分别使用SAC/DDPG/Apex-DDPG训练强化学习环境Pendulum-v1。
1.Pendulum-v1环境
在Pendulum-v1环境中,智能体的目标是平衡一个倒置的摆。奖励函数基于摆的角度、角速度和所采取的动作。
奖励函数:reward = -(theta^2 + 0.1 * theta_dt^2 + 0.001 * action^2)
其中,theta是摆离垂直向上位置的角度(以弧度为单位),theta_dt是角速度,action是智能体所采取的动作。
奖励函数中的所有项都是负数,这意味着获得更高的奖励实际上是在最小化这些惩罚。理论上,最佳平均奖励应该在摆保持完全垂直(theta接近0)且所采取的动作很小(action接近0)的情况下获得。在这种情况下,奖励函数会接近于0。在实践中,最佳平均奖励可能会略低于0。
算法Baseline
rl-baselines3-zoo中给出了Pendulum-v1等环境的训练结果Baseline
| algo |
a2c | ars | ddpg | ppo | sac | td3 | trpo |
| env_id |
Pendulum-v1 | ||||||
| mean_reward |
-162.965 | -212.540 | -152.099 | -172.225 | -156.995 | -151.855 | -174.631 |
| std_reward
扫描二维码关注公众号,回复:
15295387 查看本文章

|
103.210 | 160.444 | 94.282 | 104.159 | 88.714 | 90.227 | 127.577 |
| n_timesteps |
1M | 2M | 20k | 100k | 20k | 20k | 100k |
| eval_timesteps |
150000 | ||||||
| eval_episodes |
750 | ||||||
Ray RLlib tuned 配置文件给出了不同算法与超参数及其对应的rewards
- Apex-DDPG: -160 reward within 2.5 timesteps / ~250 seconds on a K40 GPU
- SAC: -150+ reward in 6-7k
- DDPG: -160 reward in 10k-20k timesteps
尽管 Apex-DDPG 需要更少的时间步数,但这并不意味着它在实际运行速度上一定快于 SAC。实际运行速度取决于许多因素,如算法的计算复杂性、处理能力、硬件资源等。另外,这两个算法的目标和设计原则不同。Apex-DDPG 关注于分布式计算和经验回放,以提高 DDPG 的性能。而 SAC 通过最大化策略的熵来提高探索性能。因此,在选择算法时,需要根据具体任务和需求进行权衡,而非仅根据时间步长来决定。
2.计算环境
基于Ray RLlib配置Anaconda中的运行环境RayRLlib。
conda create -n RayRLlib python=3.8
conda activate RayRLlib
conda install jupyter
pip install pyarrow pandas gputil tqdm pyyaml -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install distro>=1.4.0
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install --upgrade tensorflow tensorflow-probability -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "ray[rllib]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -U "ray[tune]"
pip install gymnasium[atari] gym==0.26.2
pip install gym[accept-rom-license]
pip install "beautifulsoup4==4.11.1"
pip install xgboost_ray -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install gymnasium[box2d] -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install docutils
pip install --upgrade gymnasium[all] -i https://pypi.tuna.tsinghua.edu.cn/simple Ray 默认使用pytorch作为计算后端,Pendulum-v1为gymnasium库(而非gym库)中的环境。虽然gymnasium库与gym库众多环境是相似的,但是API并不相同,Ray支持的是gymnasium库环境。
3.基于.yaml配置文件的SAC/DDPG/Apex-DDPG训练
Ray RLlib主要有CLI(命令行)与Python API调用等方式。本小节使用CLI分别调用SAC/DDPG/Apex-DDPG进行训练,并给出训练结果。
下列三种算法均能够在几分钟内收敛,并使用了10个CPU计算核心并行收集经验数据以提高运行速度。
1)CLI调用SAC的.yaml配置
RayRLlib终端中运行:
rllib train file pendulum-sac.yaml -v #rllib train file /path/to/tuned/example.yaml其中, pendulum-sac.yaml内容为
# Linik: https://github.com/ray-project/ray/blob/master/rllib/tuned_examples/sac/pendulum-sac.yaml
# Pendulum SAC can attain -150+ reward in 6-7k
# Configurations are the similar to original softlearning/sac codebase
pendulum-sac:
env: Pendulum-v1
run: SAC
stop:
# episode_reward_mean: -250
# timesteps_total: 10000
episode_reward_mean: 0
timesteps_total: 1000_000
config:
