.数据集整理
数据集可以使用pandas里面提供的load_iris,使用DataFrame获取并初始化数据集data和特征名称,并创建列表名称target获取数据集的目标值,然后将iris中的数据集使用np.array封装
iris = load_iris()
iris_data = pd.DataFrame(data=iris.data, columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_data['target'] = iris.target
def DataSet():
group = np.array(iris.data)
labels = iris['target']
return group,labels2.图像分布
使用seaborn库中的lmplot函数,指定x为传递的属性、y为传递的目标值,并通过hue='target'指定分布点为目标值,通过rcParams['font.sans-serif']=['SimHei']指定字体,并通过plt.xlabel()来指定坐标轴参数,plt.ylabel()来指定目标值数据,使用plt.show()展示图像
def plt_iris(data,col1,col2):
sns.lmplot(x=col1,y=col2,data=data,hue='target',fit_reg=False)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.title("鸢尾花数据展示")
plt.xlabel(col1)
plt.ylabel(col2)
plt.show()3.KNN算法实现
欧式距离公式: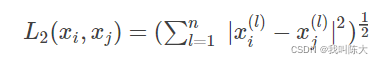
求输入数据对每个样本的欧式距离并排序,选择前k个距离最小的样本,顺序取出距离最小的索引对应的目标值标签,并计算标签出现频率最高的一个作为结果返回

def KNN_iris(in_x,x_labels,y_labels,k):
x_labels_size = x_labels.shape[0]
distances = (np.tile(in_x,(x_labels_size,1))-x_labels)**2 # 创建x_label_size行,1列的内容为in_x的数组
ad_distances = distances.sum(axis=1)
sq_distances = ad_distances**0.5
ed_distances = sq_distances.argsort() # 对距离进行排序,返回sq_distances索引,根据se_distance从小到大排序
print(ed_distances)
classdict={}
for i in range(k):
key = y_labels[ed_distances[i]] # 顺序取出距离最小的索引对应的标签
classdict[key] = classdict.get(key,0)+1 #统计每个key(标签)出现的《频率》存储到字典classdict对应标签的value
sort_classdict = sorted(classdict.items(),key=operator.itemgetter(1),reverse=True) #是按key大小排列字典
return sort_classdict[0][0]4.测试数据
输入4维特征值数据,获取数据集特征样本和目标值列表,调用KNN函数进行测试
if __name__=='__main__':
plt_iris(iris_data,'Sepal_Length','Petal_Width')
group,labels = DataSet()
test_x = [6.0,1.6,8.1,1.5]
print('此鸢尾花数据所对应的类别是:{}'.format(KNN_iris(test_x, group, labels, 5)))测试结果:
