基于Ray AIR的CIFAR-10图像分类器
本教程将向您展示如何使用 Ray AI Runtime (AIR) 训练图像分类器。
训练数据集为CIFAR-10。CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。
与MNIST 数据集中目比, CIFAR-10 以下不同点
- CIFAR-10 是3 通道的彩色RGB 图像,而MNIST 是灰度图像
- CIFAR-10 的图片尺寸为32 × 32 , 而MNIST 的图片尺寸为28 × 28 ,比MNIST 稍大
- CIFAR-10 是现实世界中真实的物体,噪声很大,而且物体的比例、特征都不尽相同,识别困难

在CIFAR-10 数据集中,文件data_batch_1.bin、data_batch_2.bin 、··data_batch_5.bin 和test_ batch.bin 中各有10000 个样本。一个样本由3073 个字节组成,第一个字节为标签label ,剩下3072 个字节为图像数据。样本和样本之间没高多余的字节分割, 因此这几个二进制文件的大小都是30730000 字节。
 运行环境为Anaconda的RayRllib。
运行环境为Anaconda的RayRllib。
准备数据集
通过代码下载数据集:
import ray
import torchvision
import torchvision.transforms as transforms
train_dataset = torchvision.datasets.CIFAR10("data", download=True, train=True)
test_dataset = torchvision.datasets.CIFAR10("data", download=True, train=False)
train_dataset: ray.data.Dataset = ray.data.from_torch(train_dataset)
test_dataset: ray.data.Dataset = ray.data.from_torch(test_dataset)接下来,让使用 ndarray 的字典而不是元组来表示数据。这样可以在稍后的教程中调用 Dataset.iter_torch_batches。
from typing import Dict, Tuple
import numpy as np
from PIL.Image import Image
import torch
def convert_batch_to_numpy(batch: Tuple[Image, int]) -> Dict[str, np.ndarray]:
images = np.stack([np.array(image) for image, _ in batch])
labels = np.array([label for _, label in batch])
return {"image": images, "label": labels}
train_dataset = train_dataset.map_batches(convert_batch_to_numpy).fully_executed()
test_dataset = test_dataset.map_batches(convert_batch_to_numpy).fully_executed()训练卷积神经网络
现在已经创建了数据集,下面定义训练逻辑。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x下面使用名为 train_loop_per_worker 的函数中定义训练逻辑。
这个函数包含常规的 PyTorch 代码,但有几个值得注意的地方:
- 用 train.torch.prepare_model 包装我们的模型。
- 调用 session.get_dataset_shard 和 Dataset.iter_torch_batches 来获取训练数据的一个子集。指定正确的设备以将张量移动到 GPU 训练。
- 使用 session.report 保存模型状态。
from ray import train
from ray.air import session, Checkpoint
from ray.train.torch import TorchCheckpoint
import torch.nn as nn
import torch.optim as optim
import torchvision
def train_loop_per_worker(config):
model = train.torch.prepare_model(Net())
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
train_dataset_shard = session.get_dataset_shard("train")
for epoch in range(20): # 控制训练的回合数
running_loss = 0.0
train_dataset_batches = train_dataset_shard.iter_torch_batches(
batch_size=config["batch_size"], device=train.torch.get_device()
)
for i, batch in enumerate(train_dataset_batches):
# get the inputs and labels
inputs, labels = batch["image"], batch["label"]
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(f"[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}")
running_loss = 0.0
metrics = dict(running_loss=running_loss)
checkpoint = TorchCheckpoint.from_state_dict(model.state_dict())
session.report(metrics, checkpoint=checkpoint)为了提高模型的准确性,还将定义一个预处理器来对图像进行归一化处理。
from ray.data.preprocessors import TorchVisionPreprocessor
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
preprocessor = TorchVisionPreprocessor(columns=["image"], transform=transform)最后,训练模型。这应该需要几分钟的时间来运行。如果有可用的 GPU,将使用它们。
from ray.train.torch import TorchTrainer
from ray.air.config import ScalingConfig
use_gpu = ray.available_resources().get("GPU", 0) >= 2
# 是检查当前可用的 GPU 资源数量是否大于等于2。如果是这样,那么将 use_gpu 设置为 True,否则设置为 False。
trainer = TorchTrainer(
