sklearn KNN算法实现鸢尾花分类
- 编译环境
- python 3.6
- 使用到的库
- sklearn
简介
本文利用sklearn中自带的数据集(鸢尾花数据集),并通过KNN算法实现了对鸢尾花的分类。
KNN算法核心思想:如果一个样本在特征空间中的K个最相似(最近临)的样本中大多数属于某个类别,则该样本也属于这个类别。
sklearn库介绍
自2007年发布以来,scikit-learn已经成为最给力的Python机器学习库(library)了。scikit-learn支持的机器学习算法包括分类,回归,降维和聚类。还有一些特征提取(extracting features)、数据处理(processing data)和模型评估(evaluating models)的模块。
安装:
pip install sklearn鸢尾花数据集介绍
sklearn.datasets.load_iris() # 加载并返回鸢尾花数据集| 名称 | 数量 |
|---|---|
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
KNN算法距离计算公式
两个样本的距离也就是欧式距离,比如:样本a(a1,a2,a3)和样本b(b1,b2,b3)的距离
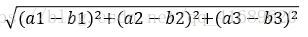
sklearn KNN算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
获取鸢尾花数据
from sklearn.datasets import load_iris
def get_iris_data(self):
iris = load_iris()
iris_data = iris.data # 鸢尾花特征值(4个)
iris_target = iris.target # 鸢尾花目标值(类别)
return iris_data, iris_target将数据分成测试集和训练集
from sklearn.model_selection import train_test_split
# x_train 训练集特征值 x_test 测试集特征值 y_train 训练集目标值 y_test 测试集目标值 test_size=0.25 表示25%的数据用于测试
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25)特征工程(对特征值进行标准化处理)
特点:由于每个特征的大小,取值范围等不一样,这样会导致每个特征的权重不一样,而实际上是一样的。通过对原始数据进行变换把数据变换到均值为0,方差为1范围内。这样每个特征值的权重变得一样,以便于计算机处理。
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)送入算法
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5) # 创建一个KNN算法实例,n_neighbors默认为5,后续通过网格搜索获取最优参数
knn.fit(x_train, y_train) # 将测试集送入算法
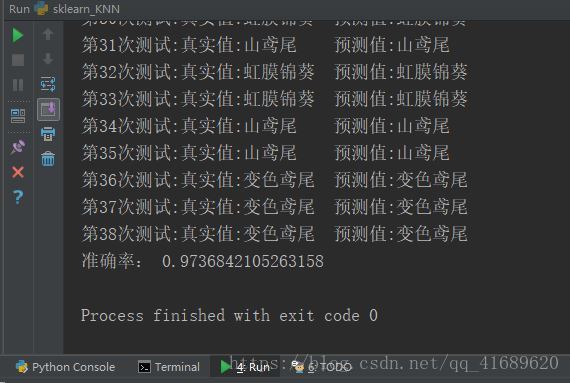
y_predict = knn.predict(x_test) # 获取预测结果结果展示
源代码
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
class KNN(object):
"""
利用KNN算法对鸢尾花进行分类
"""
# 获取鸢尾花数据 三个类别(山鸢尾/0,虹膜锦葵/1,变色鸢尾/2),每个类别50个样本,每个样本四个特征值(萼片长度,萼片宽度,花瓣长度,花瓣宽度)
def get_iris_data(self):
iris = load_iris()
iris_data = iris.data
iris_target = iris.target
return iris_data, iris_target
def run(self):
# 1.获取鸢尾花的特征值,目标值
iris_data, iris_target = self.get_iris_data()
# 2.将数据分割成训练集和测试集 test_size=0.25表示将25%的数据用作测试集
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25)
# 3.特征工程(对特征值进行标准化处理)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 4.送入算法
knn = KNeighborsClassifier(n_neighbors=5) # 创建一个KNN算法实例,n_neighbors默认为5,后续通过网格搜索获取最优参数
knn.fit(x_train, y_train) # 将测试集送入算法
y_predict = knn.predict(x_test) # 获取预测结果
# 预测结果展示
labels = ["山鸢尾","虹膜锦葵","变色鸢尾"]
for i in range(len(y_predict)):
print("第%d次测试:真实值:%s\t预测值:%s"%((i+1),labels[y_predict[i]],labels[y_test[i]]))
print("准确率:",knn.score(x_test, y_test))
if __name__ == '__main__':
knn = KNN()
knn.run()交叉验证和网格搜索
前面介绍的n_neighbors默认为5,而实际上该用何值是需要我们调试的,手工调试比较麻烦。sklearn为我们提供了一个工具,可用于自动调试,并选择出最好的参数——交叉验证和网格搜索
交叉验证:(为了让模型更加准确可信)将所拿到的数据,分类训练和验证集。即将数据分为n份,将其中一份作为验证集,经过n组测试,每组测试时都要更换验证集。这样得到n组模型的结果,取平均值作为最终的结果。
网格搜索:通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
from sklearn.model_selection import GridSearchCV
gridCv = GridSearchCV(estimator, param_grid=None,cv=None)- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
实例
# 生成knn估计器
knn = KNeighborsClassifier()
# 构造超参数值
params = {"n_neighbors":[3,5,10]}
# 进行网格搜索
gridCv = GridSearchCV(knn, param_grid=params, cv=5)
gridCv.fit(x_train,y_train) # 输入训练数据
# 预测准确率
print("准确率:",gridCv.score(x_test, y_test))
print("交叉验证中最好的结果:",gridCv.best_score_)
print("最好的模型:", gridCv.best_estimator_)网格搜索结果
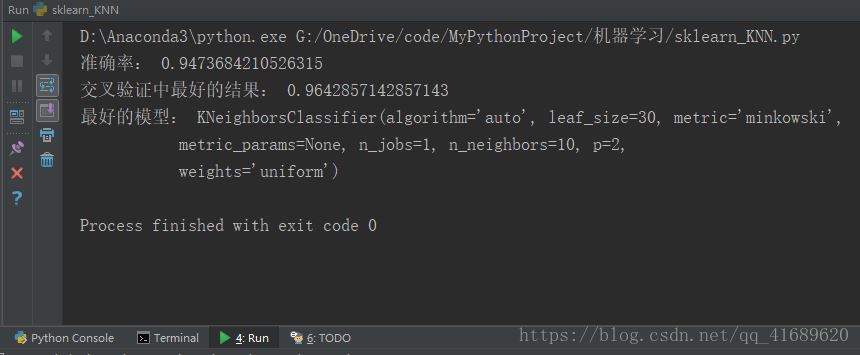
从结果中可以看出:n_neighbors=10的时候,该模型的结果最好。
总结:
KNN算法是机器学习中最简单的一种算法,该算法具有以下特点:
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型