# Works for both torch and tf.
framework: torch
q_model_config:
fcnet_activation: relu
fcnet_hiddens: [256, 256]
policy_model_config:
fcnet_activation: relu
fcnet_hiddens: [256, 256]
tau: 0.005
target_entropy: auto
n_step: 1
rollout_fragment_length: 1
train_batch_size: 256
target_network_update_freq: 1
min_sample_timesteps_per_iteration: 1000
replay_buffer_config:
type: MultiAgentPrioritizedReplayBuffer
num_steps_sampled_before_learning_starts: 256
optimization:
actor_learning_rate: 0.0003
critic_learning_rate: 0.0003
entropy_learning_rate: 0.0003
# num_workers: 0
num_workers: 10
num_gpus: 0
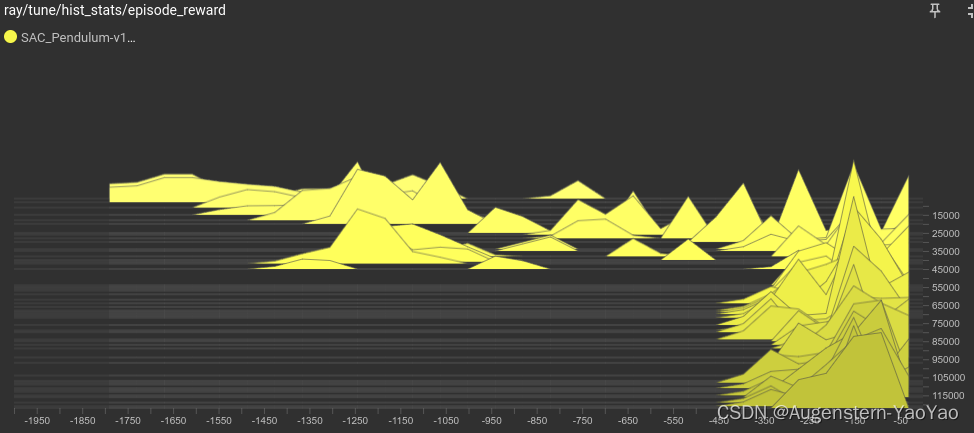
metrics_num_episodes_for_smoothing: 5使用了10 workers并行计算,训练结果:

 2)CLI调用DDPG的.yaml配置
2)CLI调用DDPG的.yaml配置
RayRLlib终端中运行:
rllib train file pendulum-ddpg.yaml -v其中, pendulum-ddpg.yaml内容为
# Link:https://github.com/ray-project/ray/blob/master/rllib/tuned_examples/ddpg/pendulum-ddpg.yaml
# This configuration can expect to reach -160 reward in 10k-20k timesteps.
pendulum-ddpg:
env: Pendulum-v1
run: DDPG
stop:
# episode_reward_mean: -320
# timesteps_total: 30000
episode_reward_mean: 0
timesteps_total: 1000_000
config:
# Works for both torch and tf.
seed: 42
framework: torch
# === Model ===
#actor_hiddens: [64, 64]
#critic_hiddens: [64, 64]
actor_hiddens: [256, 256]
critic_hiddens: [256, 256]
n_step: 1
model: {}
gamma: 0.99
# === Exploration ===
exploration_config:
type: "OrnsteinUhlenbeckNoise"
scale_timesteps: 10000
initial_scale: 1.0
final_scale: 0.02
ou_base_scale: 0.1
ou_theta: 0.15
ou_sigma: 0.2
min_sample_timesteps_per_iteration: 600
target_network_update_freq: 0
tau: 0.001
# === Replay buffer ===
replay_buffer_config:
type: MultiAgentPrioritizedReplayBuffer
capacity: 10000
worker_side_prioritization: false
num_steps_sampled_before_learning_starts: 500
clip_rewards: False
# === Optimization ===
actor_lr: 0.001
critic_lr: 0.001
use_huber: True
huber_threshold: 1.0
l2_reg: 0.000001
rollout_fragment_length: 1
# train_batch_size: 64
train_batch_size: 256
# === Parallelism ===
# num_workers: 0
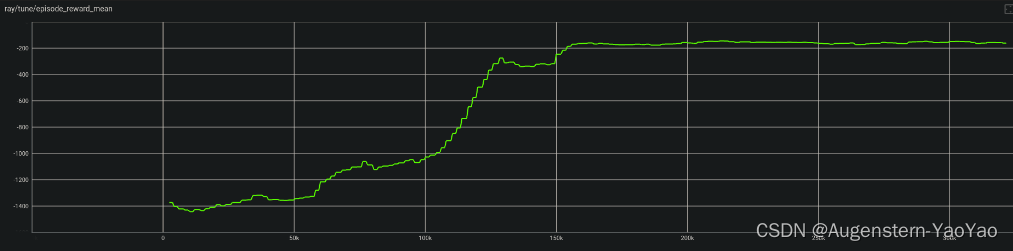
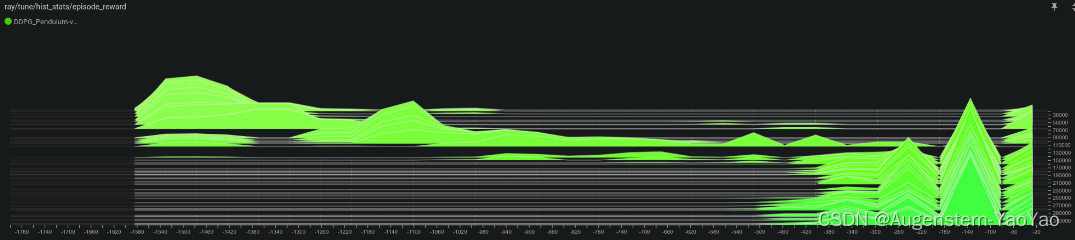
num_workers: 10使用了10 workers并行计算,训练结果:
 3)CLI调用Apex-DDPG的.yaml配置
3)CLI调用Apex-DDPG的.yaml配置
RayRLlib终端中运行:
rllib train file pendulum-apex-ddpg.yaml -v其中, pendulum-apex-ddpg.yaml内容为
# Link:https://github.com/ray-project/ray/blob/master/rllib/tuned_examples/apex_ddpg/pendulum-apex-ddpg.yaml
# This can be expected to reach -160 reward within 2.5 timesteps / ~250 seconds on a K40 GPU
pendulum-apex-ddpg:
env: Pendulum-v1
run: APEX_DDPG
stop:
# episode_reward_mean: -160
episode_reward_mean: 0
config:
# Works for both torch and tf.
framework: torch
use_huber: True
clip_rewards: False
# num_workers: 16
num_workers: 10
n_step: 1
target_network_update_freq: 50000
tau: 1.0
evaluation_interval: 5
evaluation_duration: 10
使用了10 workers并行计算,训练结果:


4.使用RayRLlib python API编写Apex-DDPG求解器
Ape-X的DQN和DDPG变体(APEX_DQN、APEX_DDPG)使用单个GPU学习器和多个CPU工作者进行经验收集。Ape-X使用了一种被称为“prioritized experience replay”的技术,该技术优先存储具有较高优先级的经验数据。在这种技术中,每个CPU工作者都负责收集经验数据,并计算每个经验数据的优先级。然后,所有CPU工作者都将它们的经验数据发送到一个中央存储库(回放缓冲区),并且根据经验数据的优先级进行排序。这使得经验数据可以更有效地重复利用,以提高算法的训练效率。因为经验收集和排序是在多个CPU工作者之间分布式完成的,所以Ape-X的DQN和DDPG变体可以扩展到数百个CPU工作者,而不会因为存储瓶颈或性能问题而受到限制。这使得算法可以从更多的环境中收集更多的经验数据,从而提高训练效率和性能。

超参数:
| 部分超参数 | ||||||
| use_huber |
clip_rewards |
num_workers |
n_step |
tau |
evaluation interval |
evaluation duration |
| True |
False |
10 | 1 | 1 | 5 | 10 |
使用RayRLlib python API编写Apex-DDPG求解器的python代码:
from ray.rllib.algorithms.apex_ddpg.apex_ddpg import ApexDDPGConfig
from ray.tune.logger import pretty_print
# 参考:https://docs.ray.io/en/latest/rllib/rllib-algorithms.html#apex:~:text=algorithms.apex_dqn.apex_dqn%20import%20ApexDQNConfig%0A%3E%3E%3E-,config%20%3D%20ApexDQNConfig(),-%3E%3E%3E%20print(config.replay_buffer_config
config = ApexDDPGConfig()
config = (
ApexDDPGConfig()
# torch框架与Gym环境
.framework("torch")
.environment("Pendulum-v1")
# 神经网络学习参数
.training(tau=1.0,use_huber=True,n_step=1,target_network_update_freq=50000)
# 计算资源参数
# num_rollout_workers并行计算总CPU资源数,可取10
.rollouts(num_rollout_workers=20)
# num_envs_per_worker每个worker内运行的环境数,可取10
.rollouts(num_envs_per_worker=10)
# num_gpus可用GPU数量,可取1
.resources(num_gpus=1)
# num_trainer_workers总worker数,可取10
.resources(num_trainer_workers=18)
)
#config.replay_buffer_config["no_local_replay_buffer"] = 'False' # 内存空间换计算时间,可能OOM(iters=10时,内存占用30G+)
config.replay_buffer_config["capacity"] = 50_000_000 # 500_000_000需要占用9.75GBx4的内存
config["evaluation_interval"] = 5
config["evaluation_duration"] = 10
config["clip_rewards"] = False
# 输出config
print(config.to_dict())
# 建构algo
algo = config.build()
# 训练Agent
for iters in range(1,21):
result = algo.train()
#print(pretty_print(result))
print("\n当前迭代次数: {}".format(iters))
print("平均reward: {}".format(result['episode_reward_mean']))
print("最大reward: {}".format(result['episode_reward_max']))
print("最小reward: {}".format(result['episode_reward_min']))
# 储存checkpoints
if iters % 10 == 0:
checkpoint_dir = algo.save()
print(f"Checkpoint saved in directory {checkpoint_dir}")运行上述代码,10iters即可获得-145的episode_reward_mean。
Tips: no_local_replay_buffer = True
在分布式强化学习训练中,no_local_replay_buffer是一个布尔配置选项,表示是否禁用本地回放缓冲区。当其设置为True时,意味着不会在本地训练器(即驱动程序节点上的训练器)上使用一个单独的回放缓冲区。相反,训练器将直接从远程工作器的回放缓冲区中采样数据。
在某些分布式RL算法(如 APEX-DQN 和 APEX-DDPG)中,这个选项被设置为True,以减少本地训练器的内存消耗。因为在这些算法中,训练器主要负责更新模型参数并将更新后的参数分发给远程工作器,而远程工作器负责收集经验并存储在它们各自的回放缓冲区中。因此,本地训练器不需要维护一个额外的回放缓冲区,可以节省内存。然而,这种设置可能会导致训练速度减慢,因为训练器需要从远程工作器那里获取数据。
5.使用外部通信方式的Apex-DDPG算法求解
参考原代码为cartpole环境,输出控制为离散量。现改为基于Apex-DDPG的连续动作控制器。
Server端程序(my_pendulum_server.py)
#!/usr/bin/env python
import argparse
import gymnasium as gym
import os
import numpy as np
import ray
from ray import air, tune
from ray.rllib.env.policy_server_input import PolicyServerInput
from ray.rllib.examples.custom_metrics_and_callbacks import MyCallbacks
from ray.tune.logger import pretty_print
from ray.tune.registry import get_trainable_cls
from ray.rllib.algorithms.apex_ddpg.apex_ddpg import ApexDDPGConfig
SERVER_ADDRESS = "localhost"
SERVER_BASE_PORT = 9900 # + worker-idx - 1
CHECKPOINT_FILE = "last_checkpoint_{}.out"
def get_cli_args():
"""Create CLI parser and return parsed arguments"""
parser = argparse.ArgumentParser()
parser.add_argument(
"--port",
type=int,
default=SERVER_BASE_PORT,
help="The base-port to use (on localhost). " f"Default is {SERVER_BASE_PORT}.",
)
parser.add_argument(
"--num-workers",
type=int,
default=2,
)
parser.add_argument(
"--stop-iters", type=int, default=200, help="Number of iterations to train."
