任务描述
使用sklearn完成鸢尾花分类任务。

鸢尾花数据集是一类多重变量分析的数据集。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类(其中分别用0,1,2代替)。
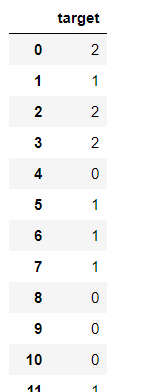
数据集中部分数据与标签如下图所示:

DecisionTreeClassifier
DecisionTreeClassifier的构造函数中有两个常用的参数可以设置:
criterion:划分节点时用到的指标。有gini(基尼系数),entropy(信息增益)。若不设置,默认为gini
max_depth:决策树的最大深度,如果发现模型已经出现过拟合,可以尝试将该参数调小。若不设置,默认为None
和sklearn中其他分类器一样,DecisionTreeClassifier类中的fit函数用于训练模型,fit函数有两个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放训练样本;
Y:值为整型,大小为[样本数量]的ndarray,存放训练样本的分类标签。
DecisionTreeClassifier类中的predict函数用于预测,返回预测标签,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本。
DecisionTreeClassifier的使用代码如下:
from sklearn.tree import DecisionTreeClassifier
clf = tree.DecisionTreeClassifier()
clf.fit(X_train, Y_train)
result = clf.predict(X_test)
编程要求
实现鸢尾花数据的分类任务,其中训练集数据保存在./step7/train_data.csv中,训练集标签保存在。./step7/train_label.csv中,测试集数据保存在。./step7/test_data.csv中。请将对测试集的预测结果保存至。./step7/predict.csv中。这些csv文件可以使用pandas读取与写入。
注意:当使用pandas读取完csv文件后,请将读取到的DataFrame转换成ndarray类型。这样才能正常的使用fit和predict。
示例代码:
import pandas as pd
# as_matrix()可以将DataFrame转换成ndarray
# 此时train_df的类型为ndarray而不是DataFrame
train_df = pd.read_csv('train_data.csv').as_matrix()
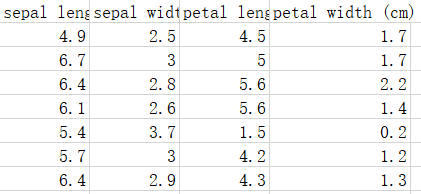
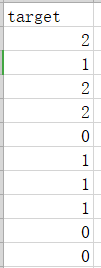
数据文件格式如下图所示:
通关代码:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
train_df = pd.read_csv('./step7/train_data.csv').as_matrix()
train_label = pd.read_csv('./step7/train_label.csv').as_matrix()
test_df = pd.read_csv('./step7/test_data.csv').as_matrix()
dt = DecisionTreeClassifier()
dt.fit(train_df, train_label)
result = dt.predict(test_df)
result = pd.DataFrame({'target':result})
result.to_csv('./step7/predict.csv', index=False)