# 在train_loop_per_worker中for epoch in range(2):说明只进行了2iters的迭代训练
train_loop_per_worker=train_loop_per_worker,
train_loop_config={"batch_size": 20}, # train_loop_config={"batch_size": 2},
datasets={"train": train_dataset},
scaling_config=ScalingConfig(num_workers=1, use_gpu=True), # scaling_config=ScalingConfig(num_workers=2, use_gpu=use_gpu),
preprocessor=preprocessor
)
result = trainer.fit()
latest_checkpoint = result.checkpoint训练过程中,Ray显示的Status为
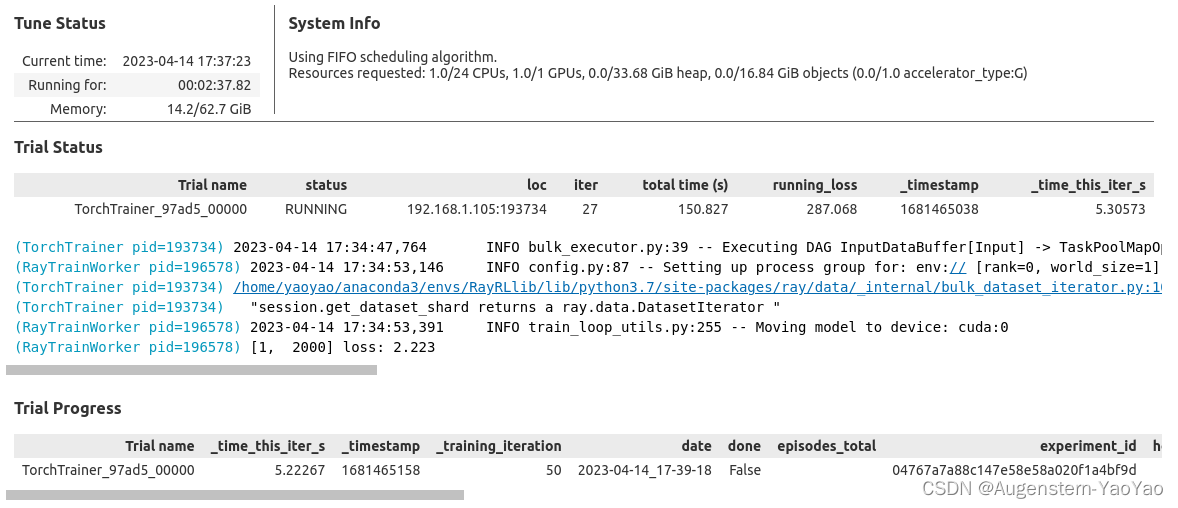
并不断输出loss。
要扩展训练脚本,请创建一个 Ray 集群并增加工作节点的数量。如果您的集群包含 GPU,请在扩展配置中添加 "use_gpu": True。
scaling_config=ScalingConfig(num_workers=1, use_gpu=True)在测试数据上测试网络
要对测试数据集中的图像进行分类,需要创建一个预测器。
预测器从检查点加载数据并有效地执行推理。与 TorchPredictor 不同,后者在单个批次上执行推理,BatchPredictor 在整个数据集上执行推理。因为想要对测试数据集中的所有图像进行分类,将使用 BatchPredictor。如果想为批量预测使用 GPU,请在 BatchPredictor 的 predict 调用中指定 num_gpus_per_worker=1。
from ray.train.torch import TorchPredictor
from ray.train.batch_predictor import BatchPredictor
batch_predictor = BatchPredictor.from_checkpoint(
checkpoint=latest_checkpoint,
predictor_cls=TorchPredictor,
model=Net(),
)
outputs: ray.data.Dataset = batch_predictor.predict(
data=test_dataset,
dtype=torch.float,
feature_columns=["image"],
keep_columns=["label"],
# We will use GPU if available.
num_gpus_per_worker=ray.available_resources().get("GPU", 0)
)模型为每个类输出一个能量列表(类似于预测概率)。为了对图像进行分类,选择具有最高能量的类别。
import numpy as np
def convert_logits_to_classes(df):
best_class = df["predictions"].map(lambda x: x.argmax())
df["prediction"] = best_class
return df[["prediction", "label"]]
predictions = outputs.map_batches(convert_logits_to_classes)
predictions.show(1)预测输出为
2023-04-14 17:39:27,745 INFO bulk_executor.py:39 -- Executing DAG InputDataBuffer[Input] -> TaskPoolMapOperator[MapBatches(convert_logits_to_classes)]
MapBatches(convert_logits_to_classes): 100%|██████████| 3/3 [00:00<00:00, 161.48it/s]
{'prediction': 3, 'label': 3}现在已经对所有图像进行了分类,让找出哪些图像被正确分类。
预测数据集包含预测标签,而 test_dataset 包含真实标签。
要判断一张图像是否被正确分类,将两个数据集连接起来,然后检查预测标签是否与实际标签相同。
def calculate_prediction_scores(df):
df["correct"] = df["prediction"] == df["label"]
return df
scores = predictions.map_batches(calculate_prediction_scores)
scores.show(1)结果为
2023-04-14 17:39:27,812 INFO bulk_executor.py:39 -- Executing DAG InputDataBuffer[Input] -> TaskPoolMapOperator[MapBatches(calculate_prediction_scores)]
MapBatches(calculate_prediction_scores): 100%|██████████| 3/3 [00:00<00:00, 259.09it/s]
{'prediction': 3, 'label': 3, 'correct': True}为了计算测试准确率,将统计模型正确分类的图像数量,并将该数字除以测试图像的总数。
scores.sum(on="correct") / scores.count()此处精度大约在55%左右。
部署网络并进行预测
模型似乎表现得相当不错,所以让将模型部署到一个端点。这使能够通过互联网进行预测。
此处需要pip安装ray[serve]
from ray import serve
from ray.serve import PredictorDeployment
from ray.serve.http_adapters import json_to_ndarray
serve.run(
PredictorDeployment.bind(
TorchPredictor,
latest_checkpoint,
model=Net(),
http_adapter=json_to_ndarray,
)
)对一个测试图像进行分类测试。
image = test_dataset.take(1)[0]["image"]可以通过发布带有 "array" 键的字典来对已部署的模型执行推理。要了解更多关于默认输入架构的信息,请阅读 NdArray 文档。
import requests
payload = {"array": image.tolist(), "dtype": "float32"}
response = requests.post("http://localhost:8000/", json=payload)
response.json()预测能量结果为
{'predictions': [1023.8524780273438,
-1718.113525390625,
432.2010498046875,
1739.6827392578125,
-2233.837158203125,
1039.4508056640625,
181.28628540039062,
-827.2855834960938,
1588.256591796875,
198.23077392578125]}