基于sklearn的KNN算法实现鸢尾花的分类
数据集下载:GitHub
1.数据准备
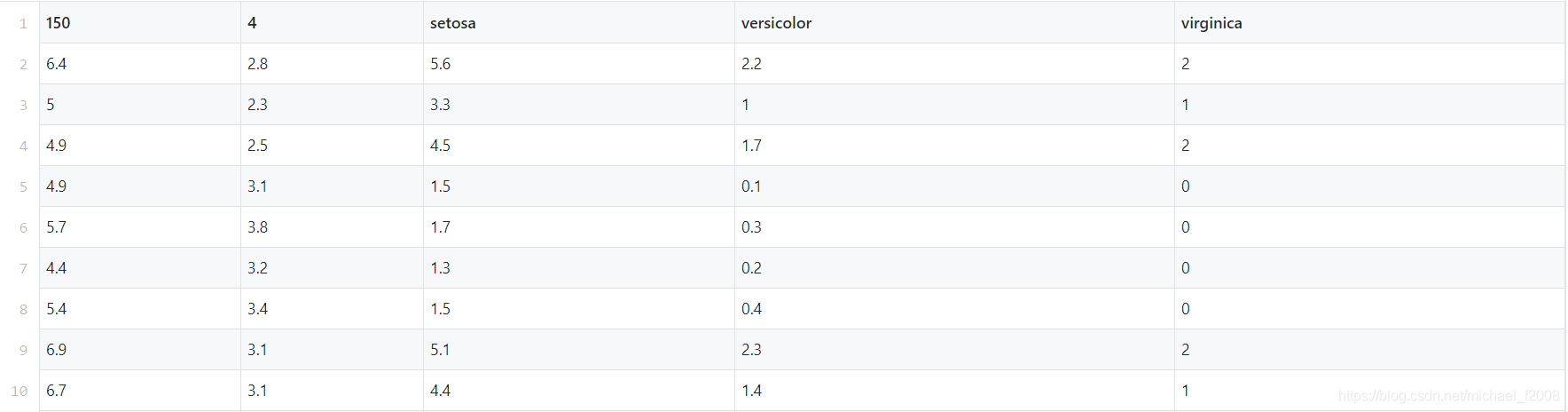
学习分类问题,鸢尾花数据集是比较常用的样例。本文使用的是原始数据,有效数据总共150条,内容和格式未做修改。
前10行的数据如下所示:
2.导入几个包
包括pandas和sklearn的几个包:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
3.划分训练集和测试集
首先,将数据集的前四列提取出来作为特征,最后一列作为分类标签;然后,利用train_test_split()将特征和标签随机的划分为训练集和测试,这里设定测试集的比例为20%,也就是30条;最后,将训练集和测试集的标签转换为一维数组(不转换也可以,只是为了看着方便)。
# 读取数据
iris_data_set = pd.read_csv("D:\\iris.csv")
# x是4列特征
x = iris_data_set.iloc[:, 0:4].values
# y是1列标签
y = iris_data_set.iloc[:, -1].values
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 将特征转为一维数组
y_train = y_train.flatten()
y_test = y_test.flatten()
4.训练模型并预测
首先,通过调用KNeighborsClassifier()函数建立KNN算法模型,这里的n_neighbors=3表示将K值设为3;然后,输入训练集的特征和分类标签进行训练;最后,将测试集的特征应用在模型上,进行分类并获得分类结果。
# 建模
knn_model = KNeighborsClassifier(n_neighbors=3)
# 训练
knn_model.fit(x_train, y_train)
# 预测
y_pre = knn_model.predict(x_test)
5.结果输出及分析
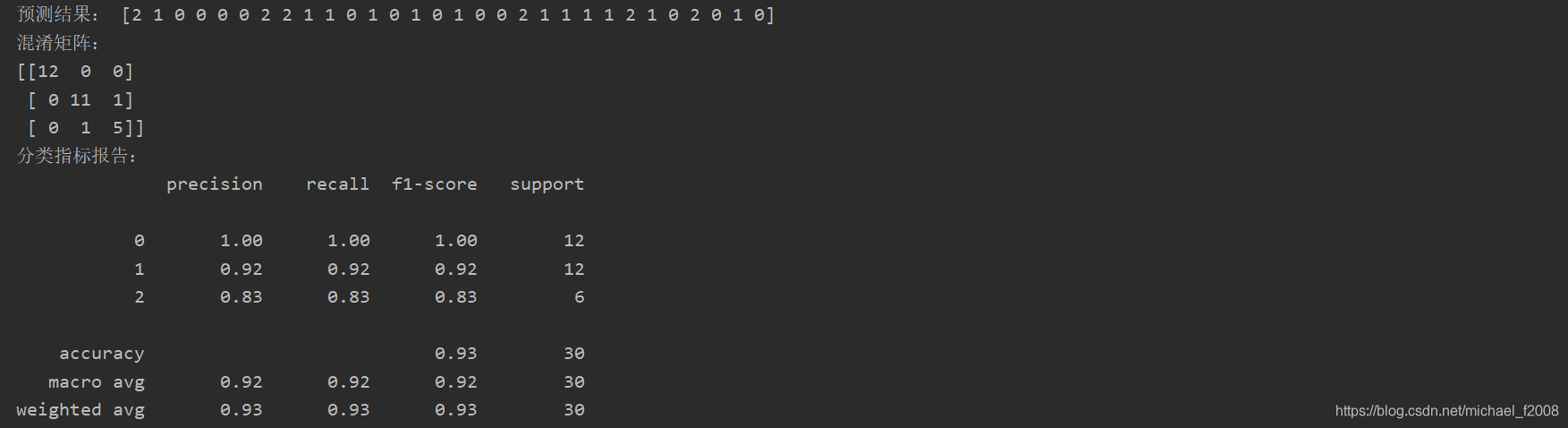
将测试集的实际分类和模型预测的分类打印出来,可以直观地进行比较。
混淆矩阵(confusion matrix)是评价分类模型优劣的重要依据,调用confusion_matrix()即可返回模型的混淆矩阵。