)
parser.add_argument(
"--stop-timesteps",
type=int,
default=50_000_000,
)
parser.add_argument(
"--stop-reward",
type=float,
default=0,
)
args = parser.parse_args()
print(f"Running with following CLI args: {args}")
return args
if __name__ == "__main__":
args = get_cli_args()
ray.init()
# `InputReader` generator (returns None if no input reader is needed on
# the respective worker).
def _input(ioctx):
# We are remote worker or we are local worker with num_workers=0:
# Create a PolicyServerInput.
if ioctx.worker_index > 0 or ioctx.worker.num_workers == 0:
return PolicyServerInput(
ioctx,
SERVER_ADDRESS,
args.port + ioctx.worker_index - (1 if ioctx.worker_index > 0 else 0),
)
else:
return None
config = (
ApexDDPGConfig()
.environment(
env=None,
observation_space=gym.spaces.Box(float("-inf"), float("inf"), shape=(3,)),
action_space=gym.spaces.Box(low=np.array([-2.0,]), high=np.array([2.0,]), shape=(1,)),
# action_space=gym.spaces.Discrete(2),
# see: https://www.gymlibrary.dev/api/spaces/#:~:text=Box(low%3Dnp.array(%5B%2D1.0%2C%20%2D2.0%5D)%2C%20high%3Dnp.array(%5B2.0%2C%204.0%5D)%2C%20dtype%3Dnp.float32)%0ABox(2%2C)
)
.framework("torch")
.offline_data(input_=_input)
.rollouts(
num_rollout_workers=args.num_workers,
enable_connectors=False,
)
# num_gpus -- number of GPU
.resources(num_gpus=1)
# num_trainer_workers -- total number of workers
.resources(num_trainer_workers=20)
.evaluation(off_policy_estimation_methods={})
.debugging(log_level="WARN")
.training(tau=1.0, use_huber=True, n_step=1, target_network_update_freq=50000)
)
config.replay_buffer_config["capacity"] = 50_000_000 # 500_000_000 occupies 9.75GBx4 memory
config["clip_rewards"] = False
stop = {
"training_iteration": args.stop_iters,
"timesteps_total": args.stop_timesteps,
"episode_reward_mean": args.stop_reward,
}
checkpoint_config = air.CheckpointConfig(checkpoint_frequency=5,checkpoint_at_end=True)
tune.Tuner(
"APEX_DDPG",
param_space=config,
run_config=air.RunConfig(stop=stop, \
verbose=0, \
checkpoint_config=checkpoint_config, \
local_dir=".../Checkpoints")
).fit()Clients端程序(my_pendulum_client.py)
#!/usr/bin/env python
import argparse
import gymnasium as gym
from ray.rllib.env.policy_client import PolicyClient
import random
parser = argparse.ArgumentParser()
parser.add_argument(
"--no-train", action="store_true", help="Whether to disable training."
)
parser.add_argument(
"--inference-mode", type=str, default="local", choices=["local", "remote"]
)
parser.add_argument(
"--stop-reward",
type=float,
default=0,
help="Stop once the specified reward is reached.",
)
parser.add_argument(
"--port", type=int, default=9900, help="The port to use (on localhost)."
