Ray是UC Berkeley RISELab新推出的高性能分布式执行框架,它使用了和传统分布式计算系统不一样的架构和对分布式计算的抽象方式,具有比Spark更优异的计算性能。
Ray目前还处于实验室阶段,最新版本为0.5版本。虽然Ray自称是面向AI应用的分布式计算框架,但是它的架构具有通用的分布式计算抽象。本文对Ray进行简单的介绍.
Ray是一个分布式执行引擎。可以在单个机器上运行相同的代码以实现高效的多处理,并且可以在群集上使用它来进行大型计算。
Ray现在已经可是在Linux和MacOS系统上运行,暂不支持window。和TensorFlow和pytorch完美兼容。
一、简单使用
安装 pip install ray
1.**ray.init()**启动ray
本地启动
#导入ray包
import ray
ray.init()
结果
Process STDOUT and STDERR is being redirected to /tmp/raylogs/.
Waiting for redis server at 127.0.0.1:49354 to respond...
Waiting for redis server at 127.0.0.1:19872 to respond...
Starting the Plasma object store with 1.00 GB memory.
Starting local scheduler with the following resources: {'CPU': 4, 'GPU': 0}.
======================================================================
View the web UI at http://localhost:8888/notebooks/ray_ui262.ipynb?token=bfb2256187326e3c70de1d009fa3391d9c2e8aa1fc6eac45
======================================================================
注:如果在ray.init()这一步报错如下
注:如果在ray.init()这一步报错如下

redis.exception.DataError:错。
是因为redis最新版本的和ray不兼容,只需把对应的版本降低即可。
如。
pip install -U redis==2.10.6
链接集群
import ray
ray.init(redis_address="地址")
2.ray.put() 对python不同函数或值等放入ray内存库中,ray.put() 返回id
def h():
return 4+10
h_id = ray.put(h())
print(ray.get(h_id))
结果
14
h()通过ray.put()放入ray库中,h_id即为其ray中id。通过ray.get()获取其真是值
3 ,**ray.get()**通过id获取对应的值
x_id = ray.put("example")
x1=ray.get(x_id)
print(x1)
结果
example
4 @ray.remote 给函数放入存储地址。也是定义actor的必要标志
Ray中调用remote函数的关键流程如下:
1.调用remote函数时,首先会创建一个任务对象,它包含了函数的ID、参数的ID或者值(Python的基本对象直接传值,复杂对象会先通过ray.put()操作存入ObjectStore然后返回ID)、函数返回值对象的ID。
2.任务对象被发送到本地调度器。
3.本地调度器决定任务对象是在本地调度还是发送给全局调度器。如果任务对象的依赖(参数)在本地的ObejctStore已经存在且本地的CPU和GPU计算资源充足,那么本地调度器将任务分配给本地的WorkerProcess执行。否则,任务对象被发送给全局调度器并存储到任务表(TaskTable)中,全局调度器根据当前的任务状态信息决定将任务发给集群中的某一个本地调度器。
4.本地调度器收到任务对象后(来自本地的任务或者全局调度分配的任务),会将其放入一个任务队列中,等待计算资源和本地依赖满足后分配给WorkerProcess执行。
5.Worker收到任务对象后执行该任务,并将函数返回值存入ObjectStore,并更新Master的对象表(ObjectTable)信息。
注意:@ray.remote定义过得类或者函数只能调用此函数前边的未定义@ray.remote的函数。
@ray.remote
def A():
return 10
@ray.remote
def B():
return 20
@ray.remote
def C(a,b):
return a+b
a_id = A.remote()
b_id = B.remote()
c_id = C.remote(a_id,b_id)
print(ray.get(c_id))
结果
30
#actor
@ray.remote
class Counter(object):
def __init__(self):
self.value = 0