评价分类模型有很多指标,可以通过classification_report()函数进行输出。
print("正确标签:", y_test)
print("预测结果:", y_pre)
# 混淆矩阵
conf_mat = confusion_matrix(y_test, y_pre)
print(conf_mat)
# 分类指标文本报告(精确率、召回率、F1值等)
print(classification_report(y_test, y_pre))
最终结果如下:
6.总结
可以看出,基于sklearn的API,不用写太多的代码,就能够很方便地进行数据集划分、模型建立、模型训练和分类预测,而且也可以对模型的分类指标进行计算。
完整的代码如下所示:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
# 读取数据
iris_data_set = pd.read_csv("D:\\iris.csv")
# x是4列特征
x = iris_data_set.iloc[:, 0:4].values
# y是1列标签
y = iris_data_set.iloc[:, 4:].values
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 将特征转为一维数组
y_train = y_train.flatten()
y_test = y_test.flatten()
# 建模、训练、预测
knn_model = KNeighborsClassifier()
knn_model.fit(x_train, y_train)
y_pre = knn_model.predict(x_test)
print("正确标签:", y_test)
print("预测结果:", y_pre)
# 混淆矩阵
conf_mat = confusion_matrix(y_test, y_pre)
print(conf_mat)
# 分类指标文本报告(精确率、召回率、F1值等)
print(classification_report(y_test, y_pre))
扩展学习
- Python 基于BP神经网络的鸢尾花分类
- 机器学习分类问题指标理解——准确率(accuracy)、精确率(precision)、召回率(recall)、F1-Score、ROC曲线、P-R曲线、AUC面积
- Python 多维数据可视化
欢迎关注我的微信公众号:
