kNN(K Nearest Neighbor)算法是机器学习中最基础入门,也是最常用的算法之一,可以解决大多数分类与回归问题。这里以鸢尾花数据集为例,讨论分类问题中的 kNN 的思想。
鸢尾花数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal length)。
可以通过这 4 个特征预测鸢尾花卉属于(iris-setosa,,iris-versicolour, iris-virginica)中的哪一品种,这里使用 kNN 来预测。
首先,导入鸢尾花数据集(两种方式,一种是下载鸢尾花数据集,然后从文件读取,我们采用第二种,直接从datasets中读取,返回的是字典格式的数据),并将鸢尾花数据集分为训练集和测试集。
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 随机划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=20, shuffle=True)
为了方便理解 kNN,将鸢尾花的训练数据的前两个特征值,分别作为 x 轴和 y 轴数据,进行可视化。
# 数据可视化
plt.scatter(X_train[y_train == 0][:, 0], X_train[y_train == 0][:, 1], color='r')
plt.scatter(X_train[y_train == 1][:, 0], X_train[y_train == 1][:, 1], color='g')
plt.scatter(X_train[y_train == 2][:, 0], X_train[y_train == 2][:, 1], color='b')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.show()

如图所示,三个不同的颜色分别代表鸢尾花的三个类别。现在如果有一个新的数据(图中黑色点表示),如何判断它属于哪个类别呢?
我们需要使用的 kNN 算法,正如它的英文 K Nearest Neighbor,算法的核心思想是,选取训练集中离该数据最近的 k 个点,它们中的大多数属于哪个类别,则该新数据就属于哪个类别。
根据它的核心思想,模型中有三个需要确定的要素:
- k 如何选择
- 如何确定「最近」,也就是如何度量距离
- 如何确定分类的规则
其中,k 的选择是一个超参数的选择问题,需要通过调整 K 的值确定最好的 K,最好选奇数,否则会出现同票。
可以通过交叉验证法确定模型的最佳 k 值(这里后面会谈);
度量距离的方式,一般为 Lp 距离:
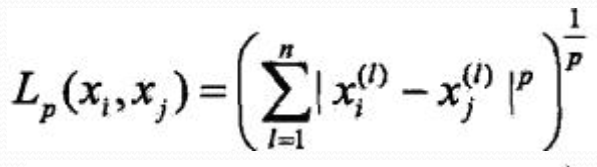
p = 1 时,为曼哈顿距离:

p = 2 时,为欧式距离:
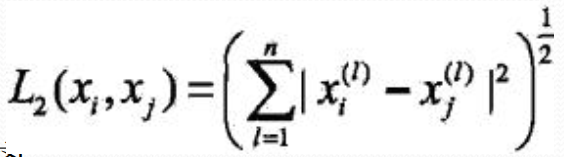
欧式距离是我们最常用的计算距离的方式。
分类的规则,采取多数表决的原则,即由输入实例的 k 个近邻的训练实例中的多数类决定输入实例的类。
代码如下:
# 计算距离,默认为欧氏距离
def calculateDistance(data1, data2, p=2):
if len(data1) == len(data2) and len(data1) >= 1:
sum = 0
for i in range(len(data1)):
sum += math.pow(abs(data1[i] - data2[i]), p)
dist = math.pow(sum, 1/p)
return dist
# knn模型分类
def knnClassify(X_train, y_train, test_data, k):
dist = [calculateDistance(train_data, test_data) for train_data in X_train]
# 返回距离最近的k个训练样本的索引(下标)
indexes = np.argsort(dist)[:k]
count = Counter(y_train[indexes])
return count.most_common(1)[0][0]
if __name__ == '__main__':
# 预测结果
predictions = [knnClassify(X_train, y_train, test_data, 3) for test_data in X_test]
# 与实际结果对比
correct = np.count_nonzero((predictions == y_test) == True)
print("Accuracy is: %.3f" % (correct/len(X_test)))
这里是自己实现的分类代码,在 sklearn 中有封装好的 kNN 库,代码如下:
# 创建kNN_classifier实例
kNN_classifier = KNeighborsClassifier(n_neighbors=3)
# kNN_classifier做一遍fit(拟合)的过程,没有返回值,模型就存储在kNN_classifier实例中
kNN_classifier.fit(X_train, y_train)
correct = np.count_nonzero((kNN_classifier.predict(X_test) == y_test) == True)
print("Accuracy is: %.3f" % (correct/len(X_test)))
kNN 没有显式的学习过程,这是它的优点,但在用它进行数据分类时,需要注意几个问题:
- 不同特征有不同的量纲,必要时需进行特征归一化处理
- kNN 的时间复杂度为
O(D*N*N),D 是维度数,N 是样本数,这样,在特征空间很大和训练数据很大时,kNN 的训练时间会非常慢。这时就需要用到 kd 树,可以将时间复杂度降为O(logD*N*N)(kd 树后面会讲)。
参考文章:机器学习-kNN 算法