def increment(self):
self.value += 1
return self.value
a1 = Counter.remote()
print(ray.get(a1.increment.remote()))
print(ray.get(a1.increment.remote()))
a = [a1.increment.remote() for i in range(4)]
print(ray.get(a))
结果
1
2
[3, 4, 5, 6]
调用Actor对象的方法的流程为:
首先创建一个任务。
该任务被Driver直接分配到创建该Actor对应的本地执行器执行,这个操作绕开了全局调度器(Worker是否也可以使用Actor直接分配任务尚存疑问)。
返回Actor方法调用结果的ObjectID。
为了保证Actor状态的一致性,对同一个Actor的方法调用是串行执行的。
5.ray.wait()操作支持批量的任务等待,基于此可以实现一次性获取多个ID对应的数据。
@ray.remote
def f():
import time
time.sleep(3)
return 10
results = [f.remote() for i in range(4)]
# 阻塞等待3个任务完成,超时时间为2.5s
ready_ids, remaining_ids = ray.wait(results, num_returns=3, timeout=2500)
print(ray.get(ready_ids))
print(ray.get(remaining_ids))
results2 = [f.remote() for i in range(4)]
# 阻塞等待3个任务完成,超时时间为5s
ready2_ids, remaining2_ids = ray.wait(results2, num_returns=3, timeout=5000)
print(ray.get(ready2_ids))
print(ray.get(remaining2_ids))
结果
[]
[10, 10, 10, 10]
[10, 10, 10]
[10]
结果说明:f.remote()是并行的。
第一个for循环因为超时,所以ready_ids为空,然后程序等呆运行结束把最后的结果全部给remaining_ids。
第二个for循环因为平行的原因,没有超时,所示ready2_ids有三个值ID,remaining2_ids有一个值ID。
注意:若是点个人电脑运行此程序电脑核心必须大于等于四核。本人电脑四核,故有如下情况。
@ray.remote
def f():
import time
time.sleep(3)
return 10
results2 = [f.remote() for i in range(6)]
# 阻塞等待5个任务完成,超时时间为5s
ready2_ids, remaining2_ids = ray.wait(results2, num_returns=5, timeout=5000)
print(ray.get(ready2_ids))
print(ray.get(remaining2_ids))
结果:
[10, 10, 10, 10]
[10, 10]
每次只能处理四个,过5秒只能执行四个,故ready2_ids有四个值ID,remaining2_ids有两个值ID。
二、系统框架
API其中的futures其实就是对象ID
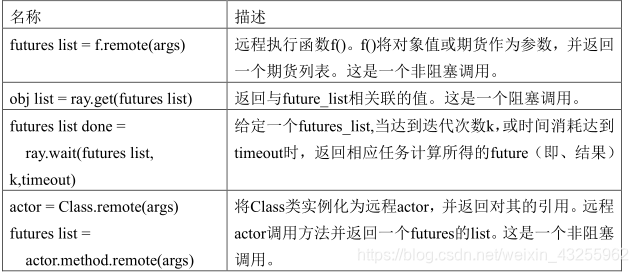
作为分布式计算系统,Ray仍旧遵循了典型的Master-Slave的设计:Master负责全局协调和状态维护,Slave执行分布式计算任务。不过和传统的分布式计算系统不同的是,Ray使用了混合任务调度的思路。在集群部署模式下,Ray启动了以下关键组件:
GlobalScheduler:Master上启动了一个全局调度器,用于接收本地调度器提交的任务,并将任务分发给合适的本地任务调度器执行。
RedisServer:Master上启动了一到多个RedisServer用于保存分布式任务的状态信息(ControlState),包括对象机器的映射、任务描述、任务debug信息等。
LocalScheduler:每个Slave上启动了一个本地调度器,用于提交任务到全局调度器,以及分配任务给当前机器的Worker进程。
Worker:每个Slave上可以启动多个Worker进程执行分布式任务,并将计算结果存储到ObjectStore。
ObjectStore:每个Slave上启动了一个ObjectStore存储只读数据对象,Worker可以通过共享内存的方式访问这些对象数据,这样可以有效地减少内存拷贝和对象序列化成本。ObjectStore底层由Apache Arrow实现。
Plasma:每个Slave上的ObjectStore都由一个名为Plasma的对象管理器进行管理,它可以在Worker访问本地ObjectStore上不存在的远程数据对象时,主动拉取其它Slave上的对象数据到当前机器。
需要说明的是,Ray的论文中提及,全局调度器可以启动一到多个,而目前Ray的实现文档里讨论的内容都是基于一个全局调度器的情况。我猜测可能是Ray尚在建设中,一些机制还未完善,后续读者可以留意此处的细节变化。