)
if __name__ == "__main__":
args = parser.parse_args()
env = gym.make("Pendulum-v1")
client = PolicyClient(
f"http://localhost:{args.port}", inference_mode=args.inference_mode
)
# Start a new episode.
obs, info = env.reset()
eid = client.start_episode(training_enabled=not args.no_train)
rewards = 0.0
while True:
action = client.get_action(eid, obs)
# Perform a step in the external simulator (env).
obs, reward, terminated, truncated, info = env.step(action)
rewards += reward
# Log next-obs, rewards, and infos.
client.log_returns(eid, reward, info=info)
# Reset the episode if done.
if terminated or truncated:
if random.random() < 0.1: # 10% prob log sampling
print("Total reward:", rewards)
if rewards >= args.stop_reward:
print("Target reward achieved, exiting")
exit(0)
rewards = 0.0
# End the old episode.
client.end_episode(eid, obs)
# Start a new episode.
obs, info = env.reset()
eid = client.start_episode(training_enabled=not args.no_train)分别在不同终端中启动:
1)Server端程序:终端1
conda activate rayrllib
python my_pendulum_server.py --num-workers 10 --stop-iters 50 --stop-reward -1502.1)Clients端程序启动方式1:终端启动
终端2(单线程,只使用了HTTP port: 9900)
conda activate rayrllib
python my_pendulum_client.py --inference-mode=local --port 9900或改为多线程/多进程启动:
2.2)Clients端程序启动方式2:多进程启动
import subprocess
import os
port_start = 9900
port_end = 9905
script_path = "my_pendulum_client.py"
inference_mode = "local"
processes = []
for port in range(port_start, port_end + 1):
cmd = f"python {script_path} --inference-mode={inference_mode} --port {port}"
process = subprocess.Popen(cmd, shell=True)
processes.append(process)
for process in processes:
process.wait()计算20min的效果:

2.3)Clients端程序启动方式3:多线程启动
# 多线程启动client:
import subprocess
import os
from concurrent.futures import ThreadPoolExecutor
port_start = 9900
port_end = 9905
script_path = "my_pendulum_client.py"
inference_mode = "local"
def start_client(port):
cmd = f"python {script_path} --inference-mode={inference_mode} --port {port}"
process = subprocess.Popen(cmd, shell=True)
process.wait()
with ThreadPoolExecutor() as executor:
ports = range(port_start, port_end + 1)
executor.map(start_client, ports)
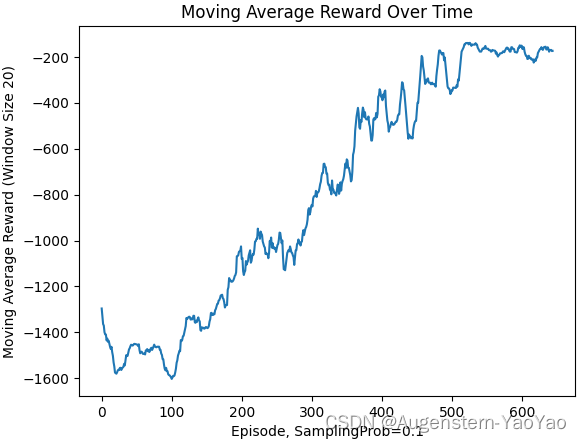
计算20min的效果:
6.总结
分别完成了以下各配置的Pendulum-v1环境的求解:
- 基于SAC算法,通过CLI命令行调用.yaml预配置超参数文件,并行计算求解
- 基于DDPG算法,通过CLI命令行调用.yaml预配置超参数文件,并行计算求解
- 基于Apex-DDPG算法,通过CLI命令行调用.yaml预配置超参数文件,并行计算求解
- 基于Apex-DDPG算法,通过Ray RLlib python API配置超参数文件,并行计算求解
- 基于Apex-DDPG算法,通过Ray RLlib外部环境接口,以HTTP与环境clients通信,并行计算求解
均在10min内获得收敛的决策神经网络。