Ray的任务也是通过类似Spark中Driver的概念的方式进行提交的,有所不同的是:
1.Spark的Driver提交的是任务DAG(有向图),一旦提交则不可更改。
2.而Ray提交的是更细粒度的remote function,任务DAG依赖关系由函数依赖关系自由定制。

Ray的Driver节点和和Slave节点启动的组件几乎相同,不过却有以下区别:
Driver上的工作进程DriverProcess一般只有一个,即用户启动的PythonShell。Slave可以根据需要创建多个WorkerProcess。
Driver只能提交任务,却不能接收来自全局调度器分配的任务。Slave可以提交任务,也可以接收全局调度器分配的任务。
Driver可以主动绕过全局调度器给Slave发送Actor调用任务(此处设计是否合理尚不讨论)。Slave只能接收全局调度器分配的计算任务。
举例解释运行流程
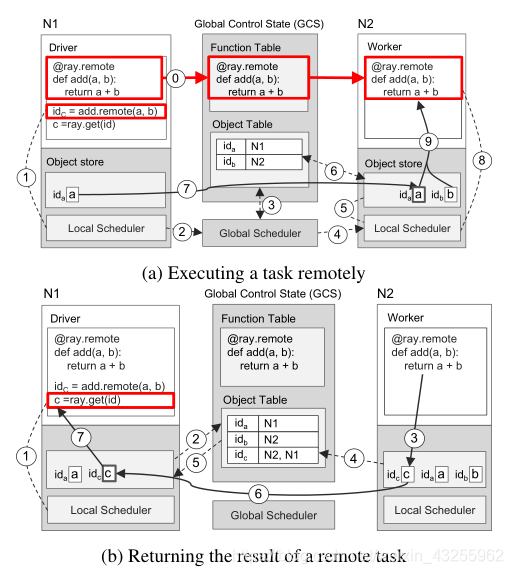
如上图函数
@ray.remote
def add(a,b):
return a+b
a = 1
b = 2
idc = add.remote(a,b)
c = ray.get(idc)
图(a)显示了调用add.remote(a,b)的分步操作,a和b存储在节点N1和N2上。驱动程序将add(a, b)提交给本地调度程序(步骤1),后者将其转发给全局调度程序(步骤2). 然后,全局调度器查找GCS(步骤3)中add(a, b)参数的位置,并决定在节点N2上调度任务,节点N2存储参数b(步骤4)。节点N2的本地调度程序(Local Scheduler)检查本地的对象存储是否包含add(a, b)的输入输出参数(步骤5)。由于本地存储并没有存储对象a,所以它会在GCS中检索a的存储位置(步骤6)。找到到a存储在N1, N2的对象存储在本地复制(步骤7)。由于add()的所有出入参数已经都存储在本地,因此本地调度程序会调用本地worker(步骤8)上的add(),该worker通过共享内存访问这些参数(步骤9)。
图(b)显示了在N1处执行ray.get()和在N2处执行add()所触发的分步操作。在ray.get(idc )调用时,驱动程序使用add()(步骤1)返回的未来idc ,检查本地对象存储库中的值c。由于本地对象存储库不存储c,所以它在GCS中检索存储位置。此时,c没有条目,因为c还没有创建。因此,N1的对象存储用创建c项时将触发的对象表注册一个回调(步骤2)。同时,在N2时,add()完成它的执行,将结果c存储在本地对象存储中(步骤3),从而将c的条目添加到GCS(步骤4)。因此,GCS触发回调N1的对象存储与c的条目(步骤5)。接下来,N1从N2复制c(步骤6),并返回c到ray.get()(步骤7),这最终完成了任务。
现状
Ray从一年多前发布到现在,现状是API层以上的部分还比较薄弱,Core模块核心逻辑估计也需要时间打磨。这仅从项目的代码量大致就可以看出来了,目标如此宏伟的系统,主要模块目前一共也就两百多个python文件和不到一百个C++文件。
当然,Ray在核心Core模块以上,也开始构建类似Ray RLLib这样的针对增强学习训练算法的上层Library。不过目前看来这些library也是非常基本的概念实现,代码量都不大。当然,也有可能是Core模块足够强大,上层算法策略并不需要写太多代码。不过,不管怎么说,这块显然也是处于早期阶段,需要实践检验和打磨,毕竟,能用和好用,中间还有很长的路。类比Spark中图计算框架的实现,用于实现pregel的几行代码显然和后面的graphx没法同日而语。
至于其它的ML/SQL/Stream/Graph之类的实现,暂时没有看到,理论上Ray目标定位的“灵活的”编程模型,也是可以用来实现这些更高层的编程语义模型的。但实际上,目前现状一方面的原因可能是为时尚早,Ray还没有来得及拓展到这些领域,另一方面,相对于其它计算框架,Ray在这些领域可能也未必有优势。相反的由于Ray的分层调度模型和数据向代码移动的计算模型所带来的全局任务的优化难度,在任务拓扑逻辑图相对固定的场景下,Ray的整体计算性能效率很可能长远来说,也并不如当前这些主流的计算框架。
所以Ray能否成长成为一个足够通用的计算框架,目前我觉得还无法判断,但如果你需要标准化,模式化的解决大量类似增强学习的这种流程复杂的大规模分布式计算问题,那么Ray至少是一种有益的补充,可能值得关注一下,将它和TensorFlow等框架进行局部的结合,让Ray来关注和整合计算处理流程,让其它系统解决各自擅长的问题,可能也是短期内可行的应用方式,Ray自己目前貌似也是朝着这个所谓的混合计算的方向前进的。
参考文献:1.范志东 高性能分布式执行框架——Ray https://www.cnblogs.com/fanzhidongyzby/p/7901139.htm
2.官网 https://ray.readthedocs.io/en/latest/installation.html
3 .https://blog.csdn.net/colorant/article/details/80417412